Exploring Vector Databases: Part 2 - Building Hybrid Search, Facial Similarity Search, and Anomaly Detection with Pinecone
 Saurabh Naik
Saurabh Naik
Introduction:
Continuing our exploration of vector databases, we delve into three additional applications that leverage the capabilities of Pinecone. In this blog, we unravel the intricacies of Hybrid Search, Facial Similarity Search, and Anomaly Detection, demonstrating how Pinecone enables the creation of sophisticated systems for diverse use cases. Through step-by-step guides, we illustrate the process of building each system, harnessing the power of Pinecone to optimize search accuracy, facial recognition, and anomaly detection in various domains.
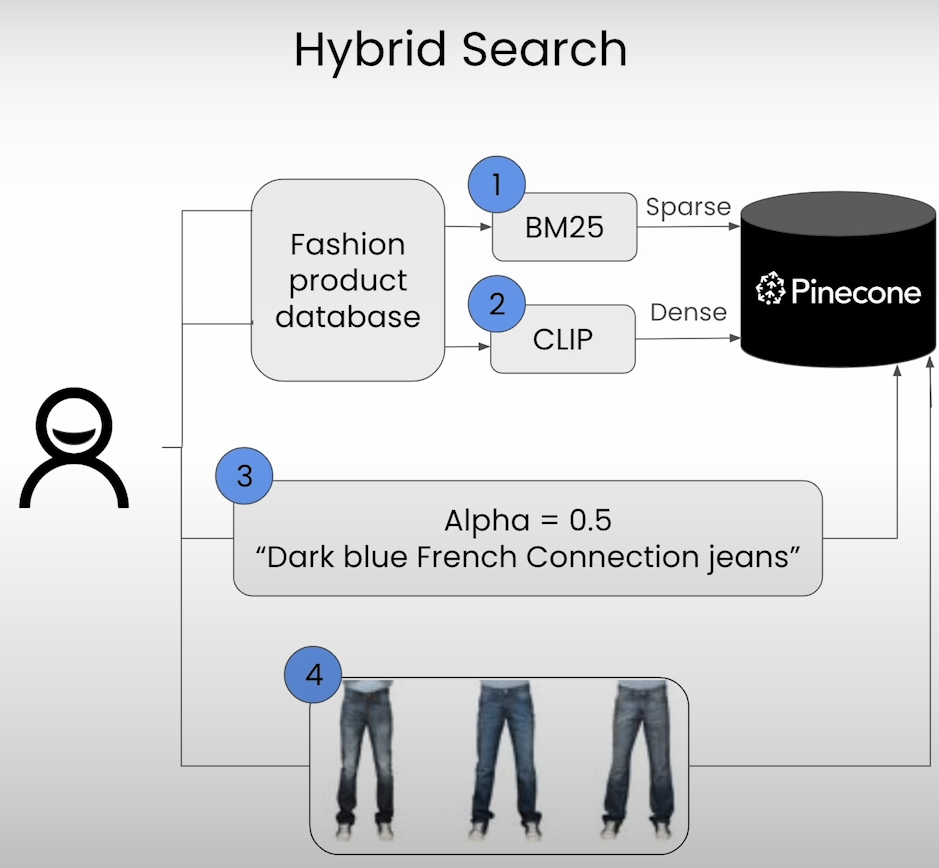
Hybrid Search with Pinecone Vector Database:
Hybrid Search combines semantic and traditional keyword-based search methodologies, offering enhanced search capabilities. With Pinecone, building a hybrid search engine becomes straightforward:
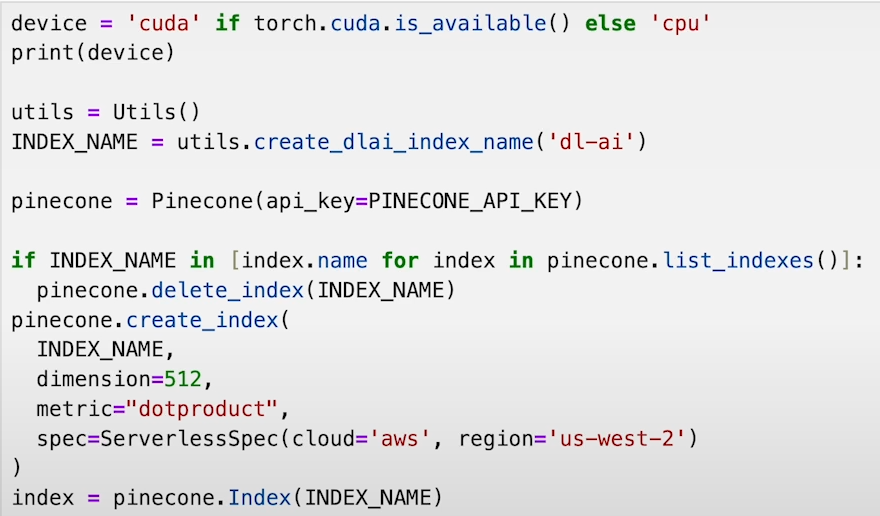
a) Establish a connection to Pinecone and create an index.
