Playwright Web Scraping 2024 - Tutorial
 Crawlbase
Crawlbase
This blog is originally posted to the crawlbase blog.
In this tutorial, our main focus will be on Playwright web scraping. So what is Playwright? It’s a handy framework created by Microsoft. It’s known for making web interactions more streamlined and works reliably with all the latest browsers like WebKit, Chromium, and Firefox. You can also run tests in headless or headed mode and emulate native mobile environments like Google Chrome for Android and Mobile Safari.
Playwright started its journey back in January 2020, and since then, it’s been growing steadily. By March 2024, it’s hitting about 4 million downloads every week. Big names like Adobe Spectrum and Visual Studio Code are already using it for their projects. This year Playwright is getting more popular than ever.
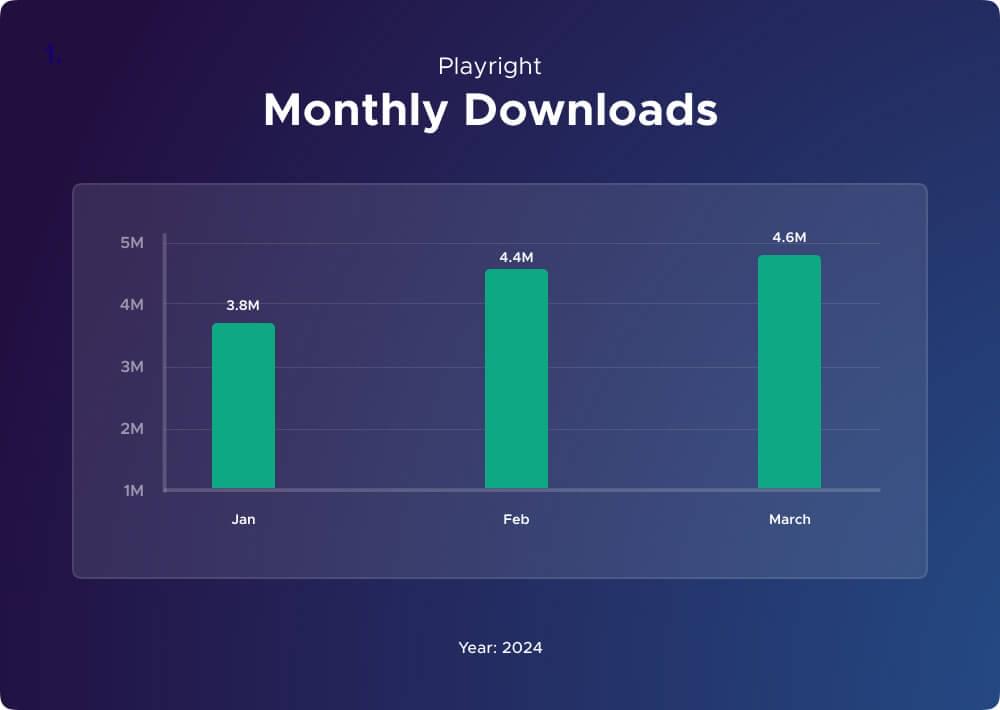
Throughout this tutorial, we’ll show you step by step tutorial on how to use Playwright for web scraping in Node.js. We’ll also showcase Crawlbase for a different approach to getting data from the web. Whether you’re a seasoned developer or new to web scraping, this tutorial promises to equip you with the necessary skills for success. Let’s begin.
Table of Contents
3. How to Web Scrape using Playwright
4. Scraping Original Price using Playwright
5. Scraping Discounted Price with Playwright
6. Scraping Product Thumbnail using Playwright
7. Scraping Product Ratings with Playwright
8. Scraping Product Reviews Count using Playwright
9. Scraping Product Reviews with Playwright
10. Code Compiling and Execution for Playwright Scraping
11. Scraper using Crawlbase Crawling API and Cheerio
13. Frequently Asked Questions
1. Blog Scope
Our goal for this tutorial is to crawl and scrape Backmarket.com, particularly this URL, and extract essential information such as the product’s title, original and discounted prices, thumbnail image URL, ratings, reviews count, and individual reviews.
