Traversing Semantic Spaces: Exploring Search Techniques in Word Embeddings
 Saurabh Naik
Saurabh Naik
Introduction:
In the vast landscape of natural language processing, efficient search methodologies are paramount for retrieving relevant information from word embeddings. In this technical blog, we embark on a journey through various search algorithms tailored for word embeddings, unraveling the intricacies of brute force search, approximate nearest neighbor, navigable small world, and hierarchical navigable small world. From understanding the fundamental principles to exploring practical implementations, we delve into the mechanisms that underpin these algorithms, shedding light on their strengths and limitations in semantic search tasks.
Brute Force Search Algorithm:
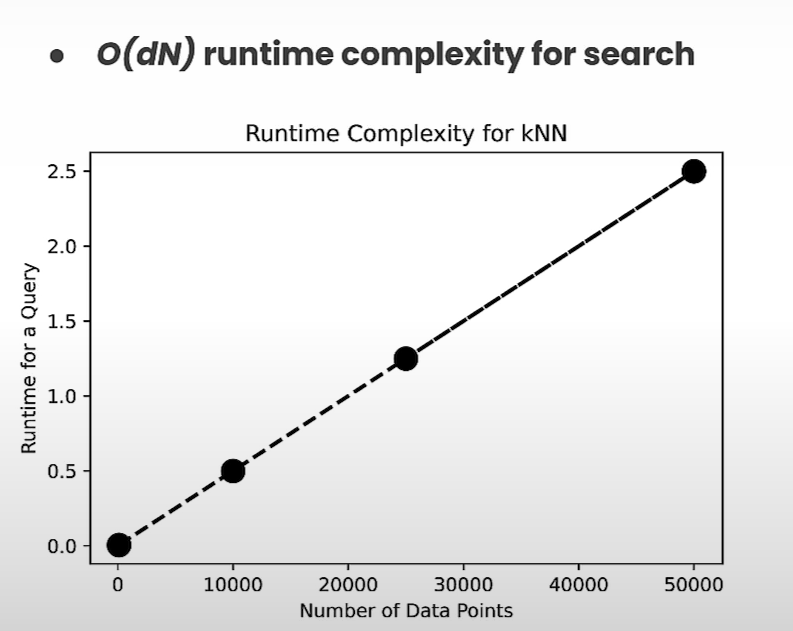
Traditionally known as K-nearest neighbor, brute force search involves exhaustive computation of distances between all vectors and a query vector. The process entails measuring distances, sorting them, and returning the top-k matches, representing the most semantically similar points. While effective, this approach is computationally intensive, making it impractical for large-scale applications.
Step involved in brute force search:
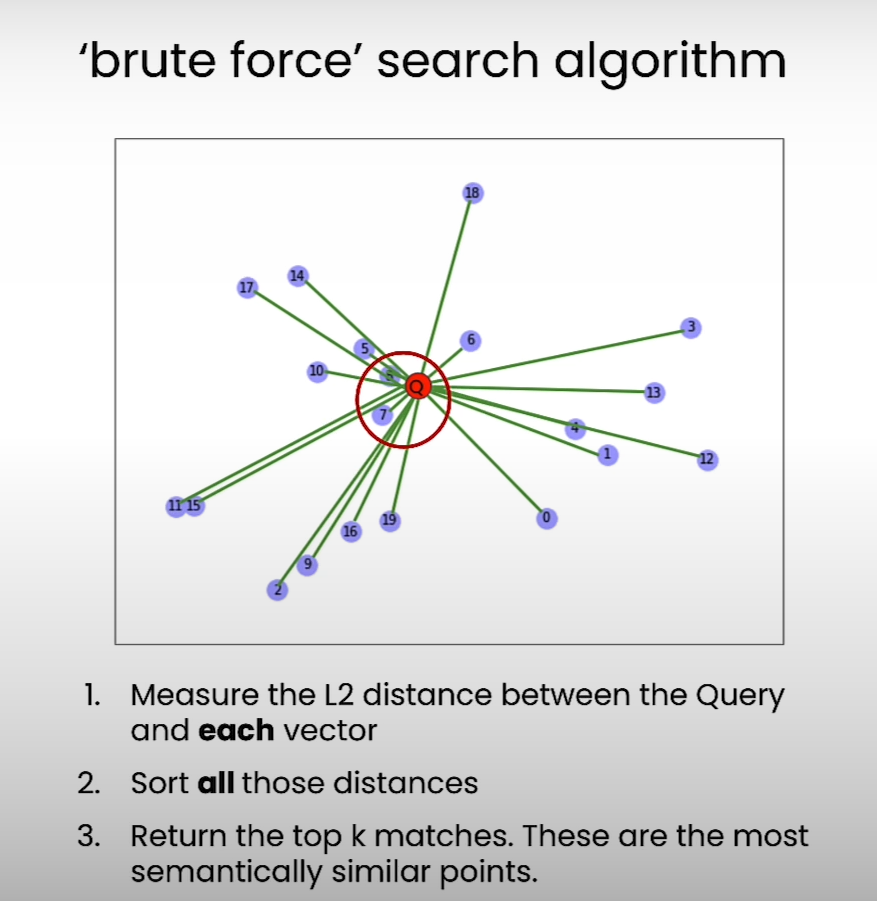
Measure the distances between all the vectors and the query vector
Sort out all these distances
Return all the top k matches. These are the most semantically similar points.
