Navigating NoSQL: A Journey through Graphs, Documents, and Key-Value Pairs — 5
 Aruna Das
Aruna Das
Data model is a tool which helps you organize your data in the storage. It allows you to manipulate and access your data. Relational database was very successful for 20 decades from 1980 to 2000. Then came the age of data where volume of data increase many folds.
The relational database though very successful in single cluster didn’t scale very well in distributed cluster. It’s very hard to manage multiple cluster relational database and maintain consistency across multiple clusters hence came NoSQL solution.
NoSQL works very well in distributed cluster system it provided alternative solution to short coming of relational database system. In the world of relational database you organize your data into referential integrity with foreign keys and normalize in entity-relational diagram they can be visualized as set of tables symbolizes as spreadsheet your data this data modeling doesn’t work in NoSQL world of things in this article we will discuss data models of NoSQL.
NoSQL has 4 data models:
Key Value
Document
Column-family
Graph
Aggregates are a term that comes from Domain Driven Design by Evans. An Aggregate is a collection of related objects that are treated as a unit. They act as a unit for data manipulation and the management of consistency. Transactions occur at the atomic level, which is consistent in a NoSQL system; it’s at the aggregate level.
Aggregate orientation helps running in clusters. When we run on clusters we need to minimize how many nodes we need to query to gather required data. By defining aggregate according to business requirement we give the database important information about which bits of data will be manipulated together should live in same node.
Relational database allows us to perform data manipulation across various rows spanning many tables updated as single transaction under ACID. It’s often the conception that NoSQL has no ACID which is true only in the context of aggregated-oriented database don’t have ACID transactions that span multiple aggregate. Atomicity in these database is at single aggregate. So it’s important to give consideration in dividing up your business data into aggregates.
Let’s take an example to see how these model comes into play:
Old world of relational database with users and order data model from e-commerce application.
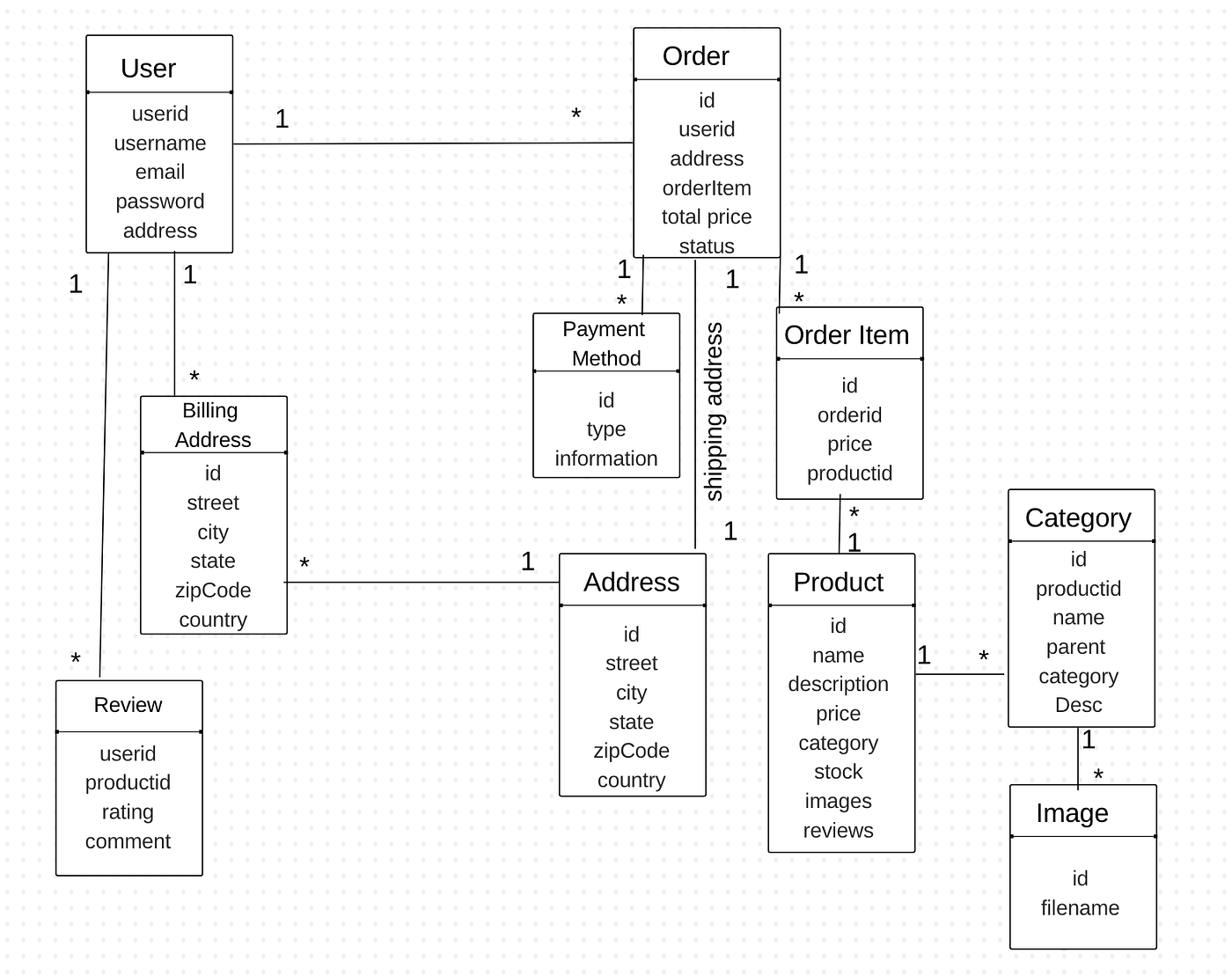
Image created by Author
How this model would work as aggregate in NoSQL world.