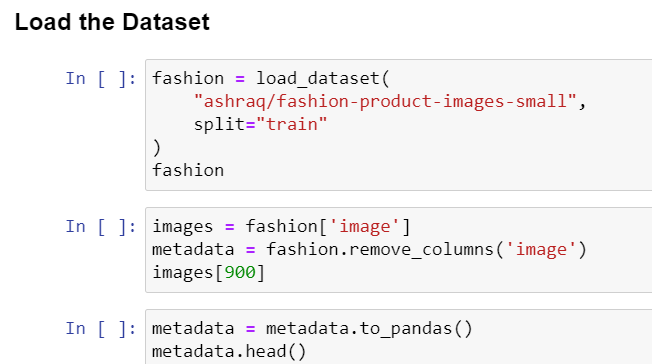
b) Collect and prepare data for hybrid search.
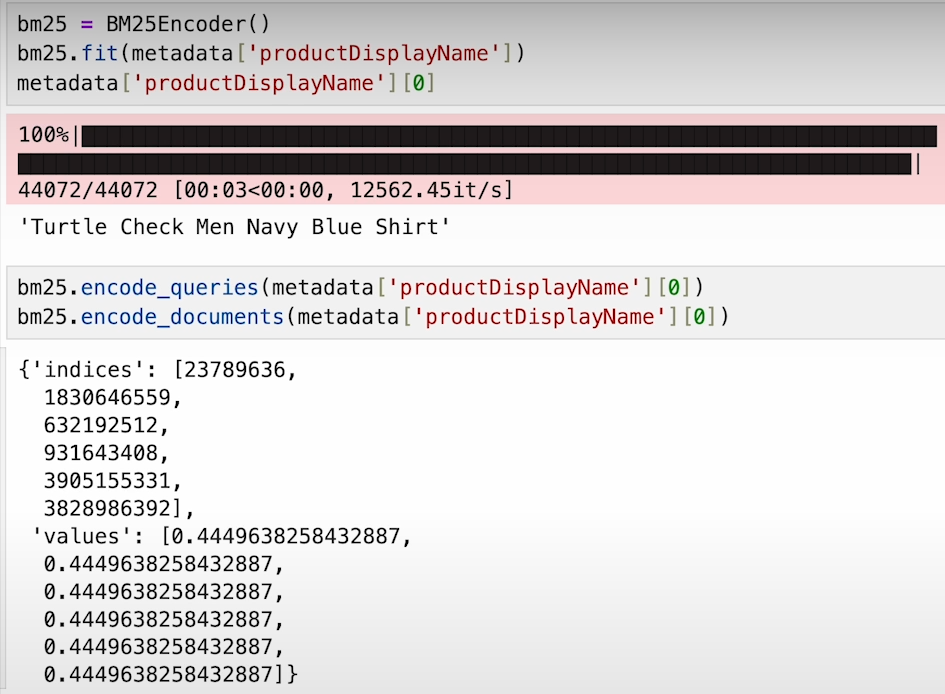
c) Instantiate sparse and dense encoders to convert data into numerical format.

d) Use encoders to create a dictionary of all data and insert it into Pinecone.
