Integrate CRUD APIs with Amazon OpenSearch
 Asadullah Al Galib
Asadullah Al Galib
Photo by Kaleidico on Unsplash
We will pick it up from our previous post, Create a knowledge base using Amazon OpenSearch. In the previous post, we created the SAM template containing OpenSearch, API Gateway, and Lambda configuration for the CRUD APIs. In this post, we will add the implementation of all those APIs and finally deploy the stack to AWS. At the end of this tutorial, we will have a working knowledge base in our hands.
This post consists of three parts, outlined as follows:
Part 1: Explanation of the Lambda function configuration for each API in the template.yaml file.
Part 2: Implementation code for each of the Lambda functions.
Part 3: Deployment of the stack to AWS.
Let’s go! 🔥
Part 1:
Refer to the Previous post for the SAM configuration of APIs. E.g. here, we are going to take a look at the definition of Create Document API.
CreateDocumentFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: lambdas/
Handler: create_doc.lambda_handler
Role: !GetAtt CustomMainRole.Arn
Environment:
Variables:
OPEN_SEARCH_SECRET: !Ref OpenSearchSecret
OPEN_SEARCH_DOMAIN_ENDPOINT: !GetAtt OpenSearchServiceDomain.DomainEndpoint
Events:
PingRootEvent:
Type: Api
Properties:
Path: /{index_name}/kb-docs
Method: post
RestApiId: !Ref DefaultApi
So, what’s happening here? I will explain the most important parts.
CodeUri: This denotes the directory where the handler module is located for this Lambda function. In our case, it is the lambdas/ directory.
Handler: This tells which handler module and function to call when this Lambda is triggered. In our case, it is the function called lambda_handler inside create_doc.py module.
Environment: Here we pass the environment variables that we would like to access from within our handler module, i.e. create_doc.py
Type: This says for which event this Lambda will be triggered. In our case, we want to run this Lambda when an API endpoint is hit, so the value is set to Api.
Path: This denotes the API endpoint associated with this Lambda. The Base URL of an API Gateway will be prepended to this path. The part(s) inside
{}denotes path parameters, i.e. values that users will provide dynamically. In our case, it will be the name of the OpenSearch index.Method: This is the HTTP method that will be accessible for this endpoint. In our case, this endpoint will only allow POST requests.
RestApiId: The API Gateway this Lambda is associated with. If no value is provided for this property, a default Gateway will be created.
Wheeeeeeeeh! Now comes the fun part. 🏝️
Part 2:
In this section, we are going to describe the handler code for each of the Lambda functions.
At the end of this section, your project hierarchy will look something like this,
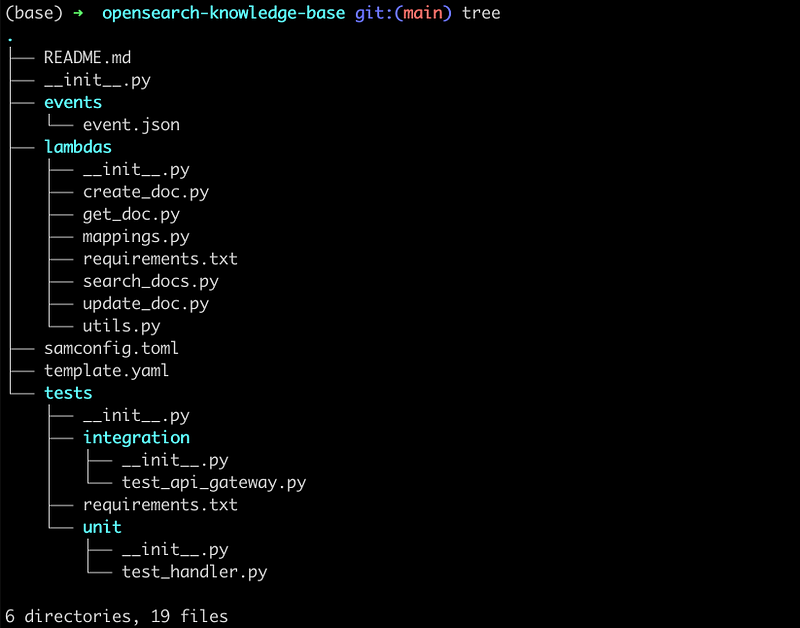
Project directory hierarchy
But first, we need to do a couple of things to make our life easier for later.