Key Value and document model
// in users
{
"user_123":{
"username":"arunadas",
"email":"aruna@mail.com",
"password":"WE14TG34UJH",
"billingAddress":[{"city":"Texas","country":"USA"}]
}
}
// in product
{
"product_456":{
"name":"phone",
"description":"samsung",
"price":"$786"
}
}
// in category
{
"category_789":{
"name" : "mobile",
"parent_category" : "electronics"
}
}
// in orders
{
"order_99":{
"user_id":123,
"orderItems":[
{
"productId":456,
"price": 786,
"productName": "samsung"
} ],
"shippingAddress":[{"city":"Chicago", "country":"USA"}],
"orderPayment":[
{
"ccinfo":"7865-5432-2134-8732", "txnId":"nherif542rft", "billingAddress": {"city": "Chicago"}
}],
"images":[{"glam"}],
"reviews":[{"user_id":123,"comment":"excellent"}]
}
}
Above is a very simple example of aggregates storing user , order and product information. If you need to answer how many orders by user above is not the best model for that you would need to add order id reference id to answer those questions. So think through your business needs to quering your data before deciding your data model.
Another example of above information can be stored as nested .
{
"user":{
"id":123,
"username":"arunadas",
"email":"aruna@mail.com",
"password":"WE14TG34UJH",
"billingAddress":[{"city":"Texas","country":"USA"}]
},
"orders":[{
"id":99,
"user_id":123,
"orderItems":[
{
"productId":456,
"price": 786,
"productName": "samsung"
} ],
"shippingAddress":[{"city":"Chicago", "country":"USA"}],
"orderPayment":[
{
"ccinfo":"7865-5432-2134-8732", "txnId":"nherif542rft", "billingAddress": {"city": "Chicago"}
}],
"images":[{"glam"}],
"reviews":[{"user_id":123,"comment":"excellent"}]
}]
}
// in product
{
"id":456,
"name":"phone",
"description":"samsung",
"price":"$786"
}
// in category
{
"id":789,
"name" : "electronics"
}