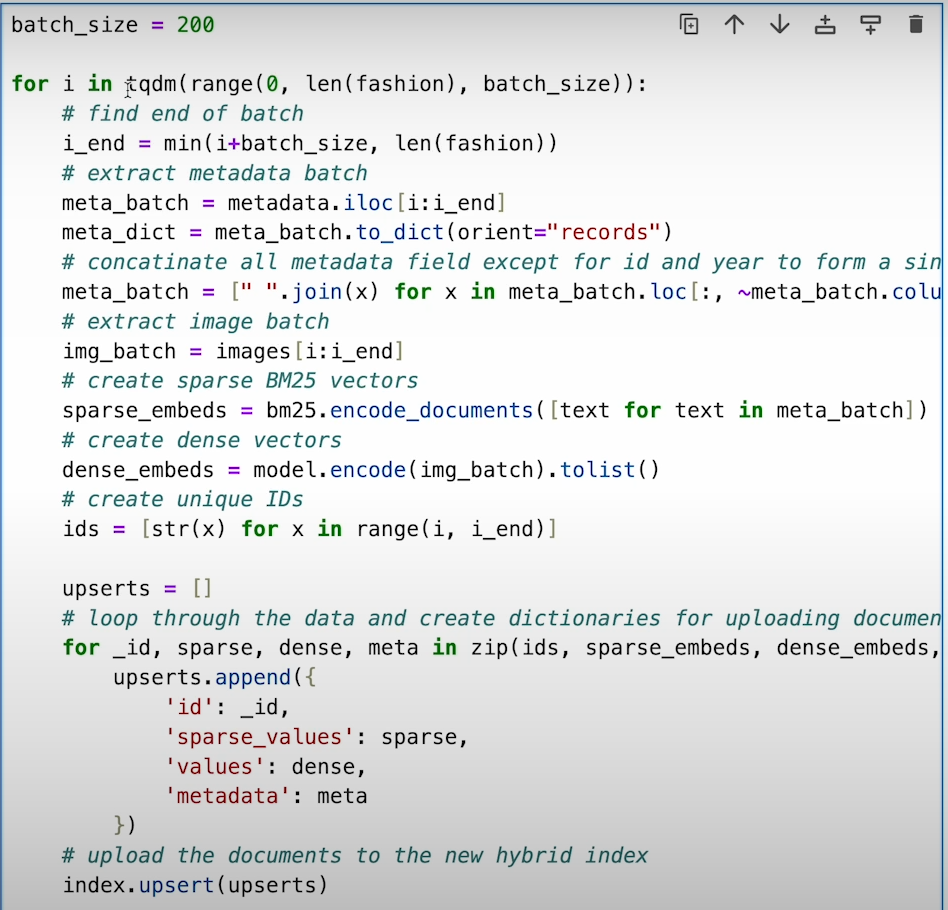
e) Now take the user query. Pass this query into sparse and dense encoder separately. Use this encoded data to extract search result from pinecone after defining no of same results we want from as the output.
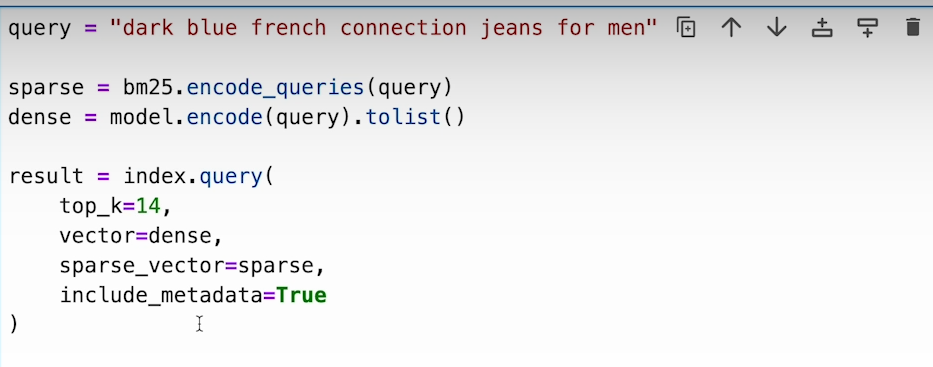
f) we can make use of alpha parameter to prioritize either dense or sparse vector for search engine. If alpha is closer to 0 then it means sparse vector search is given more importance. If the alpha is closer to 1 then it means dense vector search is given more importance.