- As we will be using some external Python library in our code to interact with the OpenSearch instance, we need to specify the required packages in a requirements.txt file inside /lambdas directory. Paste the following line inside this file.
opensearch-py
2. Create another Python file called utils.py inside /lambdas directory. As the name suggests, this file will contain lots of helper functions, custom exceptions, and initialization code for OpenSearch. Following is the content of this file.
import json
import os
import boto3
from opensearchpy import OpenSearch
# Env params
os_secret = os.environ.get("OPEN_SEARCH_SECRET")
os_domain_endpoint = os.environ.get("OPEN_SEARCH_DOMAIN_ENDPOINT")
# Initialization
sm_client = boto3.client("secretsmanager")
sm_response = sm_client.get_secret_value(SecretId=os_secret)
secret = json.loads(sm_response["SecretString"])
auth_pass = (secret.get("username"), secret.get("password"))
os_domain_port = {"host": os_domain_endpoint, "port": 443}
os_client = OpenSearch(
hosts=[os_domain_port],
http_compress=True,
http_auth=auth_pass,
use_ssl=True,
verify_certs=True,
)
# Util functions
def check_index_exists(index_name):
if not os_client.indices.exists(index=index_name):
raise IndexNotFoundException("Invalid parameter!")
def get_response(status=400, message="", data=None):
headers = {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "*",
"Access-Control-Allow-Headers": "*",
}
return {
"statusCode": status,
"headers": headers,
"body": json.dumps({"message": message, "data": data}, default=str),
}
# Exceptions
class ValidationError(Exception):
pass
class IndexNotFoundException(Exception):
pass
All you need to know from here is this —
We will import this file in each of our Lambda handlers and get ready-made access to the OpenSearch instance through the library we installed earlier.
Authentication to OpenSearch using the credentials stored in Secrets Manager will be taken care of by this helper. And now you see why we passed those two environment variables in the template file? 😎
Now, we will describe the code for each Lambda handler in detail. Create the specified files and copy the code for each handler module as shown here.
- Create Document (create_doc.py): This will create new documents and send them to the OpenSearch for indexing.
import time
import json
from utils import os_client, get_response, check_index_exists, ValidationError, IndexNotFoundException
def lambda_handler(event, context):
try:
print(event)
index_name = event["pathParameters"]["index_name"]
parsed_body = json.loads(event["body"])
validate_payload(parsed_body)
check_index_exists(index_name)
created_by = parsed_body["created_by"]
created_at_ms = int(time.time() * 1000)
form_data = {
"category": parsed_body["category"],
"title": parsed_body["title"],
"tags": parsed_body["tags"],
"md_content": parsed_body["md_content"],
"created_by": created_by,
"created_at_ms": created_at_ms,
"last_updated_by": created_by,
"last_updated_at_ms": created_at_ms,
}
response = os_client.index(
index=index_name,
body=form_data,
refresh=True,
)
print(response)
return get_response(
status=200,
message=f"Document (ID: {response.get('_id')}) created successfully",
data="",
)
except ValidationError as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except IndexNotFoundException as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except Exception as e:
print(e)
return get_response(
status=400,
message="error",
)
def validate_payload(body):
is_payload_valid = True
is_payload_valid = is_payload_valid and "category" in body and body["category"]
is_payload_valid = is_payload_valid and "title" in body and body["title"]
is_payload_valid = is_payload_valid and "tags" in body and body["tags"]
is_payload_valid = is_payload_valid and "md_content" in body and body["md_content"]
is_payload_valid = is_payload_valid and "created_by" in body and body["created_by"]
if not is_payload_valid:
raise ValidationError("Must provide all values!")
