Unraveling Complexity: Advanced Knowledge Graph RAG with Relationship-Aware Retrieval
 Saurabh Naik
Saurabh Naik
Introduction:
In the ever-expanding landscape of data, understanding the intricate relationships between pieces of information is crucial for unlocking deeper insights and facilitating more meaningful interactions. Building upon the foundations of basic knowledge graphs, advanced Knowledge Graphs with Relationship-Aware Retrieval (RAGs) offer a sophisticated framework for capturing context-rich connections between nodes and enhancing the relevance of information retrieval. In this technical blog, we delve into the intricacies of constructing and utilizing advanced RAGs, integrating vector search with relationship context to navigate complex datasets with precision.
Relationships:
The Backbone of Contextual Understanding In the realm of advanced RAGs, relationships serve as the linchpin that binds nodes together, elucidating the nuanced context behind their connections. These links, akin to threads in a tapestry, weave a narrative that enhances the understanding of the data landscape.
Linked Lists:
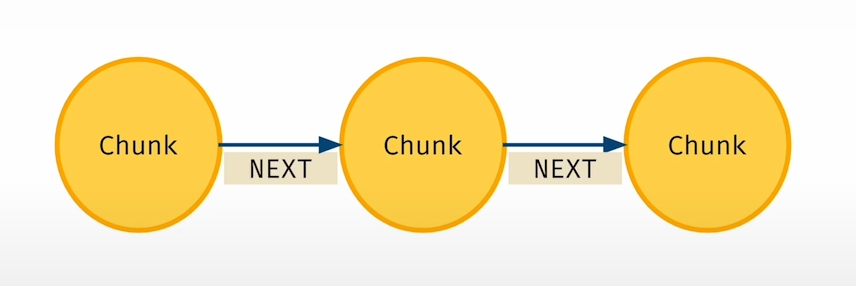
Navigating the Interconnected Web To effectively represent the intricate web of relationships within our knowledge graph, we leverage linked lists as a powerful data structure. This enables seamless traversal between nodes, allowing for efficient exploration of the network's interconnectedness.
Leveraging Cypher Query Language Cypher:
A query language tailored for graph databases like Neo4j, empowers us to define and manipulate relationships within our knowledge graph with ease. By crafting Cypher queries, we can create, traverse, and extract valuable insights from the graph's rich tapestry of connections.
Steps to Create Advanced Knowledge Graph RAGs:
Data Preprocessing and Cleaning:
Before embarking on our journey to construct an advanced RAG, we must preprocess and clean our source data. This involves extracting content from documents and applying data cleaning techniques to ensure the integrity and quality of our data.
Data Chunking:

Once our data is refined, we segment it into smaller, more manageable chunks through the process of data chunking. This segmentation facilitates more granular analysis and enhances the scalability of our knowledge graph.
Constructing the Knowledge Graph:

Each chunk of data forms a node within our knowledge graph, augmented with metadata properties to provide additional context. As we connect these nodes through relationships, we weave a rich tapestry of interconnected information.
Creating the Vector Index:

To enable efficient retrieval of relevant information, we create a vector index that serves as a repository of textual embeddings. These embeddings capture the semantic essence of each node, facilitating nuanced similarity searches.
Populating the Vector Index:

We populate the vector index by calculating text embeddings for each node and storing them within the index. This process lays the foundation for robust information retrieval powered by vector search techniques.
