BLOOM: An In-Depth Guide for the Multilingual Large Language Model
 NovitaAI
NovitaAI
Delve into BLOOM, a multilingual large language model, examining its development, technical specifications, applications, and ethical considerations aimed at democratizing AI.
Background
The emergence of large language models (LLMs) has profoundly shaped the landscape of Natural Language Processing (NLP), finding widespread application across various domains. However, their development has primarily been confined to resource-rich organizations, creating an exclusivity barrier that limits public access.
This situation prompts a crucial inquiry: What if there were a means to democratize access to these potent language models? Enter BLOOM.
This article offers a comprehensive overview of BLOOM, beginning with its origins and then delving into its technical intricacies and usage guidelines. It also addresses its constraints and ethical implications.
What is BLOOM?
BLOOM, short for BigScience Large Open-science Open-access Multilingual Language Model, signifies a significant stride towards democratizing language model technology.

Crafted through a collaborative effort involving over 1200 contributors from 39 nations, including a substantial contingent from the United States, BLOOM exemplifies a truly global endeavor. Spearheaded by BigScience in conjunction with Hugging Face and the French NLP community, this initiative transcends geographical and institutional boundaries.
This open-source decoder-only transformer model boasts 176 billion parameters and draws its training data from the ROOTS corpus — a vast compilation encompassing hundreds of sources across 59 languages, comprising 46 spoken languages and 13 programming languages.
Below is the piechart of the distribution of the training languages:

Notably, BLOOM has demonstrated exceptional performance across diverse benchmarks, with further enhancements achieved through multitask prompted fine-tuning.
The culmination of this endeavor was a rigorous 117-day training regimen (March 11 — July 6) conducted on the Jean Zay supercomputer in Paris, supported by a substantial compute grant from French research agencies CNRS and GENCI.
Beyond its technological prowess, BLOOM serves as a testament to international collaboration and the collective pursuit of scientific advancement.
Component of BLOOM
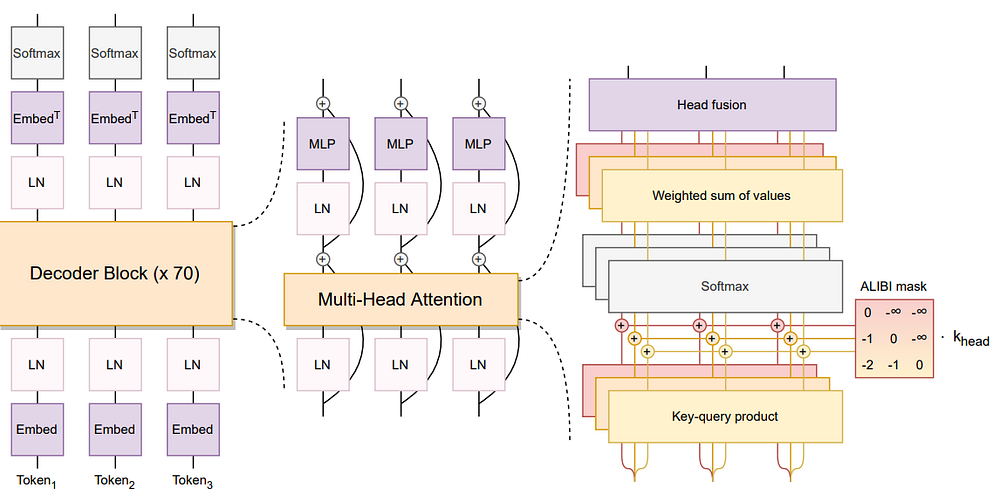
The BLOOM model’s components, as outlined in the paper, encompasses several notable elements:
Design Methodology: The team prioritized scalable model families compatible with publicly accessible tools and codebases. They conducted ablation experiments on smaller models to refine components and hyperparameters, with zero-shot generalization serving as a pivotal metric for assessing architectural choices.
Architecture and Pretraining Objective: BLOOM adopts the Transformer architecture, specifically a causal decoder-only model. This approach was deemed the most effective for achieving zero-shot generalization capabilities, surpassing encoder-decoder and other decoder-only architectures.
Modeling Details:
ALiBi Positional Embeddings: ALiBi, chosen over traditional positional embeddings, directly modulates attention scores based on key-query distance, fostering smoother training and enhanced performance.
Embedding LayerNorm: An additional layer normalization was integrated immediately following the embedding layer, enhancing training stability. This decision was influenced in part by the utilization of bfloat16 in the final training, known for its greater stability compared to float16.
These components underscore the team’s endeavor to strike a balance between innovation and established techniques to optimize the model’s performance and stability.
In addition to the architectural components, two further relevant aspects are:
Data Preprocessing: This entailed crucial steps such as deduplication and privacy redaction, particularly for sources with heightened privacy concerns.
Prompted Datasets: BLOOM utilizes multitask prompted finetuning, renowned for its robust zero-shot task generalization capabilities.
How to Use BLOOM
To ensure efficient utilization of resources, proper workspace configuration is essential for the BLOOM model. The primary steps involved are outlined below.
