Chaos Engineering: Embracing Chaos to Build Resilient Systems
 Rakesh Vardan
Rakesh Vardan
Introduction
In today's rapidly evolving digital landscape, where systems are becoming increasingly complex and interconnected, ensuring the reliability and resilience of software applications is more critical than ever. In this quest for robustness, a new discipline called "Chaos Engineering" has emerged. Chaos Engineering is not about causing chaos, but rather a proactive approach to testing and strengthening systems by intentionally injecting controlled chaos into them. By embracing chaos, organizations can uncover vulnerabilities, improve their system's reliability, and ultimately deliver better experiences to their users.
The definition of ‘Chaos Engineering’ has been defined by various groups & organizations:
Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production. - principlesofchaos
Chaos Engineering goes beyond traditional (failure) testing in that it's not only about verifying assumptions. It helps us explore the unpredictable things that could happen, and discover new properties of our inherently chaotic systems. - Gremlin
Chaos engineering is the science behind intentionally injecting failure into systems to gauge resiliency – Harness
Understanding Chaos Engineering
Chaos Engineering is rooted in the idea that to build resilient systems, it is essential to actively test their behavior under adverse conditions. The approach draws inspiration from real-world experiences where systems fail due to unexpected circumstances, and aims to simulate those scenarios in a controlled environment.
Chaos Engineering is like a firefighter running practice drills. By intentionally setting controlled fires, the firefighters can understand how quickly it might spread, how effectively they can eliminate it, and what tactics work best under pressure. Similarly, Chaos Engineering believes in creating troublesome situations for a system to understand how it reacts. Just like the real world, where unexpected things can go wrong, these simulated conditions help find out the weak points in a system. By learning from these experiments, the organization can work on strengthening these weak areas, making the system more resilient and better equipped to deal with actual problems if they arise.

1 Image generated with Dall-E3
Similarly, Chaos Engineering tests systems under less-than-ideal conditions on purpose. It recreates situations where things could go wrong due to unanticipated circumstances. With this, organizations can see the weak points in their systems, and work to make them stronger and better equipped to handle such situations effectively in the future. The controlled environment ensures that while these tests are going on, the normal functioning of the system is not provoked into a real chaotic situation.
Chaos Engineering Principles
Chaos Engineering is guided by a set of core principles that drive its practice. Let's explore them briefly.
Start with establishing a steady state: This refers to defining normal behavior for your system to understand its expected outcomes better.
Hypothesize about what will happen: Chaos experiments begin with a clear hypothesis about how the system will behave under certain chaotic conditions. This hypothesis serves as a guide to identify potential vulnerabilities and expected outcomes.
Introduce variables that reflect real-world events: Chaos experiments should mirror factors that could likely occur within your production environment.
Attempt to disprove the hypothesis: By introducing controlled disruptions, you can test whether the system works as expected. If not, you will learn about a vulnerability.
Other principles include:
Define measurable outcomes: Chaos experiments should have measurable objectives and success criteria. This ensures that the results can be evaluated objectively and the impact of chaos can be quantified.
Focus on steady-state behavior: Chaos experiments primarily aim to test a system's behavior under normal operating conditions. The goal is to uncover weaknesses that might not surface during regular testing or in controlled environments.
Apply blast radius limits: To minimize the potential impact of chaos experiments, it is crucial to define the scope and boundaries. By limiting the blast radius, organizations can control the impact on the system and mitigate potential risks.
Automate where possible: Chaos experiments should be automated to enable repeatable, controlled chaos. Automation reduces human error, ensures consistency, and allows for scaling the chaos engineering practice.
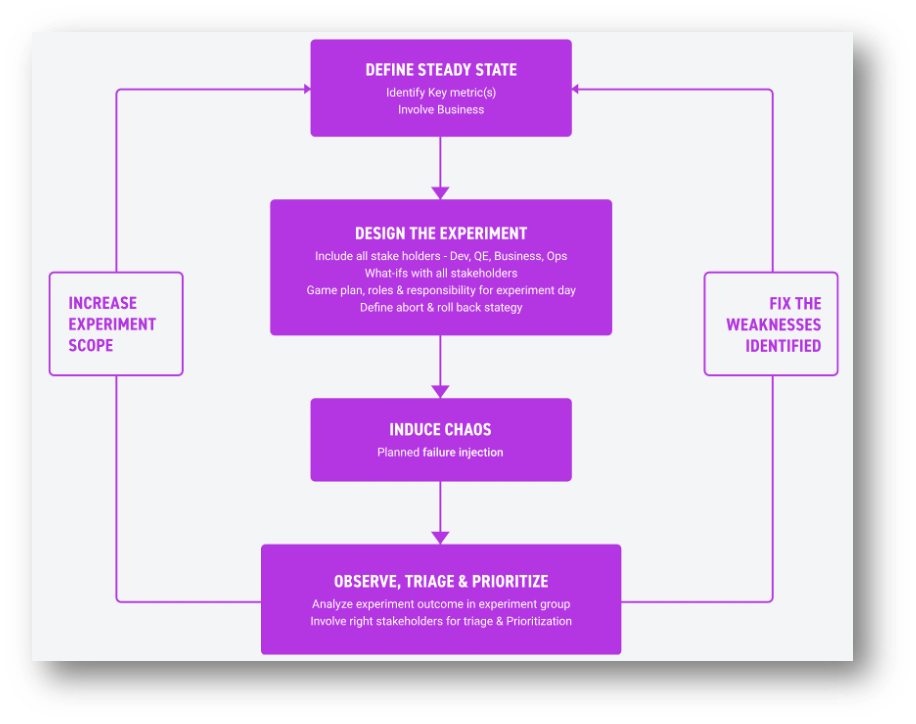
Source: Apexon Whitepaper on Chaos Engineering
Benefits of Chaos Engineering
Implementing Chaos Engineering as a proactive practice brings several benefits to organizations.
