Graph Databases: To Use or not to use?
 Sachin Harpalani
Sachin Harpalani
Introduction
In today's interconnected world, data isn't just about rows and columns—it's about relationships. From social networks connecting friends and family to recommendation engines suggesting our next favorite movie, understanding these intricate connections is essential for unlocking the full potential of our data.
Enter graph databases—the specialized database designed to do just that.
In this blog post, we'll delve into the world of graph databases, exploring their unique features, typical use cases, and alternatives, to answer the question: To use or not to use?
Understanding Graph Databases

If this is you, don’t worry, we’ve got you covered. Let’s dive into understanding the basics.
Fundamentals
A graph database is a specialized, single-purpose platform used to create and manipulate data of an associative and contextual nature. The graph itself contains nodes, edges, and properties that come together to allow users to represent and store data in a way that relational databases aren’t equipped to do.
The main concept of a graph database system is a relationship. Relationships are defined as first-class citizens — this means everything you can do with all other elements can be done with a relationship. Data is related together in a graph to store a collection of nodes and edges, where the edges represent the relationship between nodes.
Relationships allow data within the system to be linked together directly. Querying relationships in a graph database is fast since they’re stored in a way that doesn’t change. You may also visualize them, which makes them great for deriving insights for heavily interconnected data.
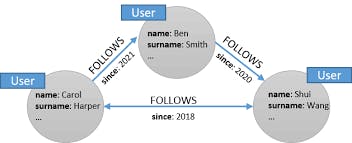
In this example: User are nodes that have properties name, surname and FOLLOWS is the relationship between the nodes which can have properties (like since ) of it’s own.
Now that we are done with the basics, let’s move on to the next segment
Use Cases of Graph Databases
1. Social Networks: Graph databases are ideal for modeling social networks, where users, friendships, likes, and interactions form a complex web of relationships. By representing users as nodes and connections between them as edges, graph databases facilitate efficient querying for friend recommendations, community detection, and content personalization.
2. Recommendation Engines: Graph databases power recommendation engines by analyzing user behavior, preferences, and item similarities to generate personalized recommendations. By modeling users, items, and their interactions as nodes and edges, graph databases enable efficient recommendation algorithms that can scale to millions of users and items.
3. Fraud Detection: Graph databases play a crucial role in fraud detection by identifying patterns of suspicious behavior within networks of transactions, users, and entities. By analyzing the flow of money and connections between accounts, graph databases can uncover fraudulent activities such as money laundering, identity theft, and insider fraud.
4. Network Analysis: Graph databases are widely used in network analysis applications, including transportation networks, telecommunications networks, and biological networks. By representing nodes as network elements and connections as edges, graph databases enable advanced analytics such as route optimization, network visualization, and gene pathway analysis.
5. Features involving Hierarchical data: In addition to the standard use cases mentioned earlier, graph databases offer flexibility for implementing custom business logic involving hierarchical relationships. Whether managing organizational charts, product categorizations, or any other nested data models, graph databases excel at representing and querying hierarchical relationships efficiently. This versatility allows businesses to implement bespoke solutions tailored to their unique requirements, empowering them to derive insights and make informed decisions based on the underlying data relationships.
Commonly used graph query languages
As graph databases gain traction, the number of graph query languages has exploded. This abundance of options can be quite daunting for developers. Navigating this ever-growing landscape can be challenging.
Let’s narrow those and take a quick look at some of the most commonly used graph query languages out there:
Cypher
Cypher is an open-source declarative query language developed by Neo4j for querying graph databases. It is part of the openCypher project, an open standard that aims to make Cypher available for use in various graph database systems, which has led to it being one of the most widely adopted query languages. Queries in Cypher are typically straightforward, beginning with the specification of a pattern to match and then permitting further refinements through filtering, aggregation, and other operations.
Gremlin
Developed as part of the Apache TinkerPop graph computing framework, Gremlin is notable for its language agnosticism, meaning it is not bound to a particular graph database system. Instead, Gremlin is compatible with various graph databases, making it a suitable choice for developers who require flexibility and want to work with multiple data sources.
GraphQL
GraphQL is a query language developed internally by Facebook in 2012 before being publicly released in 2015. It has gained significant popularity as an alternative to REST APIs. Unlike the other graph query languages discussed, GraphQL was designed for clients to query data from APIs and servers, not traditional graph databases. However, it shares similarities in its graph-structured queries.
Apart from these, there are more vendor-specific graph languages like AQL(ArrangoDB), GSQL(TigerGraph), nGQL(Nebula Graph) and many more.
Alternatives to Graph Databases
Even though graph databases excel at managing interconnected data, their implementation and maintenance can be a time-consuming and expensive endeavor. However, they're not the only game in town.
Several alternative approaches exist, each with its strengths and weaknesses. Let's explore some of these alternatives and how they stack up against graph databases.