Initially, the transformer library is employed to furnish interfaces facilitating interaction with the BLOOM model, as well as other transformer-based models in a broader context.
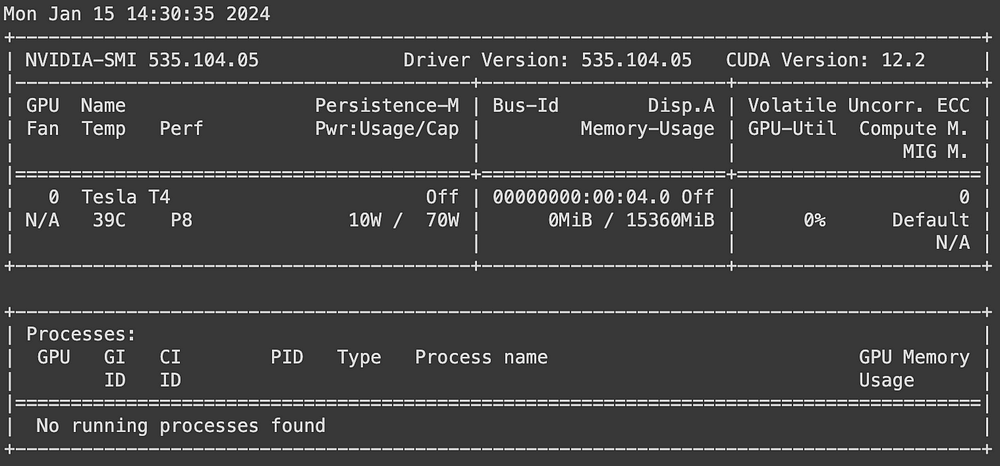
Using nvidia-smi, we check the properties of the available GPU to ensure we have the necessary computational resources to run the model.
Modules necessary for the operation are imported from transformers and torch libraries. torch is specifically utilized for configuring the default tensor type, thereby harnessing the GPU acceleration.
Subsequently, given the GPU utilization, the torch library is configured using the set_default_tensor_type function to guarantee GPU utilization.
Get Access to the BLOOM Model
The targeted model is the 7 billion parameter BLOOM model, which is accessible from BigScience’s Hubbing Face repository under bigscience/bloom-1b7, corresponding to its unique identifier.
Next, we retrieve the pretrained BLOOM model and tokenizer from Hugging Face, and ensure reproducibility by setting the seed using the set_seed function with any non-floating value. Although the specific value chosen for the seed doesn’t matter, it’s crucial to use a non-floating value.
Moreover, for data engineers interested in LangChain’s applications in data engineering, our article “Introduction to LangChain for Data Engineering & Data Applications” offers insights into utilizing LangChain. It covers the problems LangChain addresses and provides examples of data use cases.
Finally, we tokenize the prompt and map to the appropriate model device before generating the model’s result after decoding.
With a few lines of code, we were able to generate meaningful content using the BLOOM model.
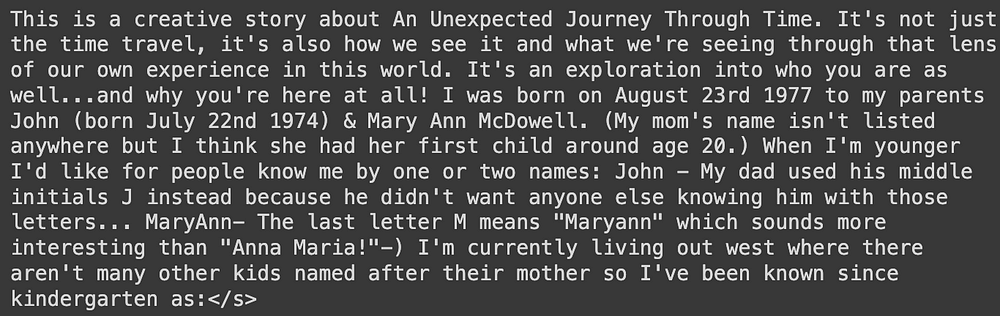
Story generated using BLOOM model
Use Cases and Applications of BLOOM
As with any technological innovation, BLOOM has its array of suitable and unsuitable applications. This segment examines its apt and inappropriate use cases, emphasizing areas where its capabilities can be optimally leveraged and where caution is warranted. Grasping these limitations is paramount for responsibly and efficiently harnessing BLOOM’s potential.
Intended Uses of BLOOM
Multilingual Content Generation: With proficiency in 59 languages, BLOOM excels in crafting varied and inclusive content. This attribute holds significant value in global communication, education, and media sectors, where linguistic inclusivity is paramount.
Coding and Software Development: BLOOM’s training in programming languages positions it as a valuable asset in software development endeavors. It can aid in tasks ranging from code generation to debugging, serving as an educational aid for novice programmers.
Research and Academia: Within academic realms, BLOOM serves as a potent resource for linguistic analysis and AI research, offering insights into language patterns, AI behavior, and beyond.\
Natural Language Processing: BLOOM can integrate with other Large Language Models (LLMs) and be used in conjunction with them for various natural language processing tasks. Integration with other LLMs can provide additional diversity, flexibility, and enhanced performance in language-related applications.