Approximate Nearest Neighbor:
Addressing the computational overhead of brute force search, approximate nearest neighbor algorithms leverage intuitive connections to expedite search processes. By exploiting indirect associations akin to knowing someone who knows a celebrity, these algorithms offer faster retrieval of semantically similar vectors.
Navigable Small World:
Navigable small world algorithms construct a network of interconnected vectors, facilitating efficient navigation through semantic spaces. By iteratively adding vectors and establishing connections based on proximity, these algorithms enable quick traversal towards semantically relevant points, enhancing search performance.
Steps to build navigable small world:
We start with any point for example point 0 in this example. Then we find the nearest 2 points in the network. But there are no other vector.
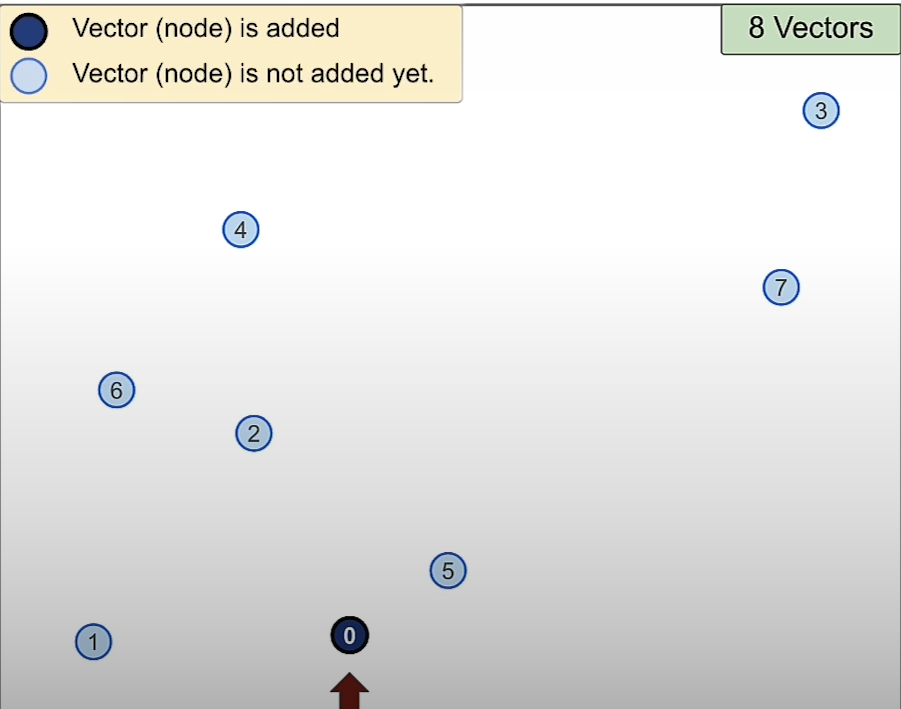
So we will consider the next node 1. Then we create a network between 0 and 1.