2. Update Document (update_doc.py): This will update the existing documents already indexed by the OpenSearch.
import time
import json
from utils import os_client, get_response, check_index_exists, ValidationError, IndexNotFoundException
from opensearchpy import NotFoundError
def lambda_handler(event, context):
try:
print(event)
index_name = event["pathParameters"]["index_name"]
doc_id = event["pathParameters"]["doc_id"]
parsed_body = json.loads(event["body"])
validate_payload(parsed_body)
check_index_exists(index_name)
last_updated_by = parsed_body["last_updated_by"]
last_updated_at_ms = int(time.time() * 1000)
form_data = {
"category": parsed_body["category"],
"title": parsed_body["title"],
"tags": parsed_body["tags"],
"md_content": parsed_body["md_content"],
"last_updated_by": last_updated_by,
"last_updated_at_ms": last_updated_at_ms,
}
body = {"doc": form_data}
response = os_client.update(
index=index_name,
id=doc_id,
body=body,
_source=True,
)
print(response)
return get_response(
status=200,
message=f"Document (ID: {response.get('_id')}) updated successfully",
data="",
)
except ValidationError as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except IndexNotFoundException as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except NotFoundError as e:
print(e)
return get_response(
status=400,
message="Document not found!",
)
except Exception as e:
print(e)
return get_response(
status=400,
message="error",
)
def validate_payload(body):
is_payload_valid = True
is_payload_valid = is_payload_valid and "category" in body and body["category"]
is_payload_valid = is_payload_valid and "title" in body and body["title"]
is_payload_valid = is_payload_valid and "tags" in body and body["tags"]
is_payload_valid = is_payload_valid and "md_content" in body and body["md_content"]
is_payload_valid = is_payload_valid and "last_updated_by" in body and body["last_updated_by"]
if not is_payload_valid:
raise ValidationError("Must provide all values!")
3. Get Document (get_doc.py): As the name suggests, this will fetch a particular document from OpenSearch by document-id.
from utils import os_client, get_response, check_index_exists, IndexNotFoundException
from opensearchpy import NotFoundError
def lambda_handler(event, context):
try:
print(event)
index_name = event["pathParameters"]["index_name"]
doc_id = event["pathParameters"]["doc_id"]
check_index_exists(index_name)
response = os_client.get(
index=index_name,
id=doc_id,
)
print(response)
temp = response["_source"]
temp["doc_id"] = response["_id"]
return get_response(
status=200,
message="",
data=temp,
)
except IndexNotFoundException as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except NotFoundError as e:
print(e)
return get_response(
status=400,
message="Document not found!",
)
except Exception as e:
print(e)
return get_response(
status=400,
message="error",
)
4. Search Documents (search_docs.py): This will take some query parameters and use the power of full-text searching by OpenSearch to retrieve the most relevant documents.
import json
from utils import os_client, get_response, check_index_exists, ValidationError, IndexNotFoundException
def lambda_handler(event, context):
try:
print(event)
index_name = event["pathParameters"]["index_name"]
parsed_body = json.loads(event["body"])
validate_payload(parsed_body)
check_index_exists(index_name)
query_dict = {
"query": {
"bool": {
"minimum_should_match": 1,
"should": [
{
"multi_match": {
"query": parsed_body["text"],
"fields": ["title^5", "tags^4", "md_content^3", "created_by^2", "last_updated_by^2"],
"fuzziness": "AUTO"
}
}
],
}
}
}
if parsed_body.get("category") and parsed_body.get("category").lower() != "all":
query_dict["query"]["bool"]["filter"] = [
{"term": { "category": parsed_body.get("category")}}
]
response = os_client.search(
body=query_dict, index=index_name
)
print(response)
formatted_docs = []
for doc in response["hits"]["hits"]:
temp = doc["_source"]
temp["doc_id"] = doc["_id"]
formatted_docs.append(temp)
result = {
"count": response["hits"]["total"]["value"],
"documents": formatted_docs
}
return get_response(
status=200,
message="",
data=result,
)
except ValidationError as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except IndexNotFoundException as e:
print(e)
return get_response(
status=400,
message=str(e),
)
except Exception as e:
print(e)
return get_response(
status=400,
message="error",
)
def validate_payload(body):
is_payload_valid = True
is_payload_valid = is_payload_valid and "text" in body and body["text"]
if not is_payload_valid:
raise ValidationError("Must provide search text!")
We are DONE! 🎆🎆🎆
You can compare your project that we have built from scratch with an existing working version from this repo. In case you face any issues during deployment to AWS, simply compare your template and code with this version. 🙌
Part 3:
Now, we will deploy our completed project to AWS using SAM CLI.
Follow the steps below to do just that:
Open a terminal.
Change the current working directory to the project’s root directory (where the template.yaml file is located).