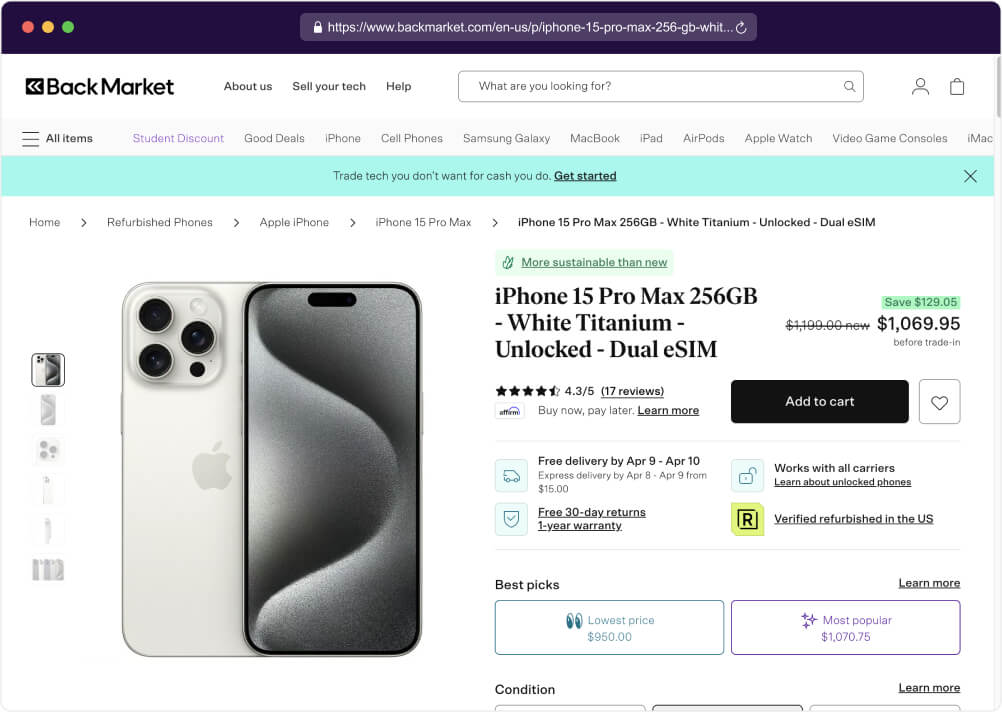
We will provide two different approaches for this tutorial:
Playwright Method: First, we will utilize the Playwright framework to extract relevant data from our target URL. We will provide step-by-step instructions, from setting up your coding environment for Playwright to parsing the HTML content of the page to printing the results in an easily digestible JSON format which can be used for further analysis.
Crawlbase Crawling API Method: Next, we will utilize the Crawling API from Crawlbase to crawl and scrape data from the same product page. We will make a GET request to the target URL to extract the HTML content without getting blocked then parse the content using Cheerio. The parsed content will be printed in a readable JSON format as well.
You’ll get a deeper understanding of different techniques for web scraping by exploring these approaches and understand how to adapt your scraping strategy based on the requirements of your project.
2. Prerequisites
Now that we’ve established our goals, we can start setting up our environment for coding. We need to make sure we have all the necessary foundations in place. Here’s what you’ll need to get started:
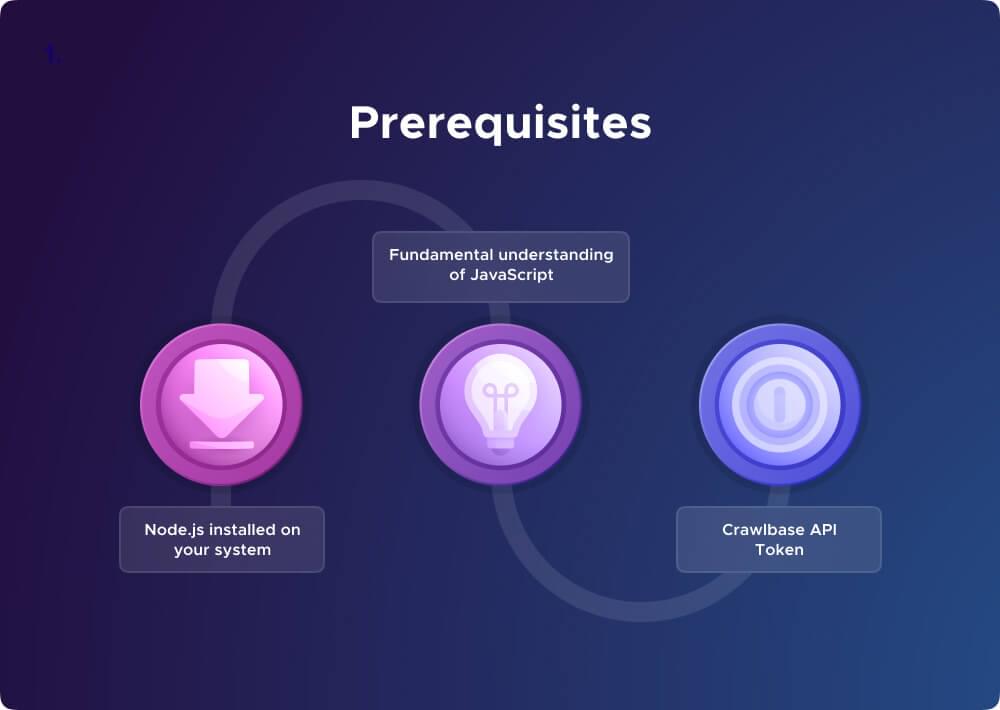
Node.js installed on your system: Node.js serves as a runtime environment, enabling the execution of JavaScript on your local machine. This is important for running the web scraping script we’re about to develop.