Now there is stark similarity between key value and document model in terms of they are stored with unique key and data . (Key : data) the only difference between two is with key — value you fetch {data} completely by giving a respective key whereas with document you have the ability to query the attributes within the {data} something like for given key fetch {data[price]} this is possible at document model but not in key-value.
Columnar model
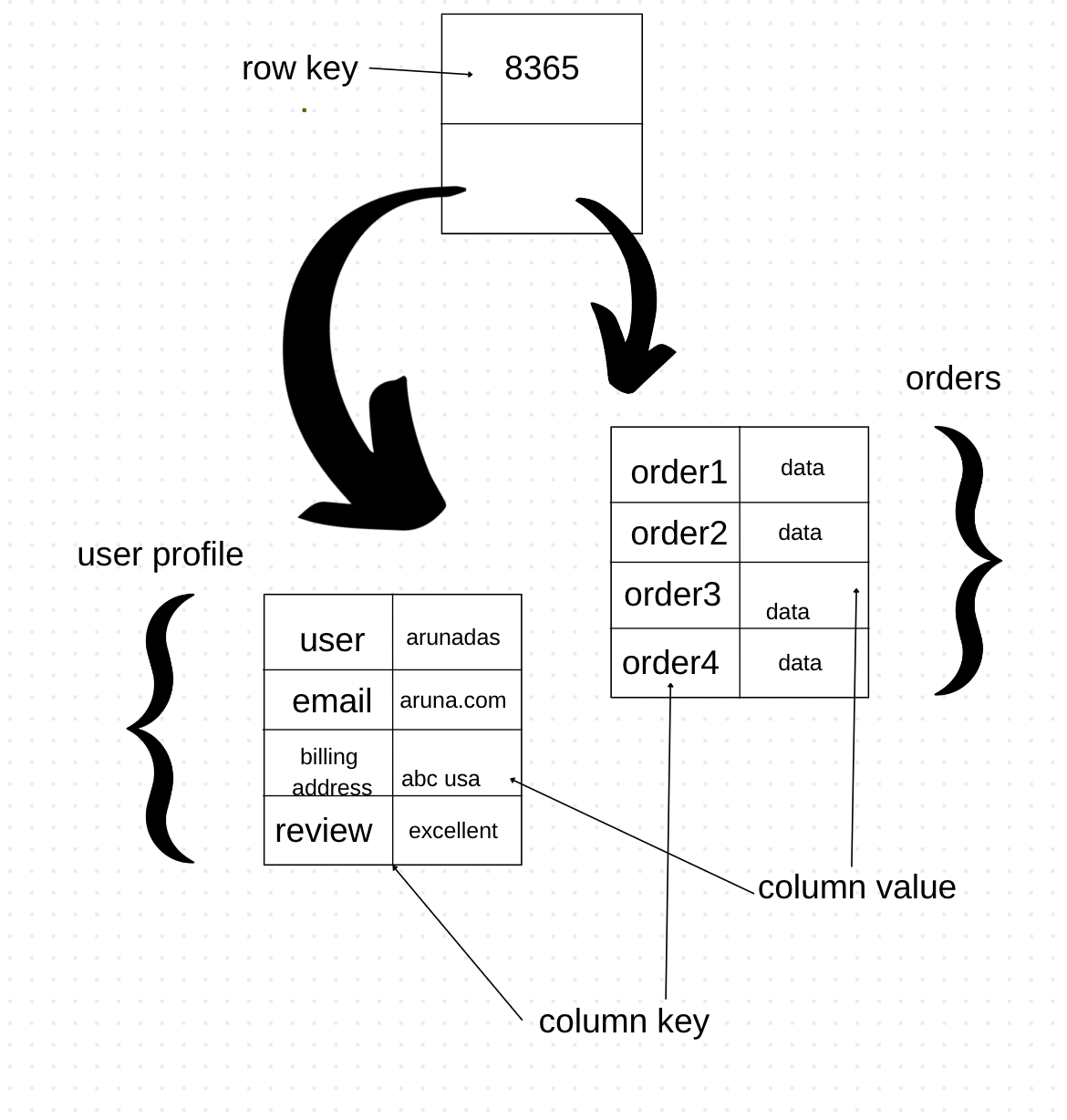
Image created by Author
Let’s move on to the third model column — family store. This model first appeared in Google’s Bigtable and later influenced many popular databases like HBase and Cassandra. The reason these databases differ is in how they store data physically. Typically, databases store data by rows to optimize write speed. However, there are scenarios where write operations are limited while reads are frequent for multiple columns across many rows simultaneously. In such cases, storing groups of columns for all rows becomes the basic storage unit. This characteristic distinguishes these databases as column stores.
You can think of a columnar database as having two levels of aggregates. As we saw in the key-value model, the first level is the key used to identify the row. Now, this row aggregate is a map of more detailed values. These second-level values are called columns. You can fetch all columns of the row aggregate or a specific one. For example, get('key', 'column_name'). So, get(8365, 'name') would return 'arunadas'.
Now, these aggregates, whether they are key-value, document, or columnar, can be as simple or complex with cascading nested aggregates as your business requirements dictate. This is something you will have to decide in the beginning during the design phase with your business partners.
