Navigating Knowledge Landscapes: Building Basic Knowledge Graphs with Vector Search
 Saurabh Naik
Saurabh Naik
Introduction:
In the vast expanse of data, finding relevant information can feel like searching for a needle in a haystack. Traditional search methods often fall short when it comes to understanding the context and relationships between different pieces of information. This is where knowledge graphs and vector search come into play. In this blog post, we'll explore how to construct a basic knowledge graph using a technique called Relevant Answer Graph (RAG) and leverage vector search to enhance information retrieval.
Data Preprocessing and Cleaning:
Before we can embark on constructing our knowledge graph, we need to ensure our data is in a usable format. This involves preprocessing steps such as text extraction from documents and data cleaning to remove noise and irrelevant information. By streamlining our data, we lay the foundation for more accurate and efficient analysis.
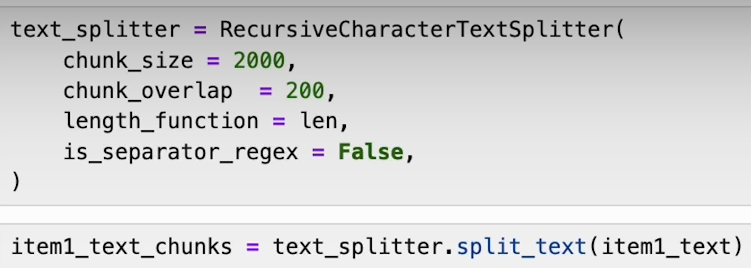
Data Chunking:
With our data preprocessed and cleaned, we can now break it down into smaller, more manageable chunks. This step, known as data chunking, helps us organize the information into digestible segments, making it easier to analyze and extract meaningful insights.
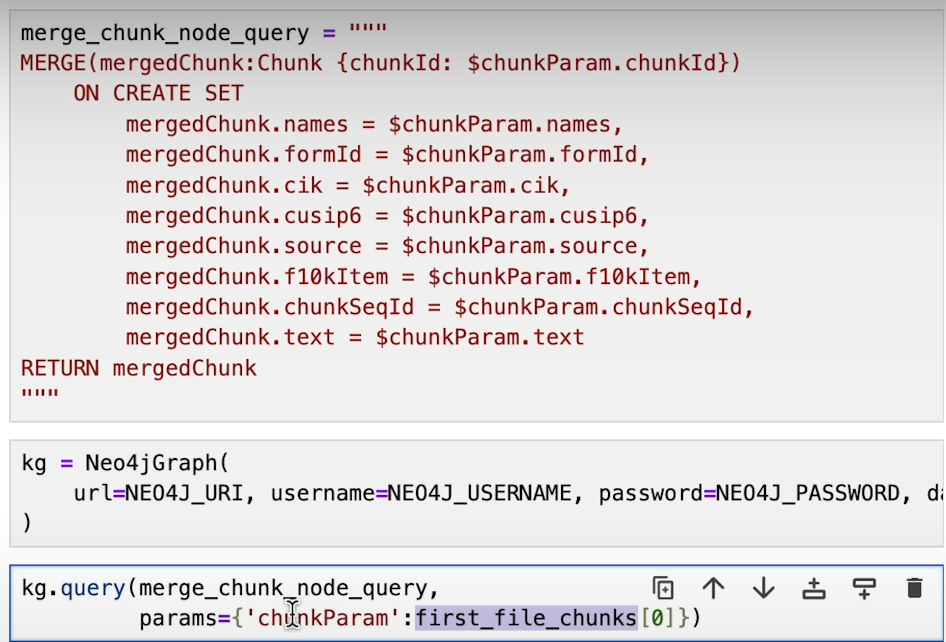
Constructing the Knowledge Graph:
Now comes the heart of our process: constructing the knowledge graph. Each chunk of data becomes a node in our graph, and we add metadata as properties to capture additional context. By establishing connections between nodes, we create a network that represents the relationships and dependencies within our data.