cd DIRECTORY_NAMEType in
sam buildto prepare the project to be deployed. It will create a hidden folder /.aws-sam in the root directory of the project.Type in
sam deploy --guided(Use the guided option ONLY if you are deploying the template for the very first time. For all subsequent deployments, simply usesam deploy).Follow the on-screen instructions and accept the default options. A sample configuration settings is provided below:
$> sam deploy --guided
Stack Name [sam-app]: opensearch-knowledge-base
AWS Region [us-east-1]:
Parameter AllPrefix [knowledge-base]:
Parameter StageName [dev]:
Confirm changes before deploy [y/N]: y
Allow SAM CLI IAM role creation [Y/n]: y
Disable rollback [y/N]: y
CreateDocumentFunction has no authentication. Is this okay? [y/N]: y
UpdateDocumentFunction has no authentication. Is this okay? [y/N]: y
GetDocumentFunction has no authentication. Is this okay? [y/N]: y
SearchDocumentsFunction has no authentication. Is this okay? [y/N]: y
Save arguments to configuration file [Y/n]: y
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
- Once the stack is deployed, note the ApiGatewayLambdaInvokeUrl in the Outputs section. It will be something like this “https://aaaa1111bbbb.execute-api.us-east-1.amazonaws.com/dev”. This is the Base URL that will be used to call our APIs.
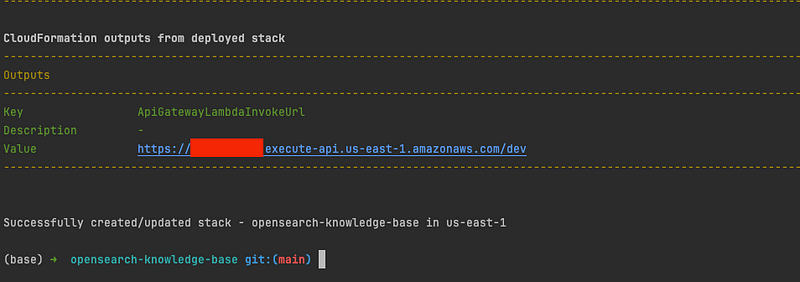
Test API:
Now that our project is deployed, we can call the APIs to interact with OpenSearch. Let’s create a document using CURL by calling the endpoint “https://aaaa1111bbbb.execute-api.us-east-1.amazonaws.com/dev/{index_name}/kb-docs”. Replace the {index_name} with knowledgebase.
curl -X POST -H "Content-Type: application/json" -d '{"title":"How to fix ABC error", "category":"Admin", "created_by":"Test User", "tags":"Error, Issue", "md_content":"**Need to manually update the field**"}' https://aaaa1111bbbb.execute-api.us-west-2.amazonaws.com/dev/knowledgebase/kb-docs
Aaaaand, we get an error, {“message”: “Invalid parameter!”, “data”: null}. 🧐
What did we miss?! 🤯
No need to panic! We simply forgot to create the index that we provided in the API endpoint(knowledgebase) in OpenSearch. 🤓
Create OpenSearch Index:
- Log in to AWS Console.
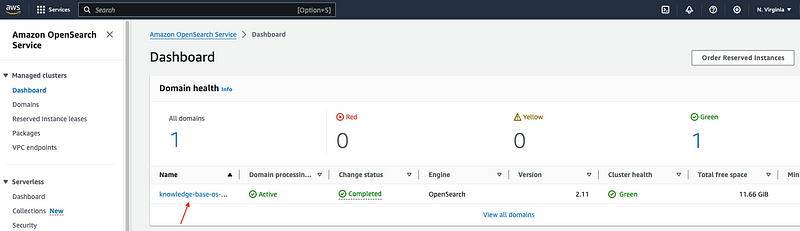
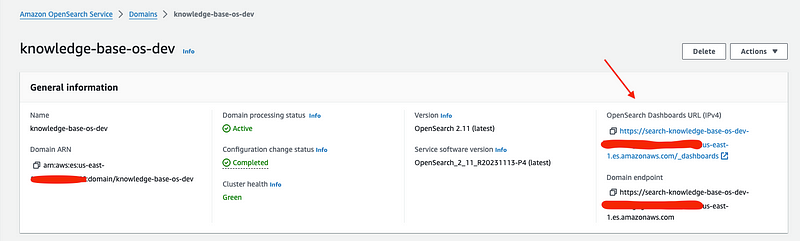
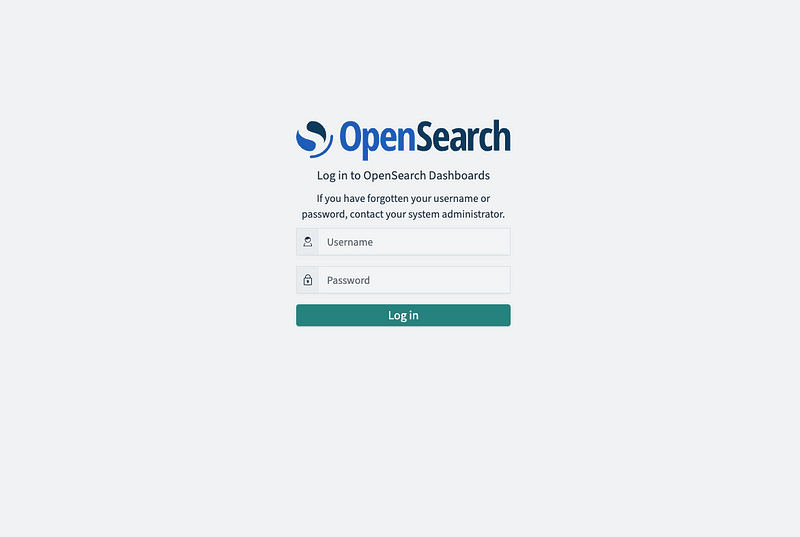
2. Go to OpenSearch console and click on the OpenSearch instance under the Domain section. Click on the link under “OpenSearch Dashboards URL (IPv4)”. Wait for a Login page to appear.