Improved system resilience: Early vulnerability and weak point identification allow companies to make the necessary changes to strengthen their systems. By identifying these weak spots before they become operational problems, chaos engineering contributes to the overall resilience of the system.
Reduced downtime and increased availability: Organizations can identify possible failure situations and take the necessary steps to prevent or recover from them by using chaos experiments. Organizations may reduce downtime and guarantee high availability for their clients by proactively identifying these issues.
Enhanced customer experience: Chaos Engineering contributes to more streamlined and dependable end-user experiences by proactively testing and fixing system flaws. It assists businesses in identifying any problems and acting upon them before they negatively affect the consumer experience.
Cultural shift towards resilience: Through a cultural shift, Chaos Engineering assists organizations in making resilience a priority. It educates groups to embrace difficulties and see flaws as chances for improvement. By promoting a culture of ongoing learning and development, this strategy creates systems that are more reliable and strong.
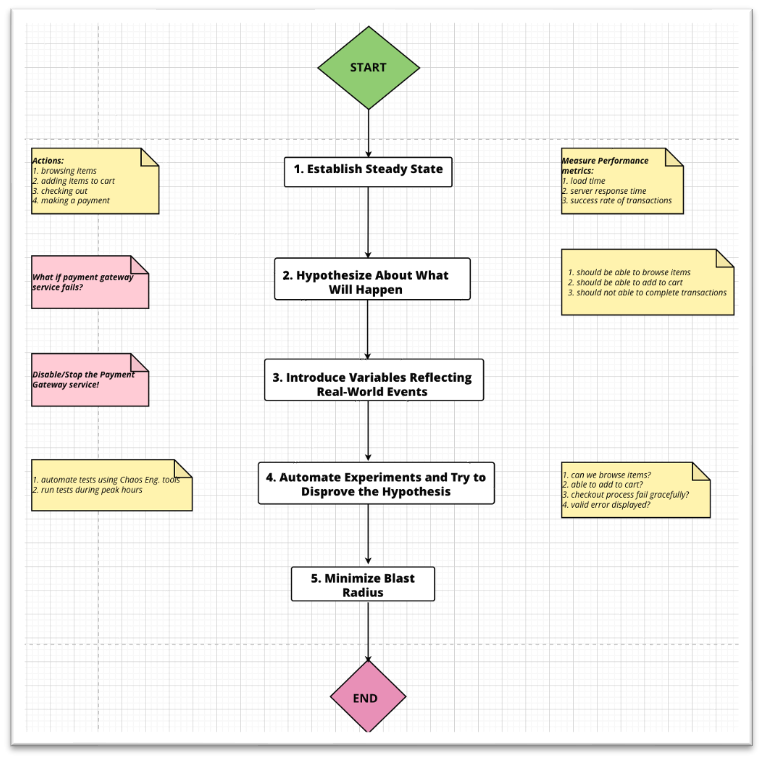
Let's use an eCommerce website as an example for demonstrating the Chaos Engineering principles.
1. Start with Establishing a Steady State: The normal operations of this eCommerce site might involve users browsing items, adding them to a cart, checking out, and making a payment. The performance metrics of these operations like load time, server response time, success rate of transactions, etc., in normal conditions, are recorded.
2. Hypothesize About What Will Happen: Let's hypothesize that if the payment gateway service were to fail, users would still be able to browse items and add them to their carts, but wouldn't be able to complete transactions.
3. Introduce Variables Reflecting Real-World Events: You simulate a real-world event - in this case, the failure of the payment gateway. This could be replicated by intentionally disabling the payment gateway service.
4. Automate Experiments and Try to Disprove the Hypothesis: You run the test automatically using chaos engineering tools during peak business hours when the web traffic is high. Observe what happens: Can users still browse and add items to their carts? Does the checkout process fail gracefully, with users receiving an appropriate error message?
5. Minimize Blast Radius: Instead of running this test in the live environment affecting all users, you first run it in a controlled environment, like a clone of your production environment, affecting a limited number of users. This ensures that in case the test reveals serious issues, your entire user base is not affected.