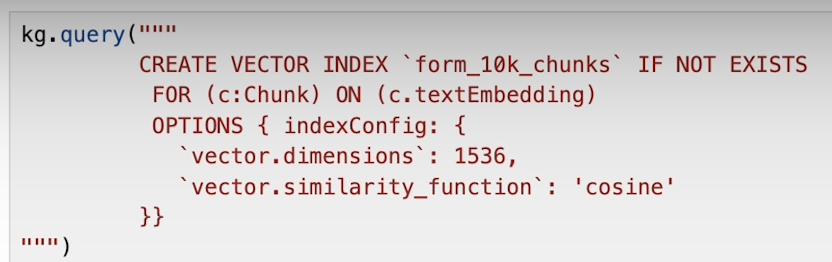
Creating the Vector Index:
To enable efficient retrieval of relevant information from our knowledge graph, we employ vector indexing. This involves converting our textual data into numerical representations (embeddings) using techniques like word embeddings or pre-trained language models.
Populating the Vector Index:
Once we have generated embeddings for our data, we populate the vector index with these representations. This step involves calculating the embeddings for each node in our knowledge graph and storing them in the index, creating a searchable repository of information.

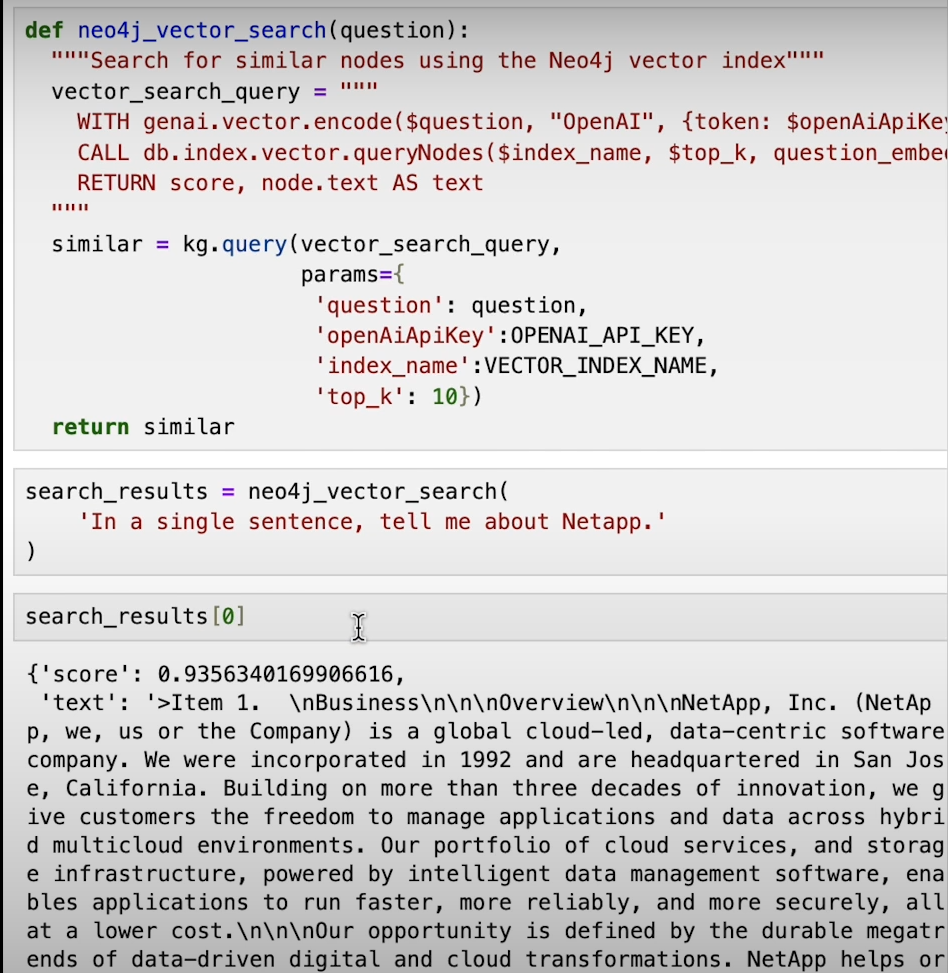
Retrieving Relevant Text:
With our vector index in place, we can now perform similarity searches to retrieve the most relevant text based on a given query. By comparing the embeddings of the query with those of the indexed data, we can identify the closest matches and present them as results.
Summary:
In this blog post, we've explored the process of constructing a basic knowledge graph using the Relevant Answer Graph (RAG) approach and enhancing it with vector search capabilities. By preprocessing and chunking our data, constructing the graph, creating a vector index, and leveraging similarity search, we can unlock the full potential of our data, enabling more efficient information retrieval and knowledge discovery. Whether you're navigating vast datasets or seeking insights from complex documents, the combination of knowledge graphs and vector search offers a powerful toolkit for exploring the ever-expanding landscape of information.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com