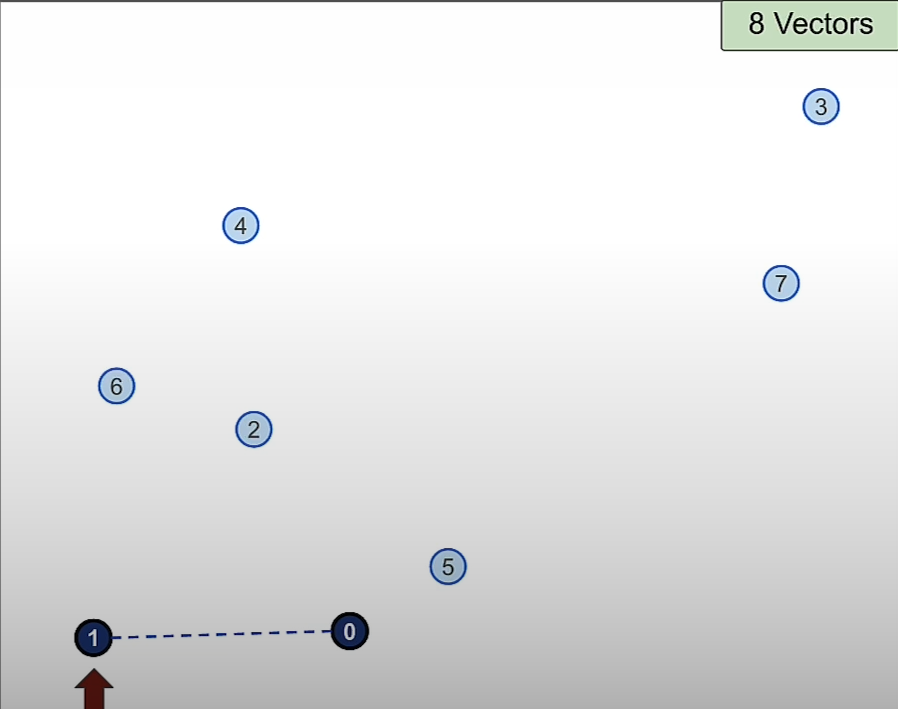
Then we will add vector 2 and build connection between vector 0 and 1.
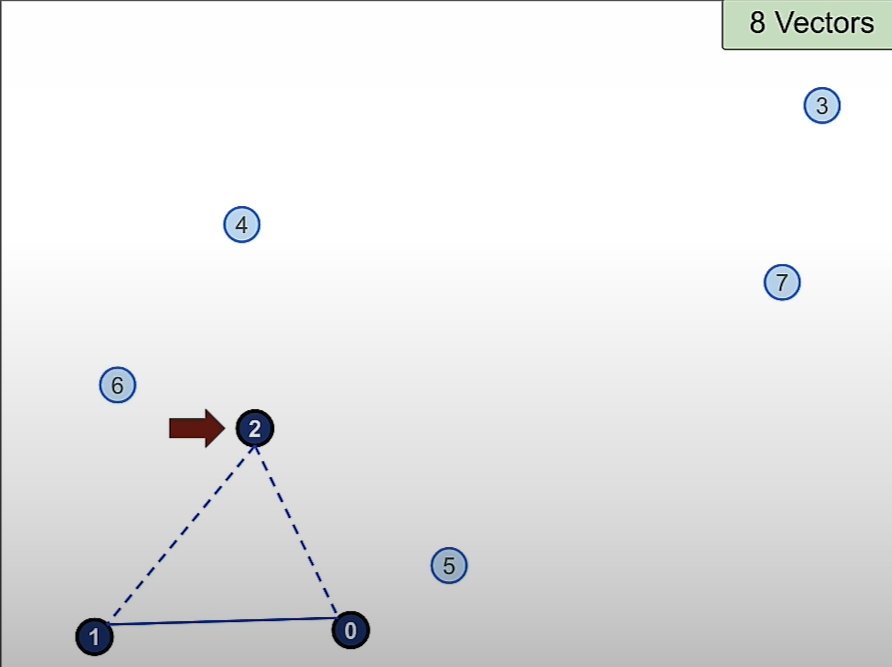
Then we add vector 3 and the 2 nearest connection to it are Vector 2 and 0.
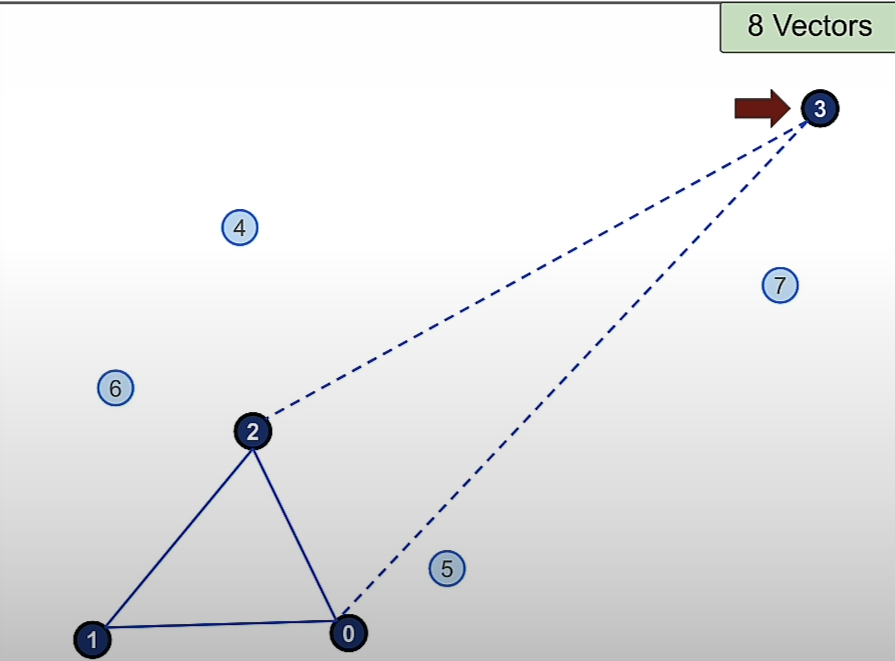
Then we add vector 4 and the 2 nearest connection to it are 2 and 0.