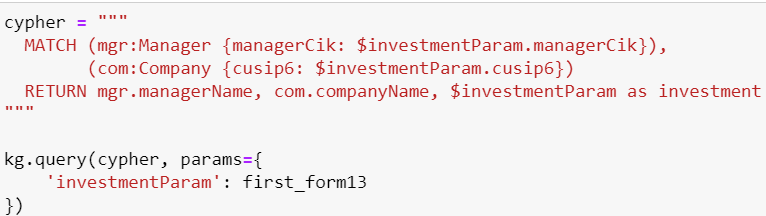
Relationship-Aware Retrieval with Cypher Queries:
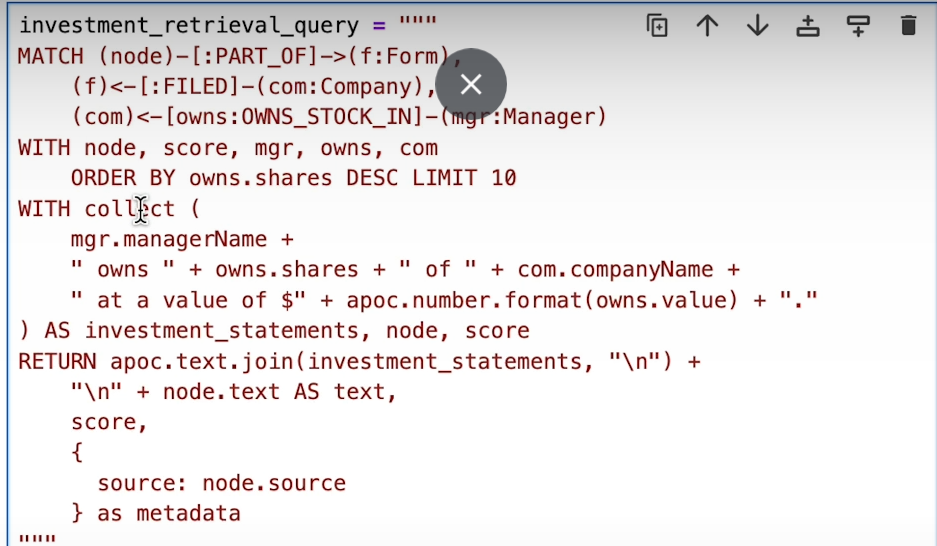
By defining Cypher queries that incorporate relationship context, we enrich our retrieval process with deeper semantic understanding. These queries navigate the interconnected web of our knowledge graph, extracting relevant information tailored to specific contexts.
Constructing Retrieval Chains:
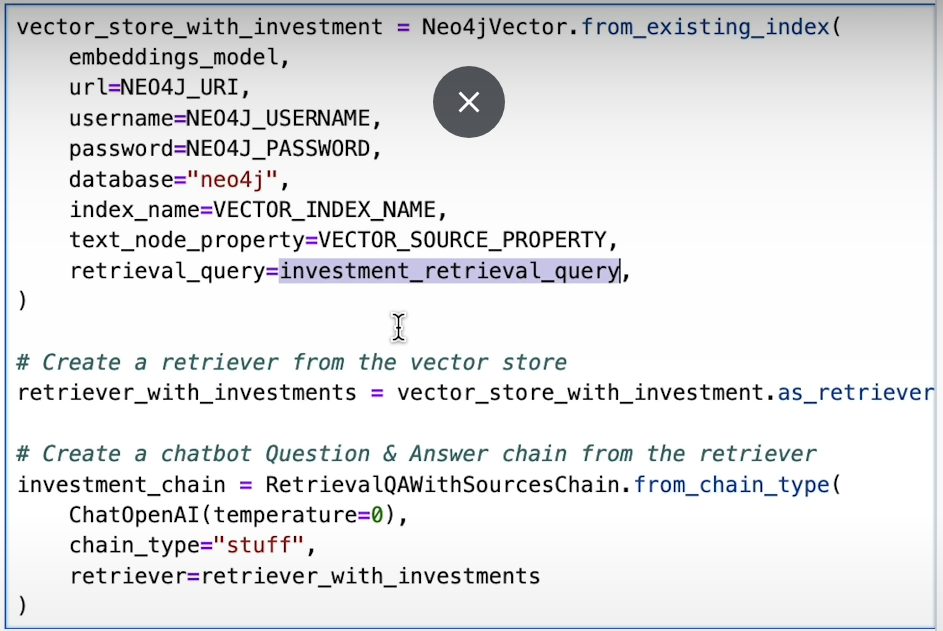
We construct retrieval chains that leverage relationship-aware queries to orchestrate the flow of information retrieval. These chains enable seamless traversal of the knowledge graph, guiding us towards meaningful answers to our queries.