To install the environment, simply download Node.js from the official website: Node.js Official Website.
Fundamental understanding of JavaScript: Since we will be heavily utilizing JavaScript in our web scraping project, knowing the basics of the language is important. You should be familiar with concepts like variables, functions, loops, and basic DOM manipulation.
For those new to JavaScript, consider engaging in tutorials or documentation available on platforms like Mozilla Developer Network (MDN) or W3Schools.
Crawlbase API Token: In the second part of this tutorial, we’ll be utilizing the Crawlbase API for more efficient web scraping. The API token will serve as your key to authenticating requests and unlocking the full potential of the Crawling API. We’ll be using the Crawlbase JavaScript Token to mimic real browser requests.
To get your token, head over to the Crawlbase website, create an account, and access your API tokens from the account documentation section.
3. How to Web Scrape using Playwright
Once you have Node.js installed, open your command prompt (Windows) or terminal (macOS/Linux).
Create a directory to store your Playwright scraper code by running the following commands:
mkdir playwright-scraper |
Now install Playwright by using the command below:
npm install playwright |
Import library and create a function for scraping title:
Once you’ve installed the necessary packages, we can now begin coding. Start by importing the required modules like chromium from the Playwright library for automating the browser and fs for the file system operations. These are the key modules for performing web scraping and handling file operations within the Node.js environment.
For your convenience, you can copy and paste the code below into your index.js file
// Import required modules |
Scraping Process: The scrapeResults function is defined to scrape results from a provided web URL. Within this function:
It launches a new instance of the Chromium browser using
chromium.launch({ headless: false }), the browser should run in non-headless mode (visible UI).It creates a new browsing context and page using
browser.newContext()andcontext.newPage(), respectively. This prepares the environment for navigating to and interacting with web pages.It navigates to the provided web URL using
page.goto(webUrl). This instructs the browser to load the specified URL.It extracts the title of the product from the page using
page.$eval("h1", ...), which finds the first<h1>element on the page and retrieves its text content. The ?.textContent.trim() ensures that leading and trailing whitespace is removed from the extracted text.
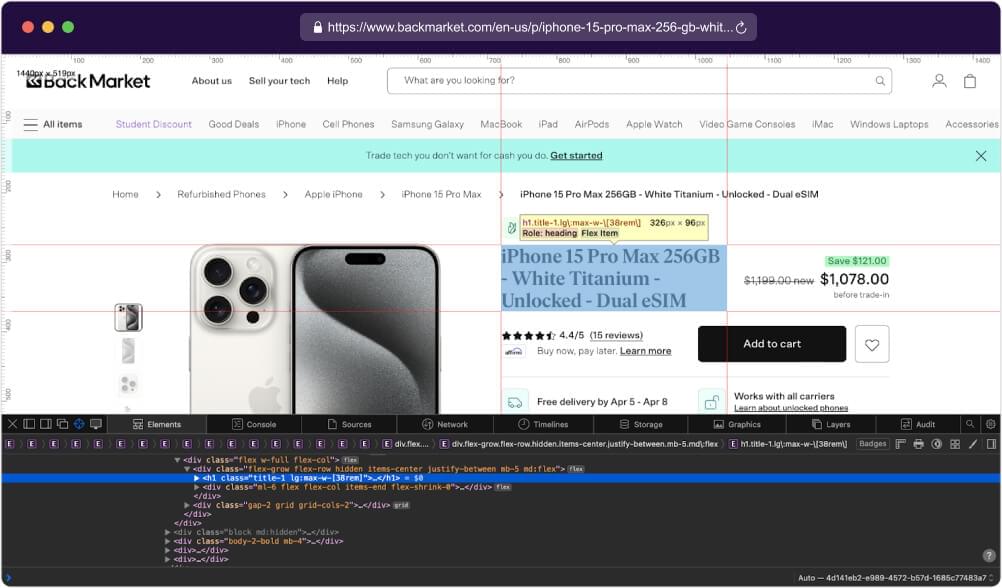
4. Scraping Original Price using Playwright
To extract the original price from the target webpage, first, visit the provided URL in your web browser. Next, right-click on the original price element and select “Inspect” to access the Developer Tools, which will highlight the corresponding HTML code.