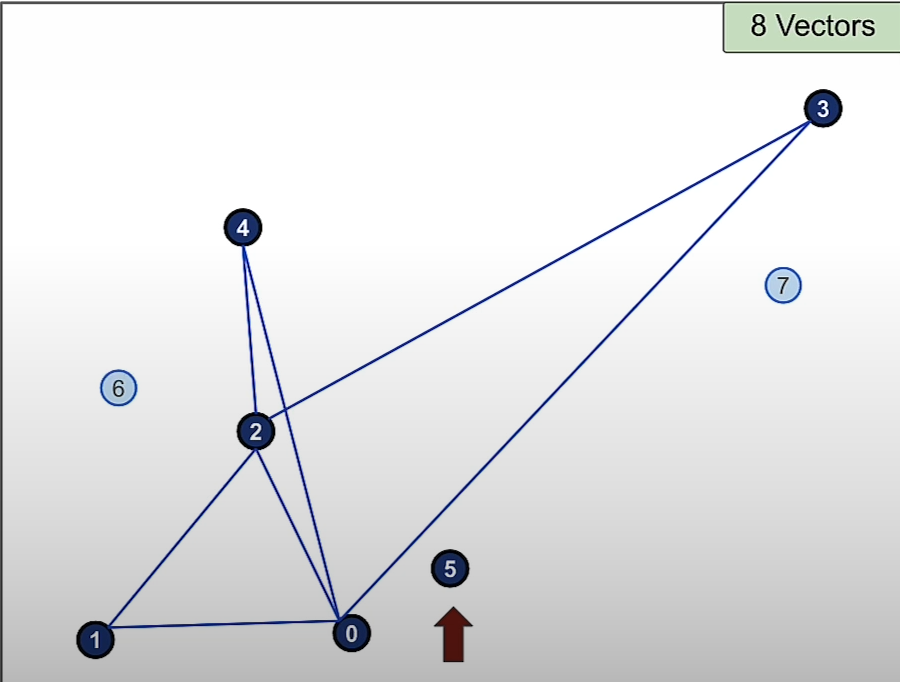
Then we add vector 5 and the 2 nearest connections to it are 2 and 0.
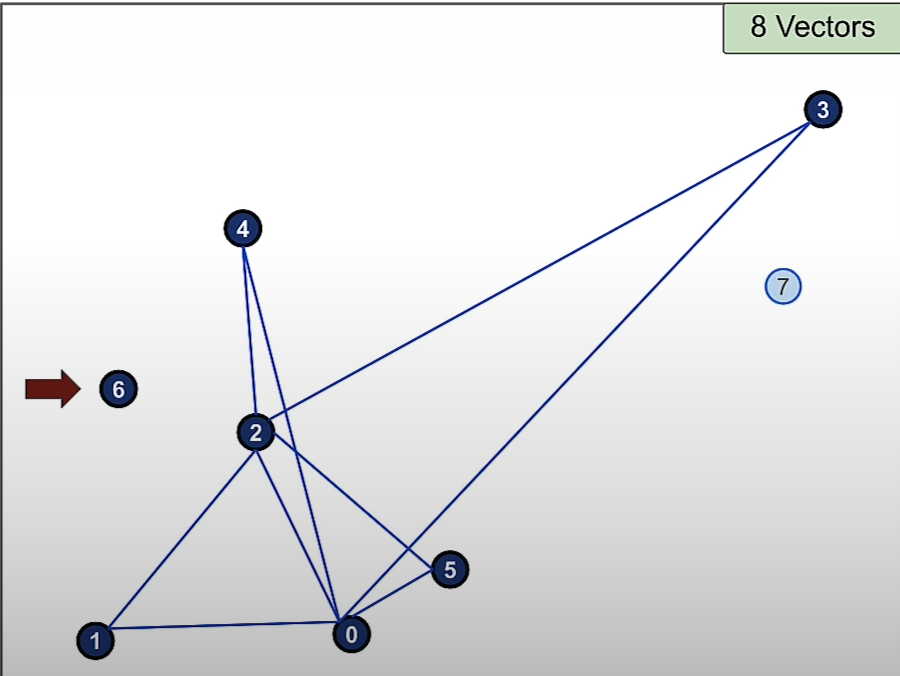
Then we add vector 6 and the 2 nearest connections to it are 2 and 4.