Putting it into Practice:
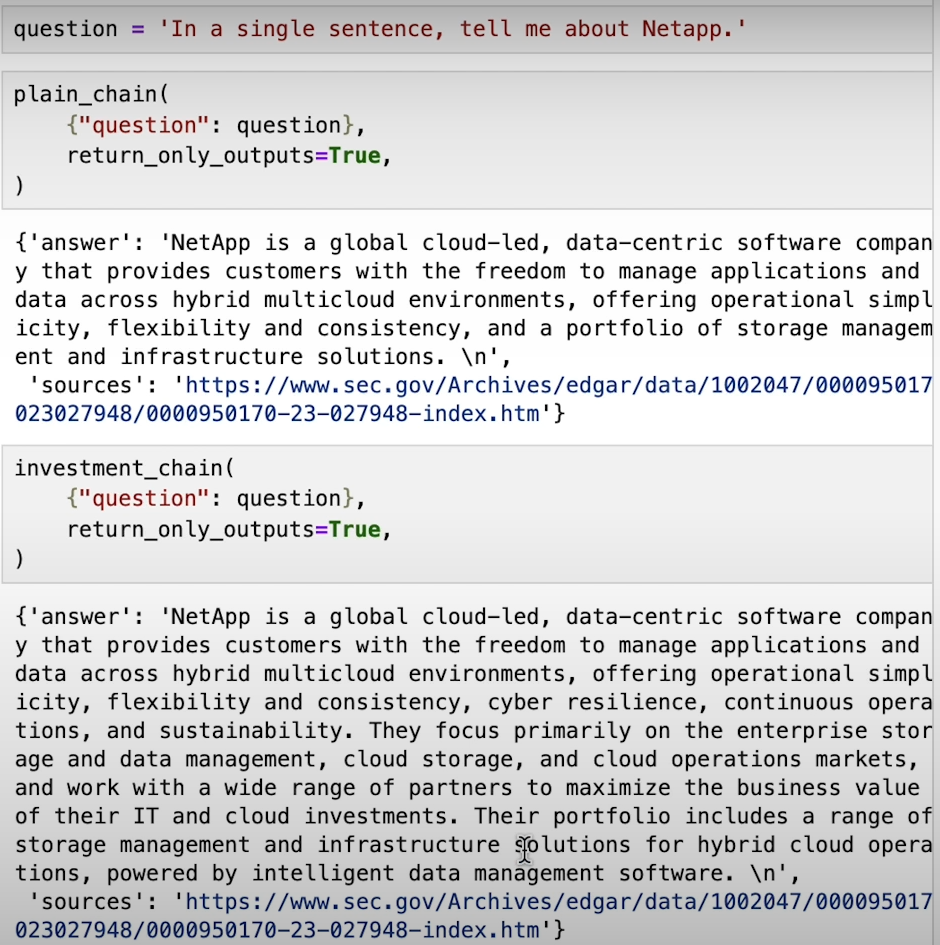
Finally, we put our advanced RAG to the test by executing retrieval chains to answer questions and uncover insights within our data. Through iterative refinement and experimentation, we harness the full potential of our knowledge graph to navigate the complexities of the data landscape.
Summary:
Advanced Knowledge Graphs with Relationship-Aware Retrieval represent a paradigm shift in how we navigate and extract insights from complex datasets. By intertwining relationship context with vector search capabilities, we transcend traditional information retrieval methods, unlocking deeper understanding and facilitating more meaningful interactions with our data. From data preprocessing to constructing retrieval chains, each step in the process is imbued with the aim of illuminating the intricacies of the data landscape and empowering users to uncover actionable insights.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com