Optimizing SQL query performance:
 Diptarup Mukherjee
Diptarup MukherjeeTable of contents

In order to understand the optimization of SQL queries first we need to understand what actually happens in the background when we query our database table. So grab a cup of coffee and lets start our discussion by considering a scenario. All query examples will given by considering PostgreSQL as backend database though you can apply same concepts in other databases also. Suppose there is an application which shows movies information for selected filters just like IMDB app. So when user selects a particular genre, release year, rating and country to see top 5 high revenue films the below query gets executed in backend database (We will understand performance optimization by referring below sample query in this article) :
-- Backend Query
WITH ranked_movies AS
(SELECT
movie_name,
imdb_score,
TO_CHAR(release_date,'YYYY') AS "year"
revenue,
DENSE_RANK() OVER(ORDER BY revenue DESC) rnk -- Ranking Movies Data
FROM movies
WHERE genre = param_genre -- User Parameter
and TO_CHAR(release_date,'YYYY') = param_year -- User Parameter
and rating = param_rating -- User Parameter
and country = param_country -- User Parameter
) ;
-- Getting Top 5 Movies
SELECT
movie_name,
imdb_score,
"year",
revenue
FROM
ranked_movies
WHERE rnk <= 5;
In backend database there is a table called movies where all movies data are stored. Schema is like:
-- Movies Table Schema:
CREATE TABLE movies(
movie_id INT PRIMARY KEY,
movie_name VARCHAR(300),
genre VARCHAR(300),
imdb_score DOUBLE PRECISION,
revenue NUMERIC,
lead_actor VARCHAR(300),
movie_description TEXT,
rating VARCHAR(300)
);
Each month when new movie releases data gets loaded in this table by an ETL job. So our movies table is getting bigger in terms of total number of records !! Currently our movies table is storing 10 million records. So above backend query may take time (Around 40 to 50 seconds sometimes over 1 minute) to execute and end users need to wait to get top 5 movies data on application. End users are not satisfied as they need to wait for 1 minute to get desired result on app so we need to optimize the query execution time.
In this article we are going to discuss 2 optimization strategies:
Column Indexing (B-Tree Index)
Table Partitioning (List Partitioning Technique)
Column Indexing In Database:
The above sample query is executed by DB engine in the below order:
FROM clause execution (Fetching Data From Disk To Memory)
WHERE clause execution (Filtering Data Based On Given Inputs)
Window Function Execution (Ranking Data)
SELECT cluse execution (SELECT particular columns)
In the disk, data is stored page by page. Page is nothing but a logical unit which will store certain number of records. Based on where condition when data is fetched from disk at that time by default all pages are scanned one after another by database engine. This type of scanning is called Sequential Scan. When condition is satisfied then those records will be fetched from disk to memory for further processing.
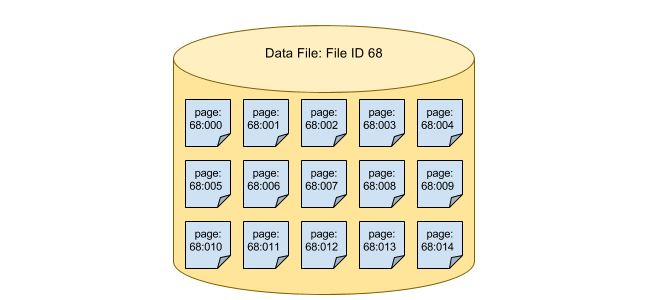
Data Stored In Disk Page By Page
If table is storing millions of records just like our movies table then sequential scan becomes very much costly that's why our end users need to wait for some time to get data on their app. In Sequential Scan lot of I/O requests to disk is going on, somehow if we can reduce total number of I/O requests then our query will take less time to execute. Here comes the Indexing to help us !!
Index is a data structure which will hold the address of requested data. If you already know the location of the data you are searching for then you don't need to search it sequentially. Immediately you will go to that location and fetch the data. That's the idea behind indexing.
Indexing Strategy:
Apply indexing on the columns which are used in WHERE clause.
Index the columns in same order as they are appearing in WHERE clause.
First try with B-Tree indexing. Later try other indexing techniques (BRIN,GIN indexes)
Below is the way to create index on columns:
CREATE INDEX movies_gnr_rd_rat_coun_ind
ON movies USING BTREE (genre,release_date,rating,country);
/*genre,release_date,rating,country columns are used
in the where clause of sample query*/
Now index data structure is storing location of each record for those columns (Genre ,Release Date, Rating and Country). So when query comes like:
SELECT
movie_name,
imdb_score,
TO_CHAR(release_date,'YYYY') AS release_year,
revenue
FROM
movies
WHERE genre = 'Action'
AND TO_CHAR(release_date,'YYYY') = '2022';
By scanning index data structure database engine is now aware that Action genre and 2022 release year (Requested data) are stored in which page of the disk. So immediately engine will fetch the requested data from that page. This type of scan is called Index Scan. Here sequentially the pages are not scanned so I/O requests are reduced and our query got optimized !!