Facial Similarity Search using Pinecone:
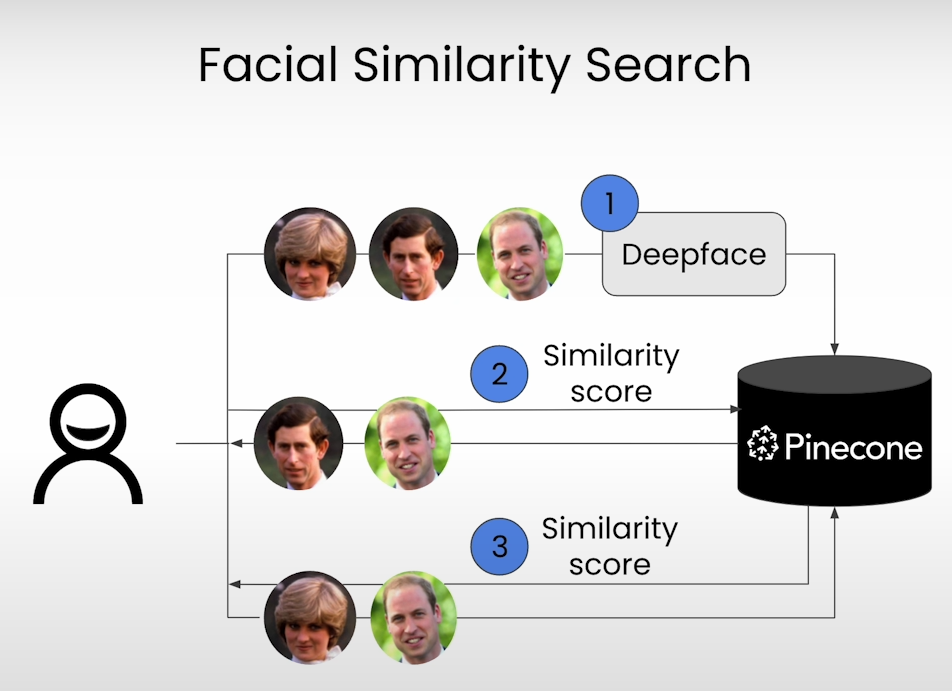
Facial similarity search enables the identification of human faces in images or videos, facilitating tasks such as facial recognition and image retrieval. Pinecone simplifies the creation of facial similarity search systems:
a) Prepare the dataset and set up Pinecone.
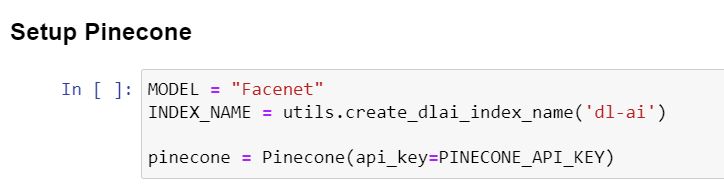
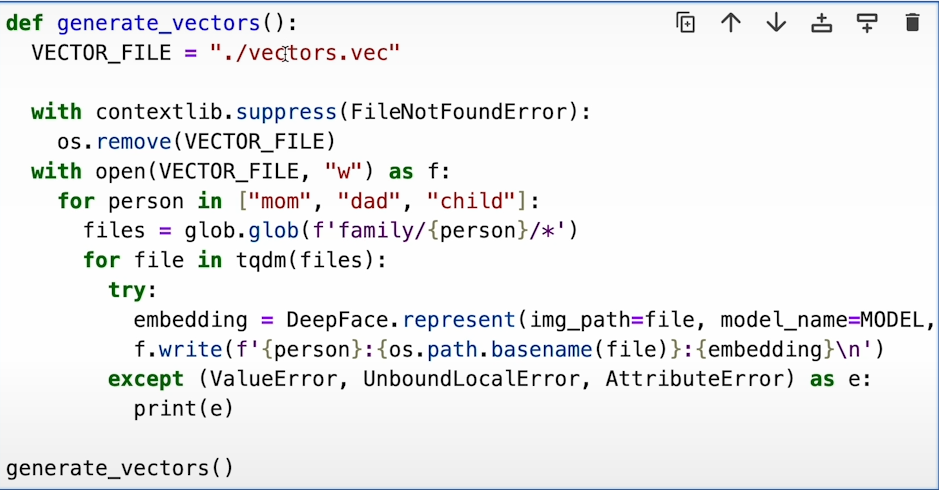
b) Create a helper function to generate embeddings for images and store them.
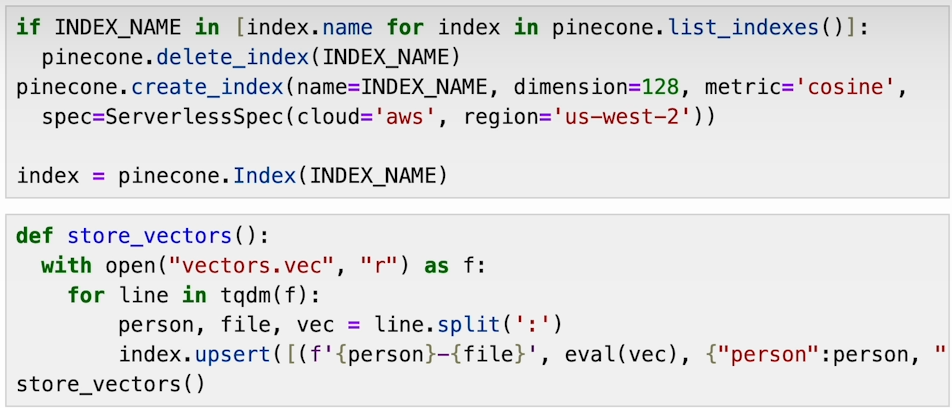
c) Populate Pinecone index with saved embeddings, ensuring data is organized effectively.