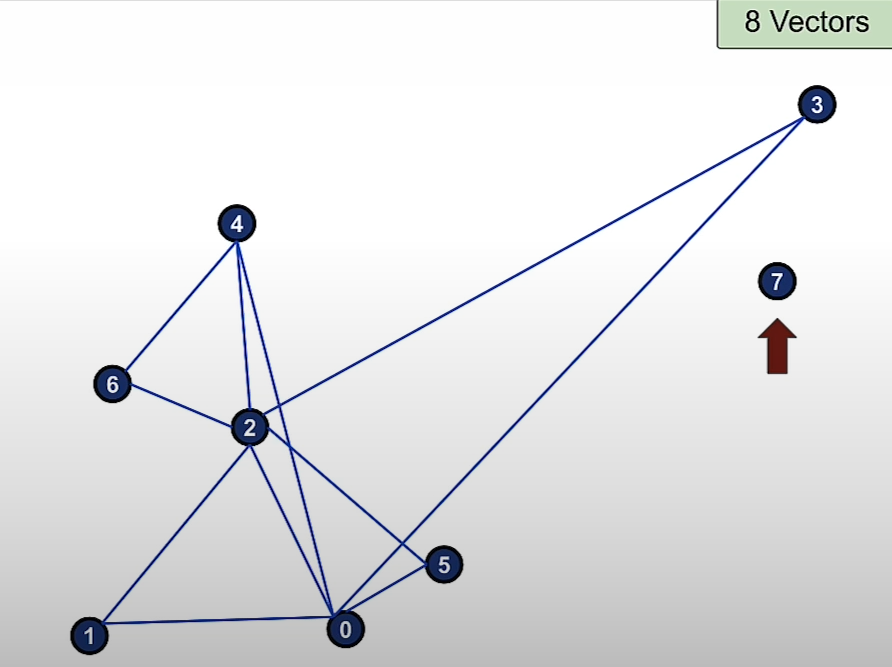
Then we add vector 7 and the 2 nearest connections to it are 5 and 3.
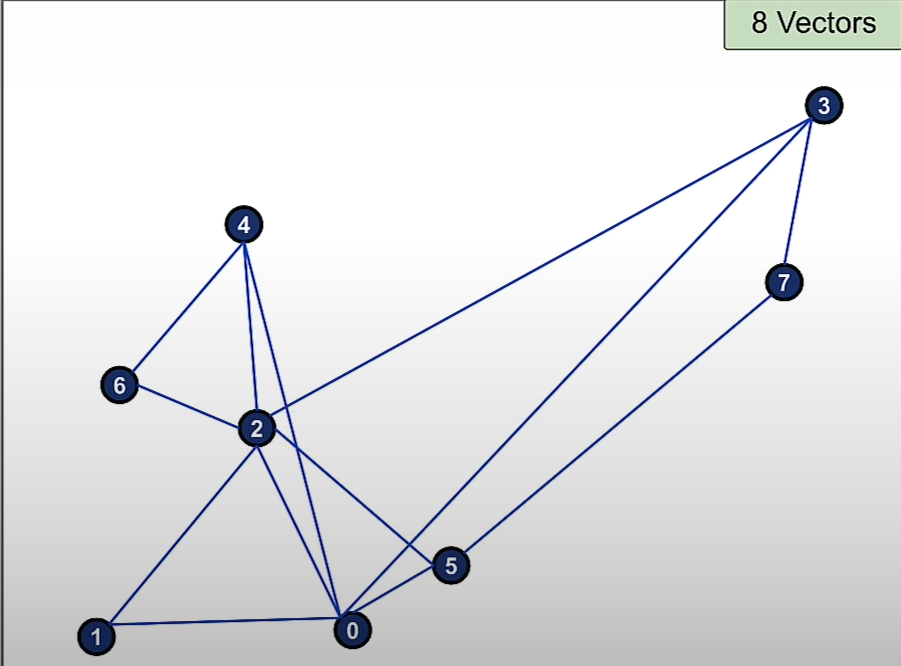
How search works:
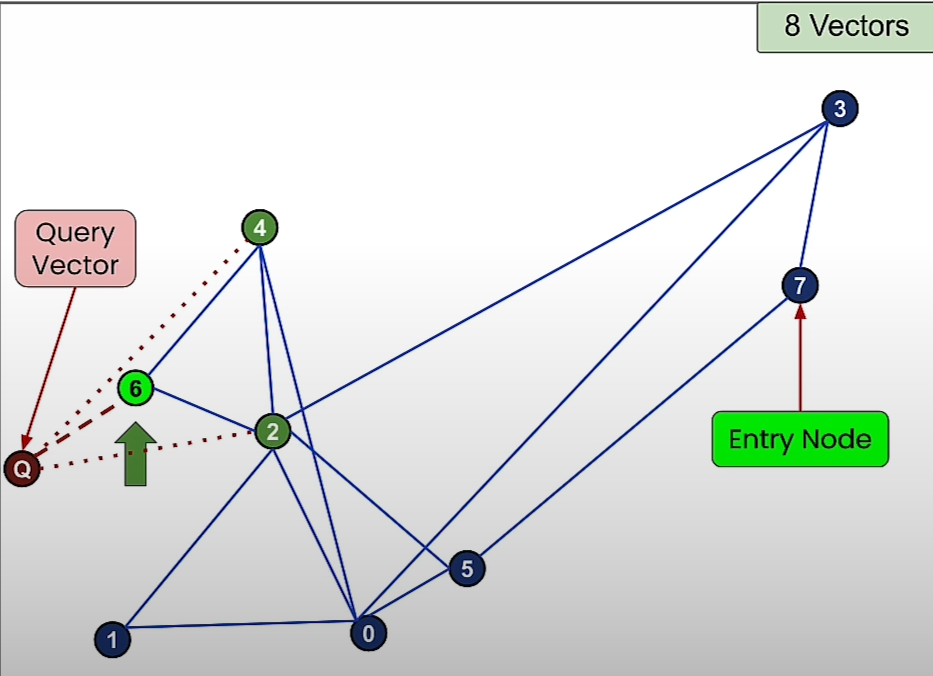
Now consider that query vector is Q as shown in the diagram.