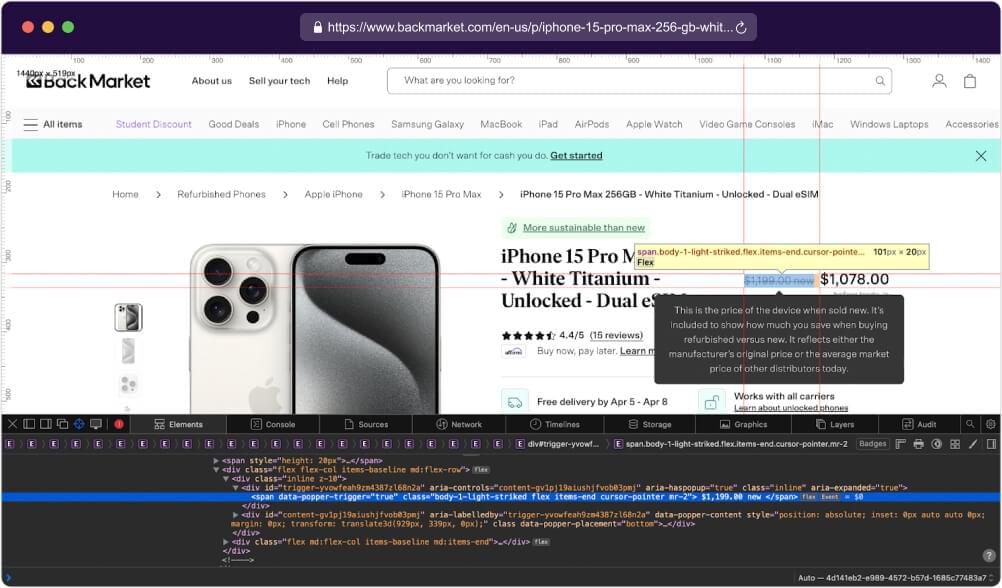
Identify the HTML element representing the original price, ensuring uniqueness by examining its attributes, classes, or IDs. Once identified, copy the CSS selector of the element and verify its accuracy in a text or code editor, making any necessary adjustments to accurately target the original price element.
// Function to get text content of an element by selector |
Function Definition (getValueBySelector):
This code defines an asynchronous function named getValueBySelector, which takes a CSS selector as its parameter.
Inside the function, it uses
page.evaluate()from Playwright to execute JavaScript code in the context of the current page.The JavaScript code inside
page.evaluate()selects an HTML element based on the provided CSS selector using document.querySelector(selector).It then accesses the textContent property of the selected element to retrieve its text content and applies the trim() method to remove any leading or trailing white spaces.
The function returns the trimmed text content of the selected element.
Extracting Original Price:
After defining the getValueBySelector function, it is invoked with a specific CSS selector
('[data-popper-trigger="true"].body-1-light-striked')to target a particular element on the page.The result, representing the original price of a product, is assigned to the variable
originalPrice.
5. Scraping Discounted Price with Playwright
Once again, right-click on the original price element and select “Inspect” to access the Developer Tools, which will highlight the associated HTML code.