Table Partitioning:
Above indexing technique is appropriate if total number records in table is within 5 to 10 million. If the number goes beyond that then only indexing on columns may not sufficient. So due to monthly data load our movies table is now storing 30 millions of movies records !! Indexing was done but then also database queries taking again longer time (1 to 2 minutes). End users are again unhappy :(
So the next optimization strategy comes into picture that is table partitioning. Suppose user is firing below query:
SELECT
movie_name,
genre,
revenue,
imdb_score
FROM
movies
WHERE
genre = 'Comedy' -- User is requesting for Comedy genre
AND TO_CHAR(release_date,'YYYY') = '2023' ;
Using the app interface user is selecting the comedy movies which got released in 2023. Now when DB engine is executing the above user query it is going to use the index file. Indexing was done on genre and release_date columns. There are movies of 5 distinct genres in our movies table.
Action
Comedy
Horror
Adventure
Thriller
If movies table is storing 30 million records then only indexing is not sufficient and the reasons are:
While DB engine is scanning the index file it has to scan for all genres (Action, Comedy, Horror etc) to look for requested genre.
If data is huge in that table then scanning all genre in that index file is becoming costly.
Somehow if we can exclude processing other data which are not required (Here genres except Comedy) then index scan will be optimized. That can be done using table partitioning. Table partitioning is an optimization technique where database table is partitioned based on a column and based of where condition only specific partition of data will be processed.
How Partitions Increases Query Performance ?
Based on column used in WHERE clause table is partitioned.
Total number of partitions will be equal to distinct values in that column (For example: if partitioning is done on genre then 5 partitions will be created as 5 distinct genres are there in movies table)
If 30 million records are stored in movies table then in each partition 6 million records will be stored.
Based on WHERE condition only specific partition will be processed. (6 million records are processed instead of 30 million)
Other partitions are excluded and they are not processed. (Excluding other partitions is known as Partition Pruning)
As DB engine is processing lesser data so query performance will be boosted.
Here in the above query example genres except Comedy will no longer processed by DB engine.To create partitions on specific column of movies table we need to consider that table as Master Table. Below is the code to create partitions on Genre column:
-- Creating movies master table:
CREATE TABLE movies(
movie_id INT PRIMARY KEY,
movie_name VARCHAR(300),
genre VARCHAR(300),
imdb_score DOUBLE PRECISION,
revenue NUMERIC,
lead_actor VARCHAR(300),
movie_description TEXT,
rating VARCHAR(300)
) PARTITION BY (genre);
-- Creating Partitions Of Master Table Based on Genre:
-- 5 distinct genre are there so 5 partitions will be created:
CREATE TABLE movies_par_action PARTITION OF movies
FOR genre IN ('Action');
CREATE TABLE movies_par_comedy PARTITION OF movies
FOR genre IN ('Comedy');
CREATE TABLE movies_par_horror PARTITION OF movies
FOR genre IN ('Horror');
CREATE TABLE movies_par_adv PARTITION OF movies
FOR genre IN ('Adventure');
CREATE TABLE movies_par_thriller PARTITION OF movies
FOR genre IN ('Thriller');
Above partitioning technique is known as List Partitioning. When data gets loaded in movies table then based on genre data will be stored in respective partitions(Actions genre data will be stored to action partition, comedy data in comedy partition so on). Below points we need to remember while partitioning a table based on a column:
Master table does not store any data (Here movies table). Only partitions will store data. We can verify it by running below query:
SELECT * FROM ONLY movies; -- It will return 0 recordsBy ETL job while loading data if any other genre comes (For example: Crime) then data load will raise error. As partitions are created only for those 5 genres. So we can create a default partition for error handling. It will store data of any other genres.
CREATE TABLE movies_par_others PARTITION OF movies DEFAULT;To ensure database engines to exclude other partitions based on WHERE condition we can run below query:
SET enable_partition_pruning = ON; -- Only specific partition will be processed other partitions will be prunedAlways ensure that in each partition total number of records is uniform. If any partition storing bigger amount of data then again DB engine will take time to process that partition. So run below query to know total records in each partition.
SELECT genre, COUNT(1) total_records FROM movies GROUP BY genre;If total number of records are uniform in each genre then only partition the table by this column.
CONCLUSION
NOTE: Analyze your data before doing partitioning. Wrong partitioning may lead to degradation of query performance. To know the partition column use below tips:
Use columns in WHERE clause as partition column.
Check distinct records in those columns.
Check count of records for each distinct value. (Example: Total records for each genre)
If count is uniform in each distinct value we can consider it as partition column.
Use that same partition column as your index column also.
Use both indexing and partitioning to get best query performance.
List partitioning is only applicable if a column is storing categorical or textual data like (country, movie genre, product category etc). If column is storing date values then Range Partitioning will be helpful.
Sometime you may need to perform Sub Partitioning if data size is massive in your table (For example 50 or 60 million). Sub Partitioning is noting but partitioning your partition tables.
Subscribe to my newsletter
Read articles from Diptarup Mukherjee directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by