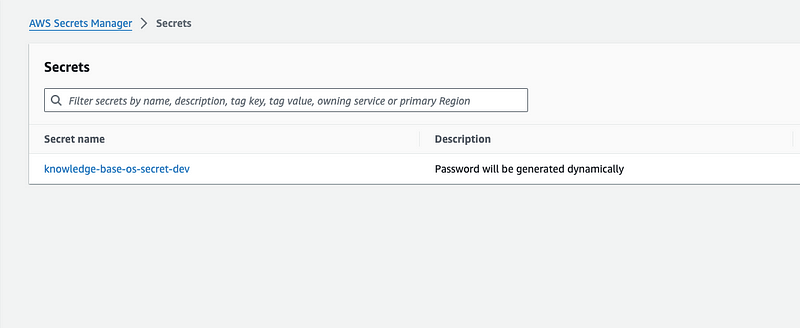
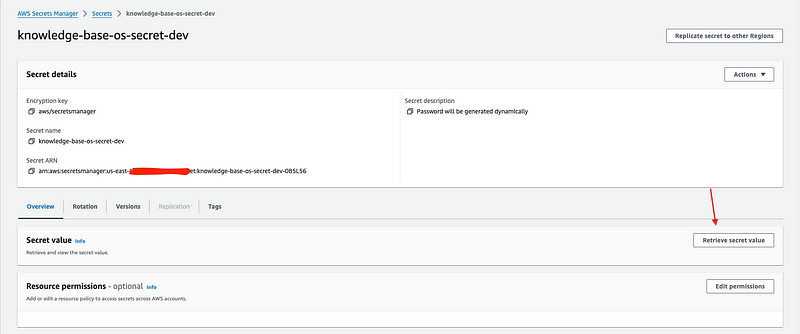
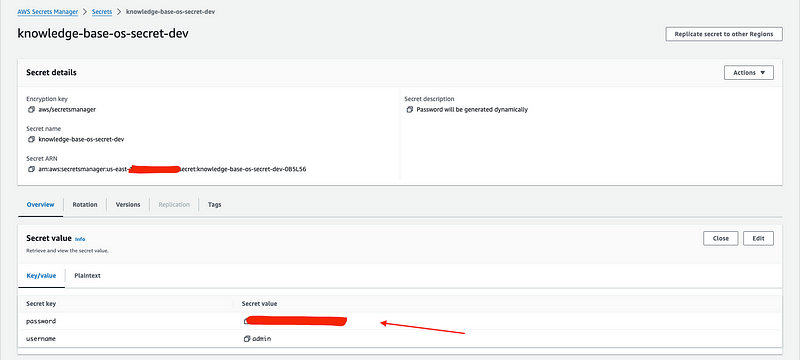
3. Go to Secrets Manager console and click on the secret created as part of our project. On the details page, locate the “Secret Value” section and click on the “Retrieve secret value”. This will show the username and password for OpenSearch Dashboard. Use these to log into OpenSearch.