We start with a random entry node and then we move towards a node that is closer to the query vector.
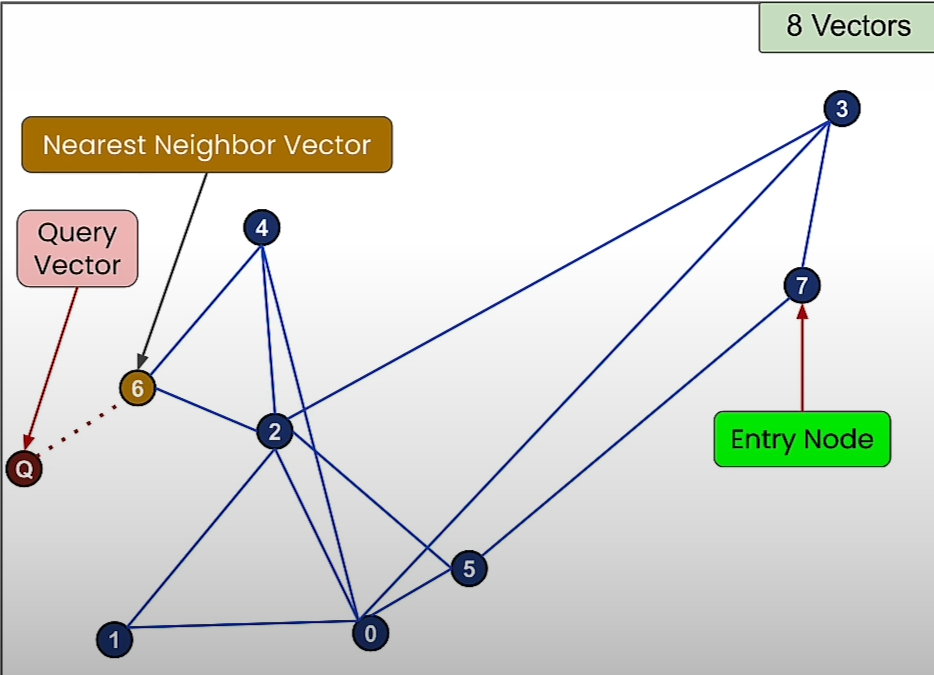
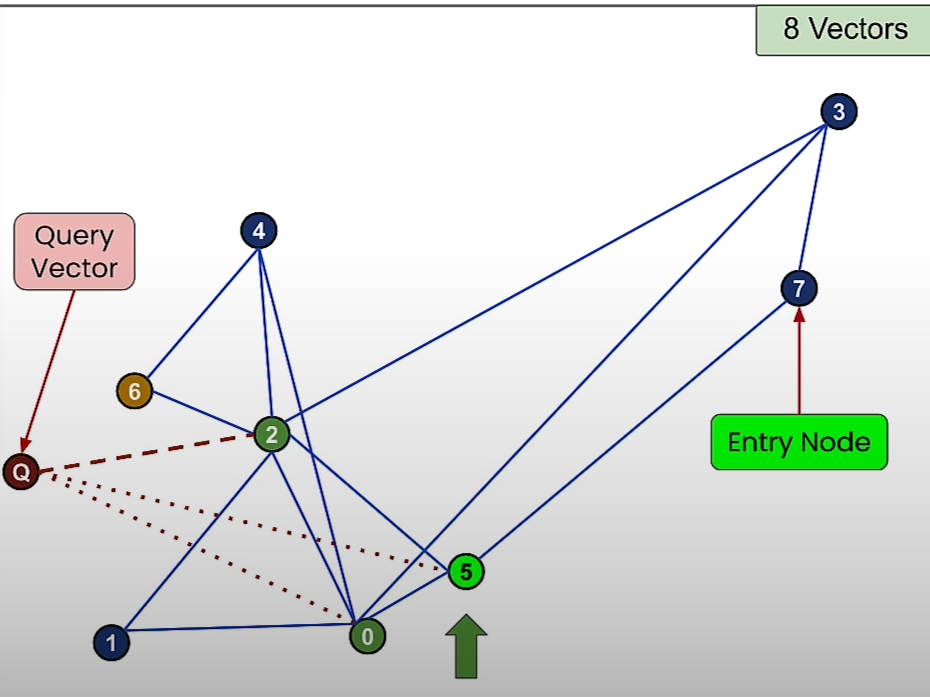
Then we move towards the node that is more closer to the query vector.