Graph data model
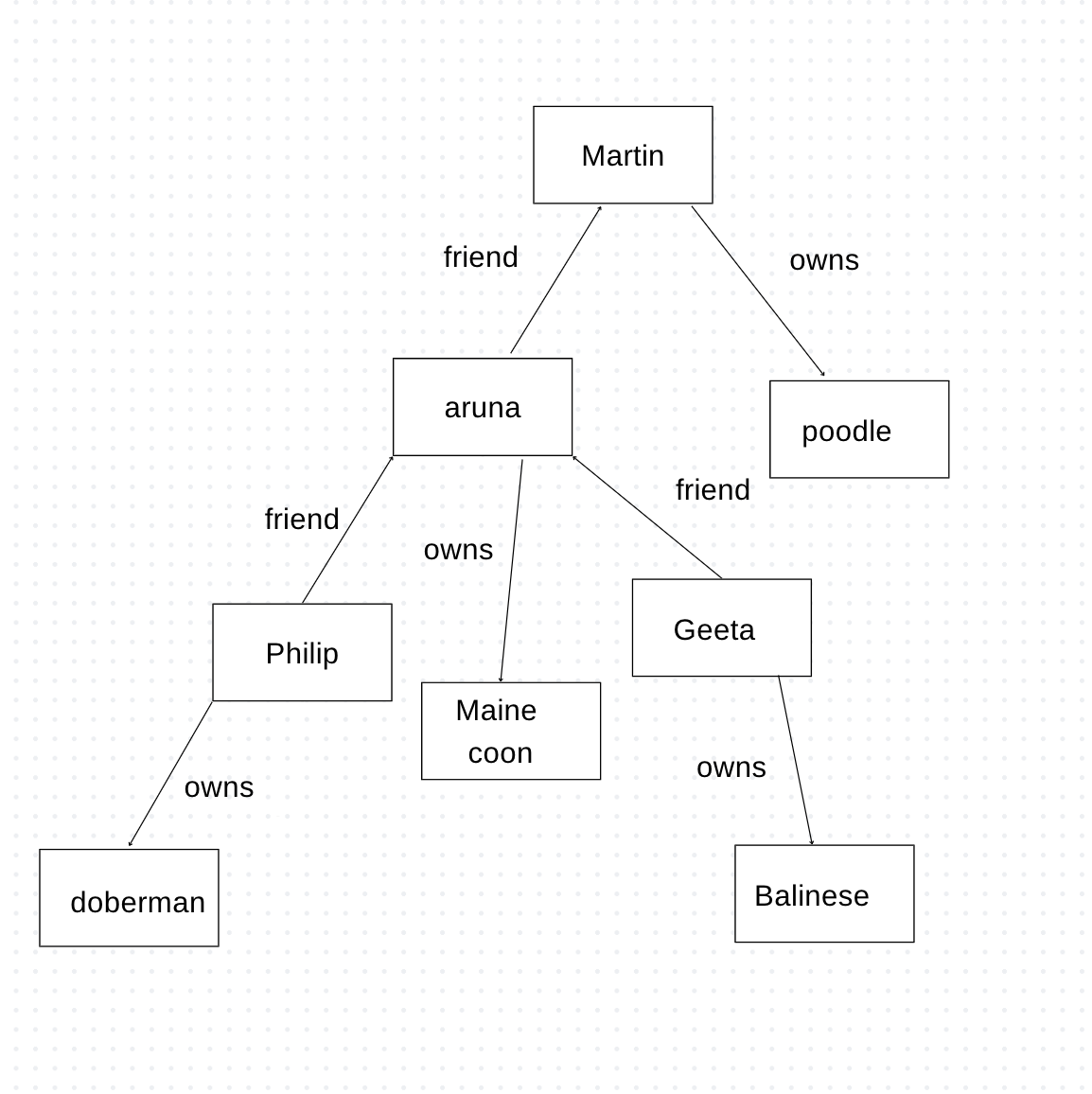
Image created by Author
The graph data structure differs from the above three models as its nodes are connected by edges. This model is particularly useful for answering questions such as which friend of Aruna has a poodle as a pet. Graph databases specialize in answering such questions. The fundamental data model of a graph is simple, nodes are connected by edges. However, there are variations beyond this baseline, especially in how the database decides the mechanism to store edges and nodes. For example, Neo4j allows attaching Java objects as properties to nodes and edges. Edges in a graph can be either directed or undirected. Directed edges have a specific direction, indicating a relationship from one node to another, while undirected edges represent symmetric relationships between nodes. Graphs allow for the representation of various types of connectivity patterns, including one-to-one, one-to-many, and many-to-many relationships between nodes.Graph databases are highly flexible and can represent complex and diverse data structures, including hierarchical, networked, and interconnected data.
Graph databases support efficient traversal of relationships between nodes, allowing for the exploration of interconnected data and the discovery of patterns and insights within the data.In addition to nodes and edges, graph databases often support the concept of properties, which are key-value pairs associated with nodes and edges. Properties can provide additional context and metadata about the entities and relationships in the graph.Graph databases often include built-in graph algorithms for analyzing and processing graph data, such as shortest path calculations, community detection, and centrality measures.Graph databases typically support specialized query languages optimized for traversing and querying graph data, such as Cypher for Neo4j or Gremlin for Apache TinkerPop.Graph databases are designed to scale horizontally to handle large volumes of interconnected data efficiently, making them suitable for applications with growing datasets and complex relationships.
All above four datamodels have a schemaless or flexible schema design, allowing for dynamic addition and modification of nodes, edges, and properties without predefined structures or constraints.
I’m diving deeper into Designing Data-Intensive Applications and will be sharing insights on specific whitepapers, concepts, and design patterns that capture my attention. If you’d like to join me on this exploration, consider following me to receive automatic notifications about my next article!
Subscribe to my newsletter
Read articles from Aruna Das directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aruna Das
Aruna Das
15 + years of IT experience as senior Data engineer based out of bay area California. I enjoy learning new things whether technical or otherwise. Hashnode is my journal of learning path... If you like any of the topics you are welcome to follow along ...