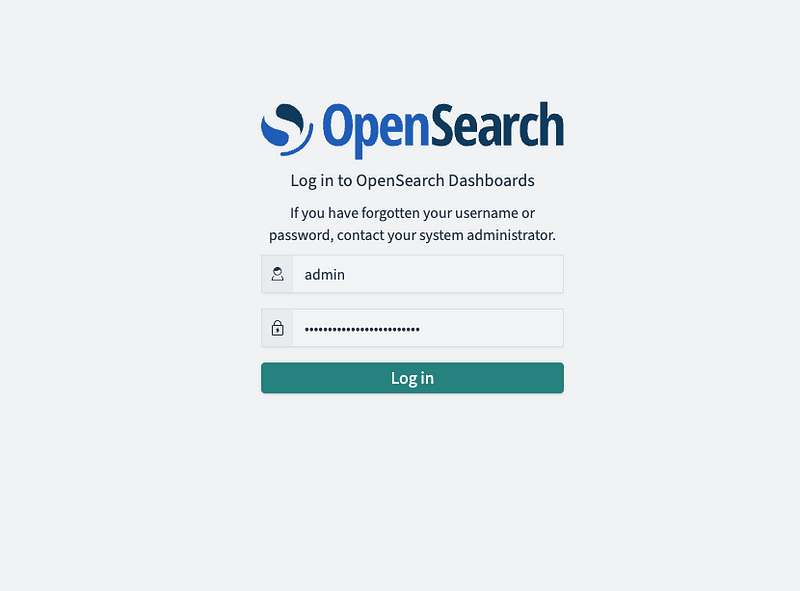
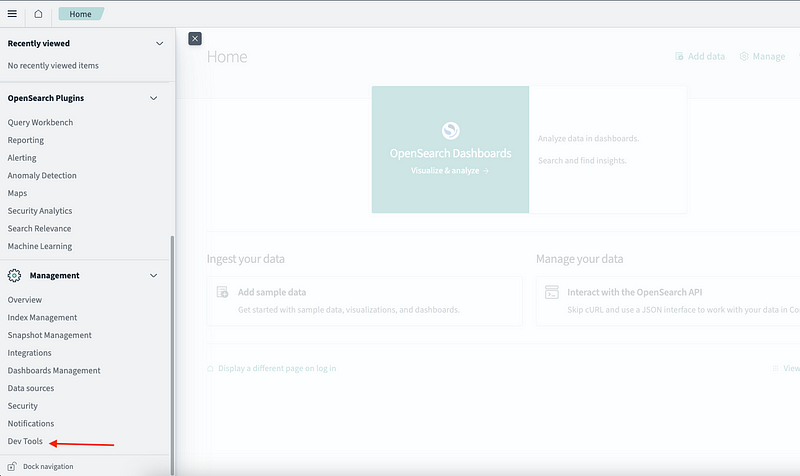
4. Select Explore on my own and then when prompted, select Global. From the Navigation menu, go to Management > Dev Tools.
5. We can see an editor section on our left. We can directly interact with our OpenSearch instance by entering various commands here.
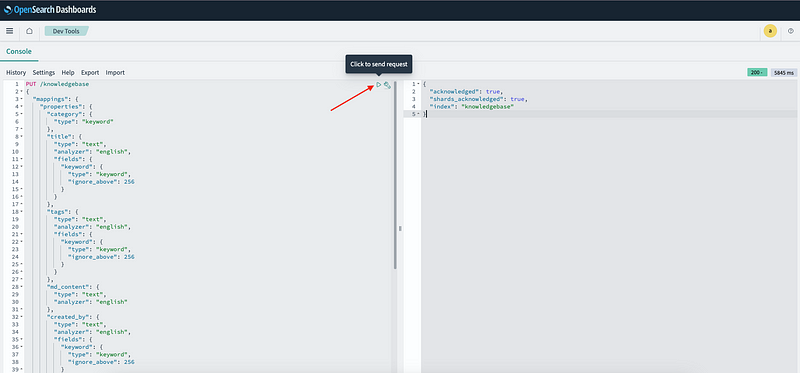
Paste the following block of code in the editor and press Run (Shown above).
PUT /knowledgebase
{
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "english",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"tags": {
"type": "text",
"analyzer": "english",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"md_content": {
"type": "text",
"analyzer": "english"
},
"created_by": {
"type": "text",
"analyzer": "english",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"created_at_ms": {
"type": "date",
"format": "epoch_millis"
},
"last_updated_by": {
"type": "text",
"analyzer": "english",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"last_updated_at_ms": {
"type": "date",
"format": "epoch_millis"
}
}
}
}
Now that we have successfully created the index knowledgebase, execute the CURL command again from above, and voila!
We have successfully deployed a knowledge base backend built using Amazon OpenSearch, API Gateway, and Lambda. 🎉🎉
The entire project can be found in this repository.
If you found this post useful, please give it a 👏🏽 and follow me on Medium. Let’s get connected on LinkedIn.
Subscribe to my newsletter
Read articles from Asadullah Al Galib directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by