1. Recursive Common Table Expressions (CTEs) in Relational Databases: Relational databases, such as PostgreSQL and SQL Server, offer support for recursive common table expressions (CTEs). This feature allows for recursive queries that can traverse hierarchical or graph-like structures within relational data models. By recursively joining tables with themselves, developers can perform graph traversals and pathfinding operations directly within SQL queries.
2. Caching Solutions like Redis or Memcached: Another approach to handling graph-like data involves leveraging caching solutions like Redis or Memcached. These in-memory key-value stores excel at storing and retrieving data with low latency, making them ideal for implementing algorithms like breadth-first search (BFS) on graph-like data structures. By caching intermediate results, developers can improve the performance of graph traversal operations, especially in scenarios with high read/write ratios or frequently changing data.
3. Apache Age: Apache Age is a distributed graph database built on top of PostgreSQL. It leverages the capabilities of PostgreSQL as a relational database while providing native support for graph data structures and operations. With Apache Age, users can store and query graph data using familiar SQL syntax, making it a compelling alternative for organizations already invested in PostgreSQL infrastructure.
4. pgRouting: pgRouting is an extension for PostgreSQL that adds routing functionality to the database, enabling users to perform complex routing and pathfinding operations on spatial data. While not a full-fledged graph database, pgRouting can be used to solve graph-related problems such as finding the shortest path between two points in a network. It offers a range of routing algorithms and functions, making it a valuable tool for applications requiring geospatial analysis and routing.
Trade-offs and Considerations

If you’re in this same dilemma, here are several factors to consider:
Performance: Graph databases are optimized for querying and traversing graph-like data structures, offering efficient graph algorithms and indexing mechanisms out of the box. In contrast, recursive CTEs in relational databases may suffer from performance limitations as the size of the dataset grows, while caching solutions may introduce overhead due to cache invalidation and synchronization.
Scalability: Graph databases are designed to scale horizontally to handle large and highly interconnected datasets. However, they may require specialized infrastructure and tuning to achieve optimal performance at scale. On the other hand, relational databases and caching solutions can also scale horizontally, but may face limitations in handling complex graph traversals efficiently.
Ease of Use: Graph databases typically offer high-level query languages and intuitive data modeling tools tailored specifically for graph data. This makes them easy to use for developers familiar with graph concepts. In contrast, leveraging recursive CTEs or caching solutions may require more advanced SQL skills or custom code to implement and maintain.
Pricing: Graph databases often come with pricing models that consider factors such as the volume of data stored, the number of transactions processed, and the level of support provided. While some graph databases offer community editions or open-source options with no upfront costs, others may require subscription-based licensing or usage-based pricing models. In contrast, relational databases and caching solutions may have different pricing structures, such as per-instance fees or pay-as-you-go pricing for cloud-based deployments. It's essential to consider the total cost of ownership, including licensing, infrastructure, and ongoing maintenance, when evaluating the pricing of graph databases and alternatives.
Documentation: While graph database vendors strive to provide comprehensive documentation, the quality and coverage may vary depending on the specific vendor. In contrast, alternatives such as relational databases often offer consistently well-established documentation that covers a wide range of use cases. The extensive documentation, backed by a large community, makes it easy for users to find resources and support for their projects.
Community Support: While graph databases have an active & growing community, they may not be as extensive as those surrounding alternatives like relational databases. Relational databases have been around for more years and are more mature, resulting in a larger and more established user base. This broad user base provides robust support, forums, and resources for users, ensuring a wealth of knowledge and assistance is readily available.
Conclusion
In the ever-evolving landscape of data management, the choice between graph databases and alternative approaches is not always straightforward. Each option offers its own set of advantages, trade-offs, and pricing considerations, making it essential to carefully evaluate your specific requirements and constraints before making a decision.
Graph databases shine in scenarios where complex relationships and graph-like data structures are prevalent, offering intuitive query languages, efficient graph traversal algorithms, and scalable infrastructure. However, it's important to note that they may come with significant upfront costs, making them a substantial investment for organizations. Additionally, utilizing graph databases effectively often requires specialized expertise, further adding to the overall cost of implementation and maintenance.
On the other hand, alternatives like recursive CTEs in relational databases and caching solutions like Redis or Memcached provide viable options for certain use cases, offering familiar SQL-based querying capabilities and low-latency data access. However, they may face performance limitations or scalability challenges when dealing with highly interconnected datasets.
When making your decision, consider factors such as performance, scalability, ease of use, and pricing, weighing the trade-offs against your specific application requirements. Whether you opt for the flexibility of graph databases, the familiarity of relational databases, or the speed of caching solutions, remember that the ultimate goal is to empower your organization with the right tools to derive insights and drive innovation from your data.
In the end, the best approach is one that aligns closely with your business objectives and enables you to extract maximum value from your data assets. So, choose wisely, and embark on your data journey with confidence, knowing that you've selected the optimal solution for your needs.
References
https://www.dylanpaulus.com/posts/postgres-is-a-graph-database/
Subscribe to my newsletter
Read articles from Sachin Harpalani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by