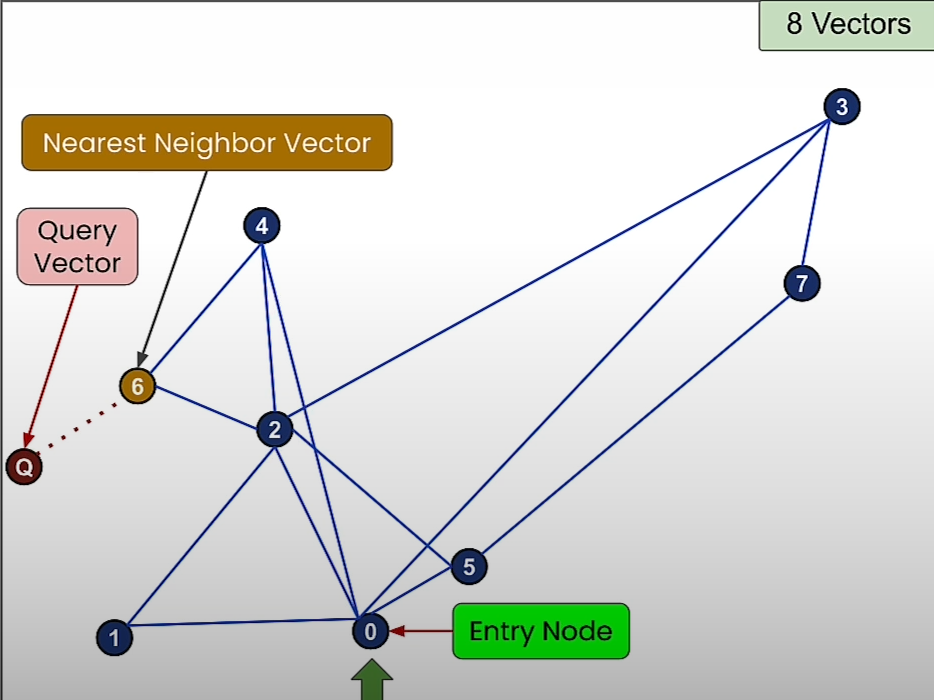
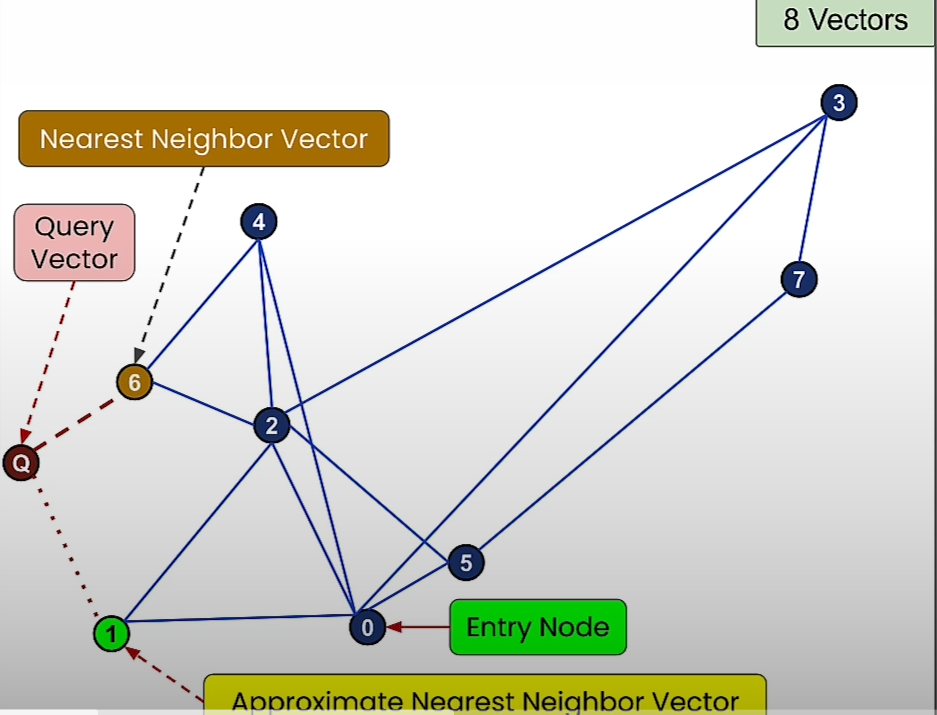
Sometimes we may not get to the closest node to the query vector.