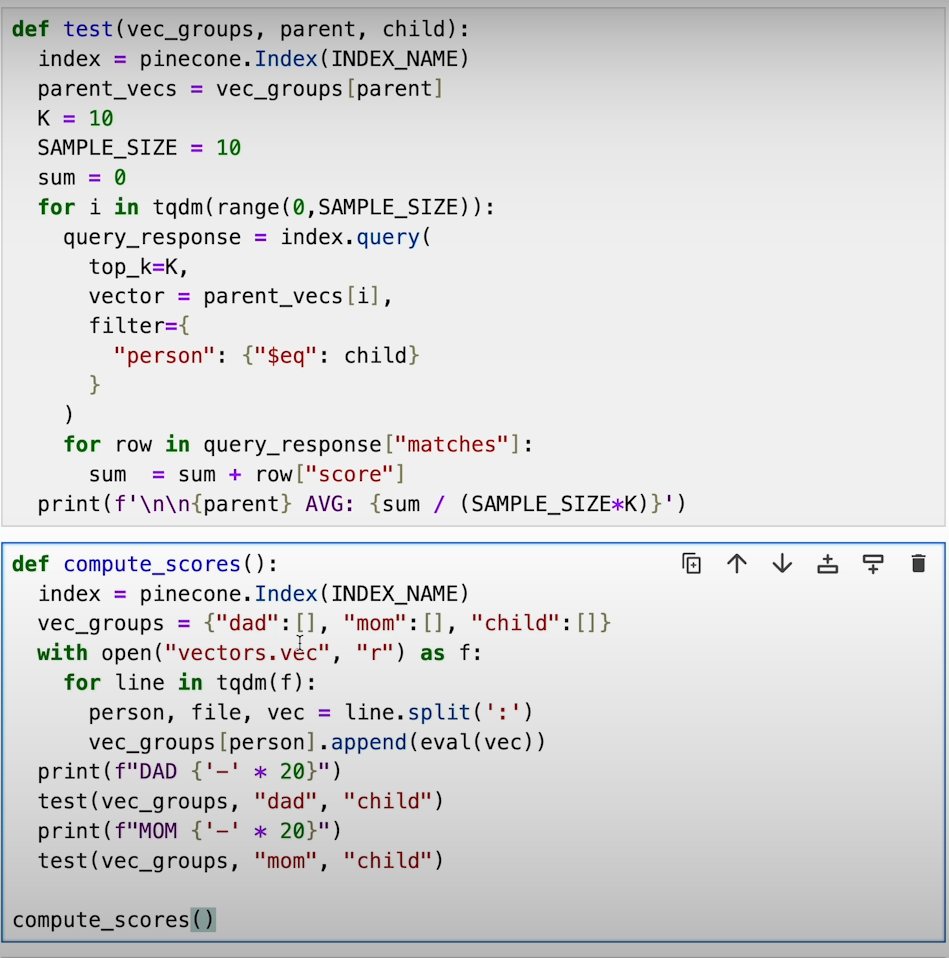
d) Develop a function to compare user images with existing categories and retrieve similar images from Pinecone.