Here is an example of a successful integration with between BLOOM and novita.ai:
Out-of-scope uses of BLOOM
Sensitive Data Handling: BLOOM is not tailored for processing sensitive personal data or confidential information. The potential for privacy breaches or misuse of such data renders it unsuitable for such purposes.
High-Stakes Decision Making: Employing BLOOM in contexts demanding precise accuracy, such as medical diagnostics or legal decisions, is not advisable. The model’s inherent limitations, akin to most large language models, may result in erroneous or misleading outcomes in these critical areas.
Human Interaction Replacement: BLOOM should not be regarded as a substitute for human interaction, particularly in fields requiring emotional intelligence, like counseling, diplomacy, or personalized teaching. The model lacks the nuanced understanding and empathy inherent in human interaction.
Targeted Users of BLOOM
Developers and Data Scientists: Professionals in software development and data science rely on BLOOM for tasks such as coding assistance, debugging, and data analysis, enhancing their productivity and efficiency.
Researchers and Academics: Linguists, AI researchers, and academics utilize BLOOM for language studies, AI behavior analysis, and the advancement of NLP research, contributing to the academic discourse and scientific progress.
Content Creators and Translators: Writers, journalists, and translators harness BLOOM for generating and translating content across multiple languages, bolstering their creative output and widening their audience reach.
Businesses and Organizations: Companies across various sectors benefit indirectly from BLOOM’s capabilities, experiencing improved AI-driven services, enhanced customer interactions, and streamlined data handling processes, thereby fostering business growth and innovation.
Educational Institutions: Students and educators alike benefit from BLOOM through educational tools and resources incorporating its language processing capabilities, facilitating enhanced learning experiences and teaching methodologies.
Limitations and Ethical Considerations
Deploying BLOOM, akin to any Large Language Model (LLM), necessitates grappling with a spectrum of ethical considerations and limitations. Comprehending these facets is imperative for responsible utilization and for foreseeing the broader ramifications of the technology. This section delves into the ethical implications, risks, and intrinsic limitations entailed in deploying BLOOM.
Ethical considerations
Data Bias and Fairness: A primary ethical concern revolves around the potential for BLOOM to perpetuate or exacerbate biases inherent in its training data. This can compromise the fairness and impartiality of its outputs, presenting ethical dilemmas in contexts where unbiased processing is paramount.
Privacy Concerns: While BLOOM isn’t explicitly designed for handling sensitive personal information, the sheer breadth of its training data may inadvertently encompass such data. There’s a risk of privacy breaches if BLOOM generates outputs based on or revealing sensitive information.
Limitations of BLOOM
Contextual Understanding: Despite its sophistication, BLOOM may lack the nuanced contextual and cultural comprehension required for certain tasks, potentially resulting in inaccuracies or inappropriate outputs in nuanced scenarios.
Evolving Nature of Language: BLOOM’s training on a static dataset means it may struggle to keep pace with the dynamic nature of language, including new slang, terminology, or cultural references.
Significance and Controversies
The development and release of BLOOM carry substantial real-world implications, encompassing both its impact and the controversies it engenders. This section delves into these dimensions, drawing insights from the BLOOM research paper.
Real-world impact of BLOOM
Democratization of AI Technology: BLOOM signifies a stride towards democratizing AI technology. Developed by BigScience, a collaborative endeavor involving over 1200 individuals from 38 countries, BLOOM is an open-access model trained on a diverse corpus spanning 59 languages. This inclusive participation and accessibility contrast with the exclusivity often associated with large language model development.
Diversity and Inclusivity: The project’s dedication to linguistic, geographical, and scientific diversity is noteworthy. The ROOTS corpus utilized for BLOOM’s training encompasses a wide array of languages and programming languages, reflecting a commitment to inclusivity and representation in AI development.
Controversies and challenges
Social and Ethical Concerns: The development of BLOOM acknowledges the social constraints and ethical dilemmas inherent in large language model development. The BigScience workshop implemented an Ethical Charter to steer the project, prioritizing inclusivity, diversity, openness, reproducibility, and responsibility. These principles were woven into various facets of the project, from dataset curation to model evaluation.
Environmental and Resource Concerns: The emergence of large language models like BLOOM has sparked environmental concerns due to the substantial computational resources required. The training of these models, typically feasible only for well-resourced organizations, carries implications for energy consumption and carbon footprint.
Conclusion
BLOOM stands as a groundbreaking advancement in natural language processing, offering a versatile tool with far-reaching applications across diverse sectors. Its collaborative development underscores a commitment to democratizing AI technology and promoting inclusivity in language model development. However, ethical considerations, including data bias and privacy concerns, must be addressed to ensure responsible usage. Despite these challenges, BLOOM holds immense potential to drive innovation and progress in multilingual content generation, software development, research, and education. By embracing principles of inclusivity and responsibility, the BLOOM project sets a standard for ethical AI development. As we navigate the complexities of deploying large language models like BLOOM, a proactive approach is essential to harness its transformative capabilities while mitigating risks.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Subscribe to my newsletter
Read articles from NovitaAI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by