Hierarchical Navigable Small World:
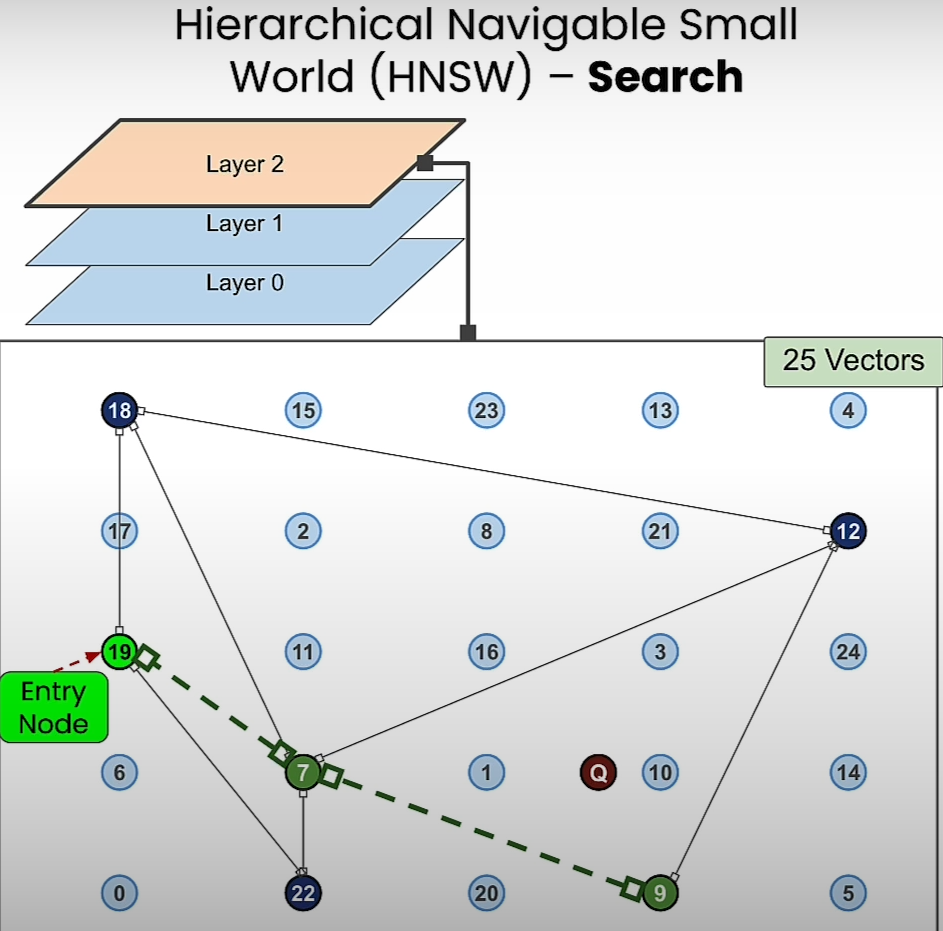
Building upon the foundation of navigable small world, hierarchical navigable small world introduces a layered approach to search. By stacking multiple navigable small world graphs atop each other, this algorithm optimizes search efficiency by traversing from higher-level layers to lower-level ones, reducing query time logarithmically.
Summary:
In the quest for efficient semantic search in word embeddings, understanding the nuances of various search algorithms is imperative. Brute force search offers accuracy but suffers from computational overhead, while approximate nearest neighbor algorithms expedite search processes through intuitive associations. Navigable small world algorithms enhance search efficiency by constructing interconnected networks, and hierarchical navigable small world further optimizes performance through layered traversal. By leveraging these techniques, practitioners can navigate semantic spaces effectively, unlocking the full potential of word embeddings in natural language processing tasks.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com