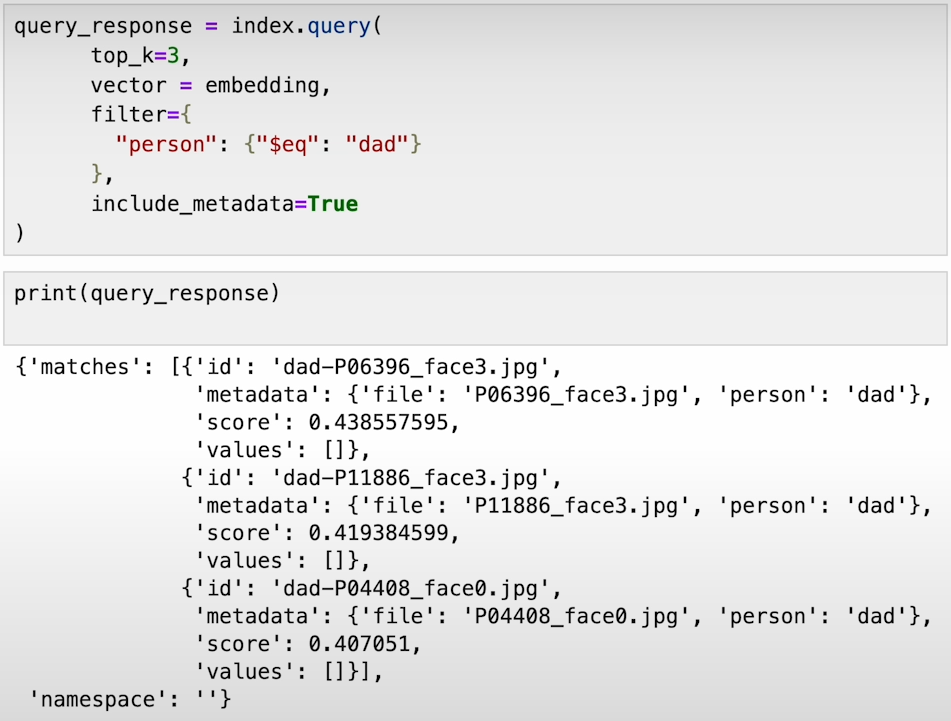
Anomaly Detection powered by Pinecone Vector Database:
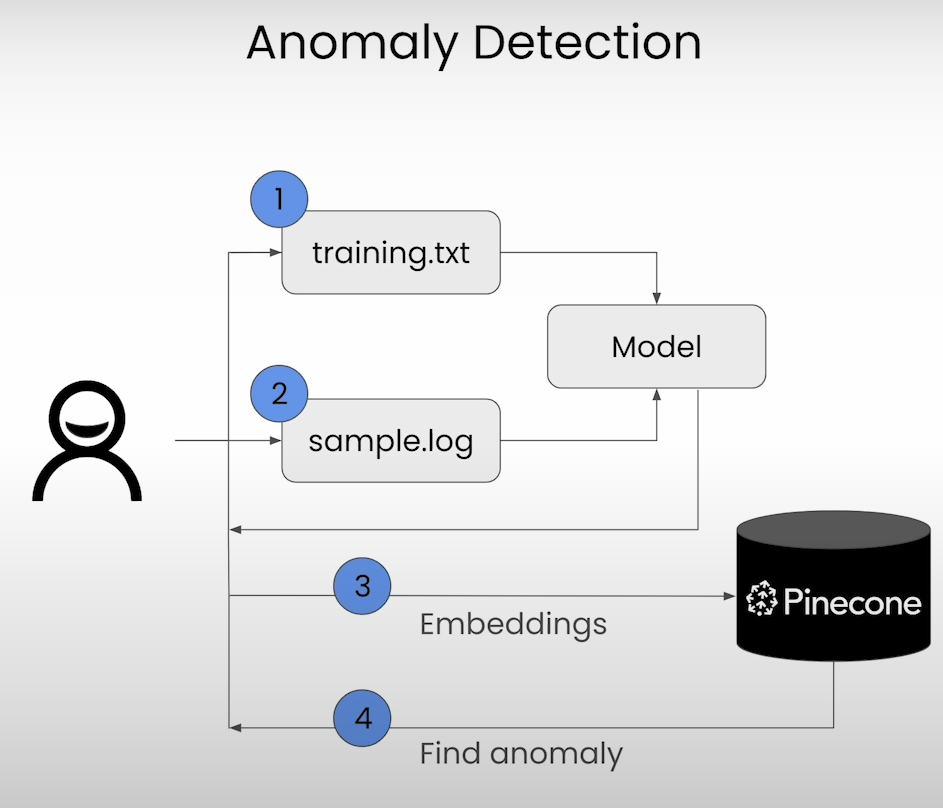
Anomaly detection systems identify unusual patterns or outliers in data, enabling proactive risk management and anomaly prevention. Pinecone streamlines the creation of anomaly detection systems:
a) Establish a connection to Pinecone and create an index.