By following these principles, chaos engineering allows businesses to proactively identify and fix potential system weaknesses, ensuring that their services run smoothly, and customer experience is not disrupted, even in the event of unexpected system failures.
Real-time incidents
Here are a few notable incidents where a lack of chaos engineering has played a part in service disruption or application outage:
GitHub (October 21, 2018): GitHub went down for 24 hours due to data storage system failure. The direct cause was a network partition, which led to inconsistency across their data storage system. Chaos engineering practices could have helped detect such a vulnerability beforehand.
https://github.blog/2018-10-30-oct21-post-incident-analysis/
- Amazon (September 20, 2015) – Dynamo DB availability issue: Amazon's DynamoDB faced an availability issue in one of its regional zones, leading to the failure of more than 20 Amazon Web Services that depended on DynamoDB in that particular region. As a result, several websites, including Netflix, experienced downtime for a few hours. However, Netflix's outage was less severe compared to other sites, thanks to their foresight in creating and utilizing a chaos engineering tool known as Chaos Kong, which helped them prepare for such situations.
- Amazon AWS (February 28, 2017) – S3 service outage: A major outage in Amazon's S3 web service resulted in disruption for many online services. The outage was reportedly due to a command that was incorrectly entered during a routine debugging. Chaos engineering could have helped develop safeguards against such human errors.
Metrics to measure
Below are some metrics that can help measure the effectiveness of chaos engineering efforts and guide future experiments.
| Metric | Description |
| Mean Time to Recovery (MTTR) | The average time it takes to recover from a failure. |
| Failure Injection Rate | The rate at which failures are being injected into the system. |
| System Availability | The percentage of time that the system is available to users. |
| Error Rates | The rate at which the system is producing errors. |
| Performance Metrics (Response time, Throughput, Latency) | These metrics should remain stable while injecting failures into the system. |
| Incident Reports | The number of incidents reported can provide a measure of how often things go wrong. |
| Cost of Downtime | The cost associated with system downtime, including lost revenue and damage to the brand. |
| Service Level Indicators (SLIs) | Specific measures of a service's level of performance or reliability. |
| Service Level Objectives (SLOs) | Targets for the SLIs. |
| Chaos Experiment Success Rate | The percentage of chaos experiments that pass |
| Time to Detection (TTD) | The time it takes to detect a failure. |
| Escaped Failures | Failures that were not caught during chaos experiments and instead were found in production. |
| Number of New Issues Discovered | The number of new issues or vulnerabilities discovered during chaos experiments |
| User Impact | The impact of failures on users, such as the number of user complaints or the decrease in user activity during a failure. |
Tools and Technologies
Chaos Engineering has gained significant popularity as a proactive approach to building resilient systems. To effectively practice chaos engineering, various tools, and technologies have emerged to assist in creating controlled chaos experiments. Some of the most used tools are:
Chaos Monkey: Developed by Netflix
Gremlin: Developed by Gremlin Inc
Chaos Toolkit: An open-source project developed by ChaosIQ (now Reliably)
Litmus: Developed by MayaData & the open-source community
PowerfulSeal: Developed by Bloomberg
Chaos Mesh: Developed by PingCAP & incubating project at CNCF
Pumba: Developed by Alexei Ledenev
ToxiProxy: Developed by Shopify
Conclusion
Considering the current state of technology, chaos engineering is an essential topic that aids companies in creating robust systems despite growing complexity. By embracing chaos and conducting controlled experiments, organizations can find vulnerabilities, build resilience, and enhance user experience. As long as technology advances, businesses will be able to test and enhance their systems beforehand and make sure they can function even in the face of disorder by utilizing chaos engineering as a potent weapon.
Chaos engineering tools and technologies have significantly contributed to the adoption and practice of chaos engineering. Each tool mentioned above offers unique advantages and disadvantages, and the choice of tool depends on factors such as the organization’s specific requirements, existing infrastructure, and budget constraints. Regardless of the tool chosen, the adoption of chaos engineering practices can help organizations build more resilient systems, proactively identify weaknesses, and ultimately enhance the overall reliability and user experience of their applications.
Originally published at Wearecommunity-india-devtestsecops-community
Appendix:
Prompt used -> Visualize an intense scene where a female firefighter is in full gear, courageously running practice drills amidst roaring flames. The controlled fire is blazing intensely, illuminating the dusk sky. You also see a male firefighter in the background, coordinating operations over the radio. Include multiple firefighting vehicles like fire engines and water tenders, ready with their lights flashing, adding to the drama of the scenario. Capture the dedication of these professionals, their teamwork, and the adrenaline-filled atmosphere.
References:
Subscribe to my newsletter
Read articles from Rakesh Vardan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rakesh Vardan
Rakesh Vardan
I am a Software Development Engineer in Test (SDET) specializing in CI/CD processes, with a strong background in UI and API test automation. My expertise lies in designing robust testing frameworks that integrate seamlessly with CI/CD workflows, guaranteeing software quality and reliability.