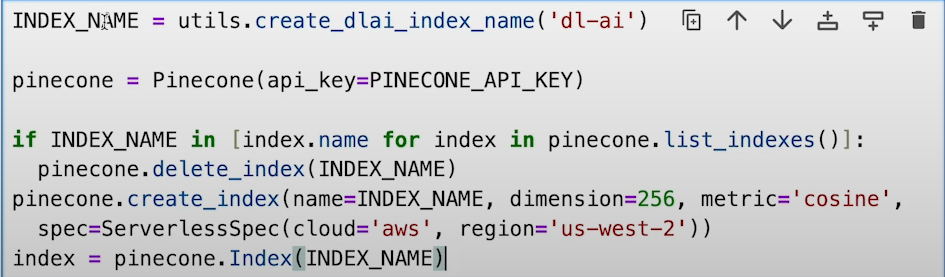
b) Prepare the dataset and initialize sentence transformer.
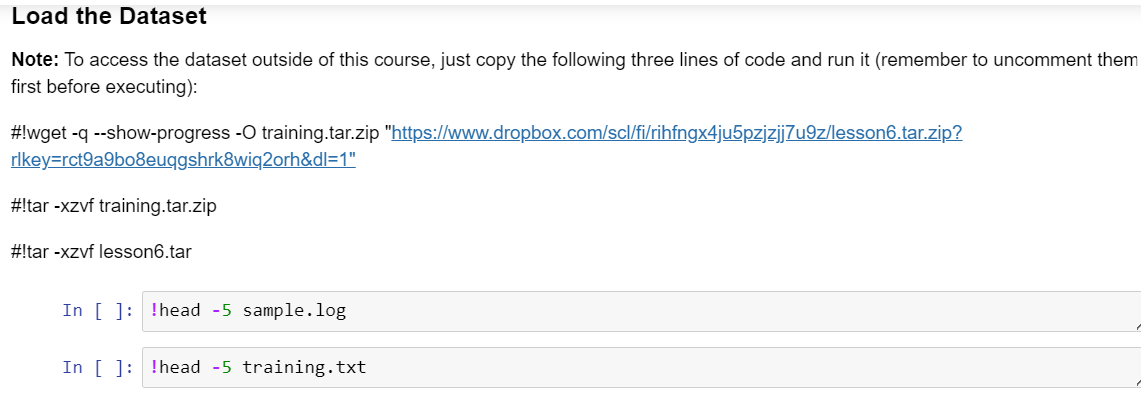
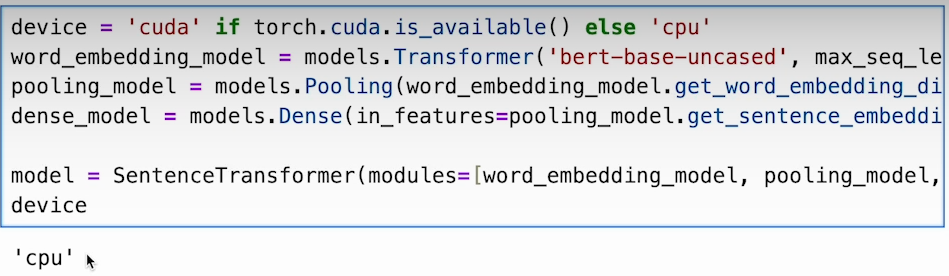
c) Train the model and vectorize the data for storage in Pinecone.
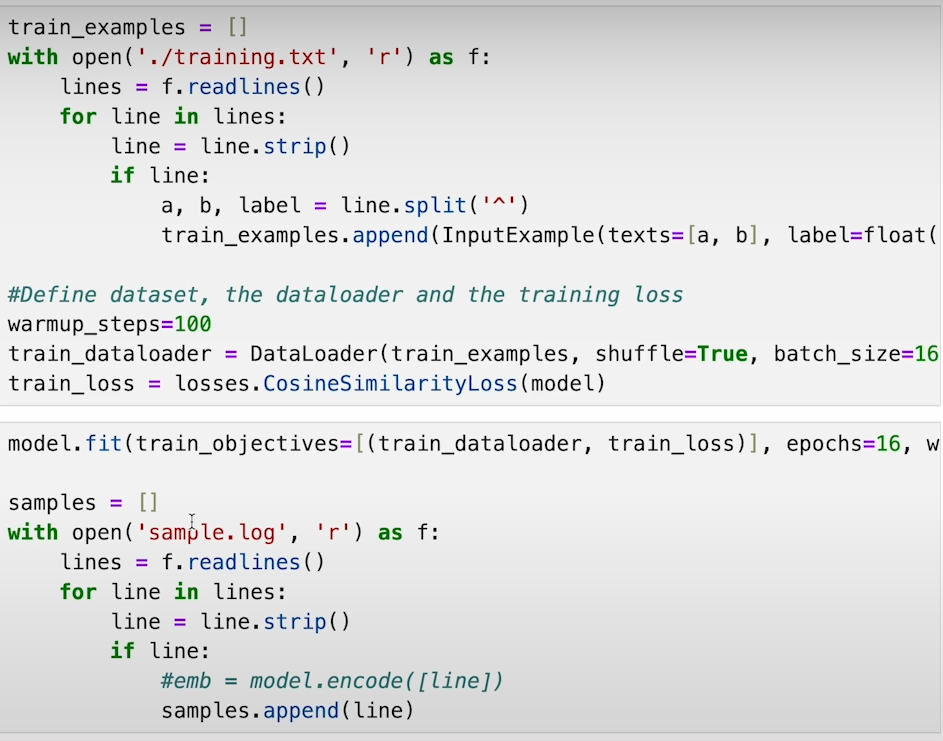
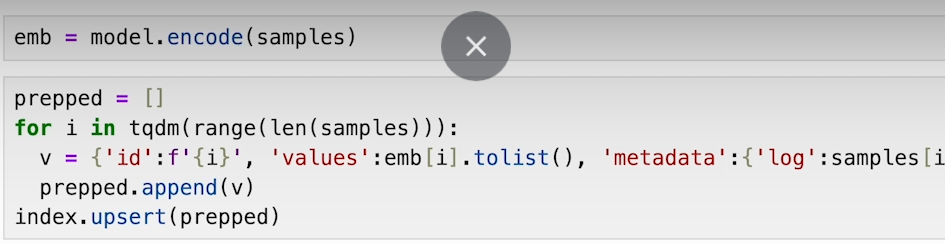
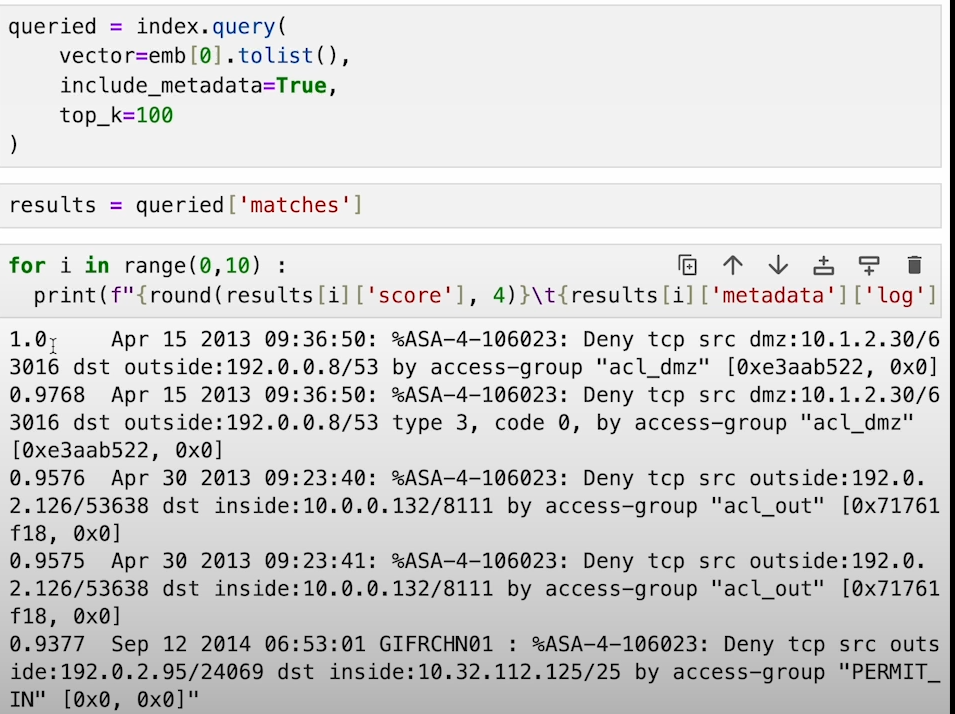
d) Utilize Pinecone to find similar results for user queries and identify anomalies based on similarity scores.
Summary:
Pinecone Vector Database empowers the development of advanced search, facial recognition, and anomaly detection systems, revolutionizing data analysis across various domains. By following the outlined steps, developers can leverage Pinecone's capabilities to build efficient and scalable solutions tailored to specific use cases. With Pinecone, the journey towards unlocking actionable insights and addressing complex challenges becomes streamlined and accessible, paving the way for innovation and advancement in data-driven applications.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com