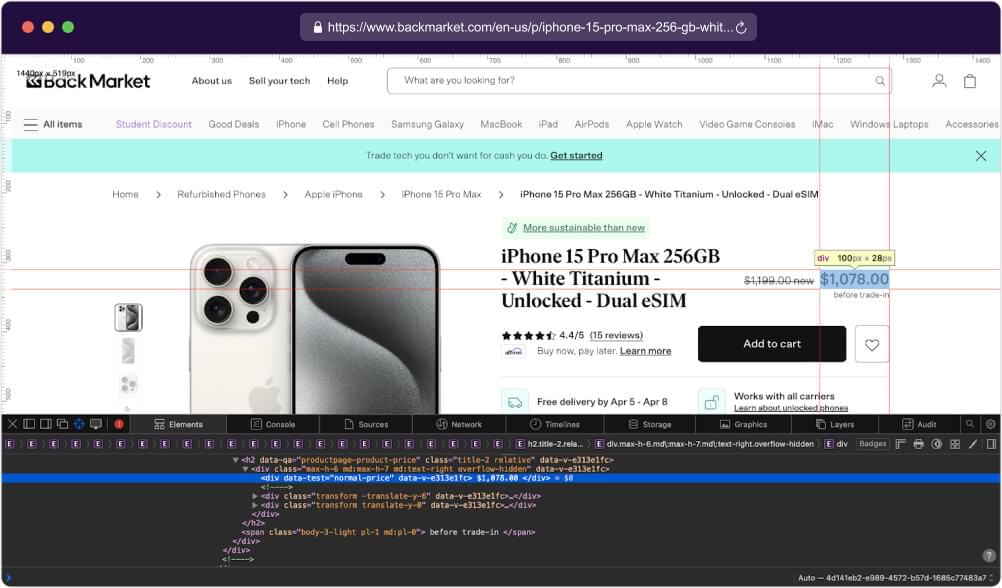
Once you have the correct CSS selector, you can write the code as shown below:
// Extract discounted price of the product |
This code extracts the discounted price of a product from our target web page. It likely utilizes getValueBySelector() to select the element displaying the discounted price based on its attribute. Once found, the discounted price value is stored in the variable discountedPrice for further processing.
6. Scraping Product Thumbnail using Playwright
Similar to the previous steps, right-click on the thumbnail image of the product and select “Inspect” to open the Developer Tools. This action will highlight the corresponding HTML code related to the thumbnail image.
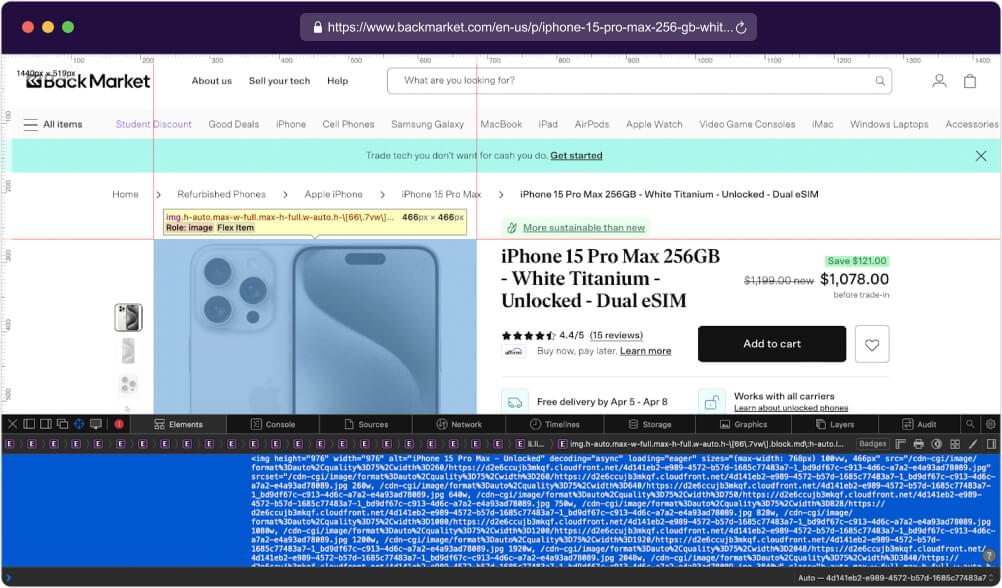
To write the code for extracting the thumbnail image URL using Playwright, you can use the following approach:
// Extract thumbnail image URL |
This code extracts the URL of a thumbnail image from a web page. We utilize page.evaluate() function to execute JavaScript code in the context of the web page. It selects the image element within a div with specific attributes and retrieves its src attribute, which holds the image URL. The extracted URL is then stored in the variable thumbnail for further use.
7. Scraping Product Ratings with Playwright
By now, you know the drill. Right-click on the product ratings and select “Inspect” to open the Developer Tools. This action will allow you to view the HTML code of the particular element we’ve selected.
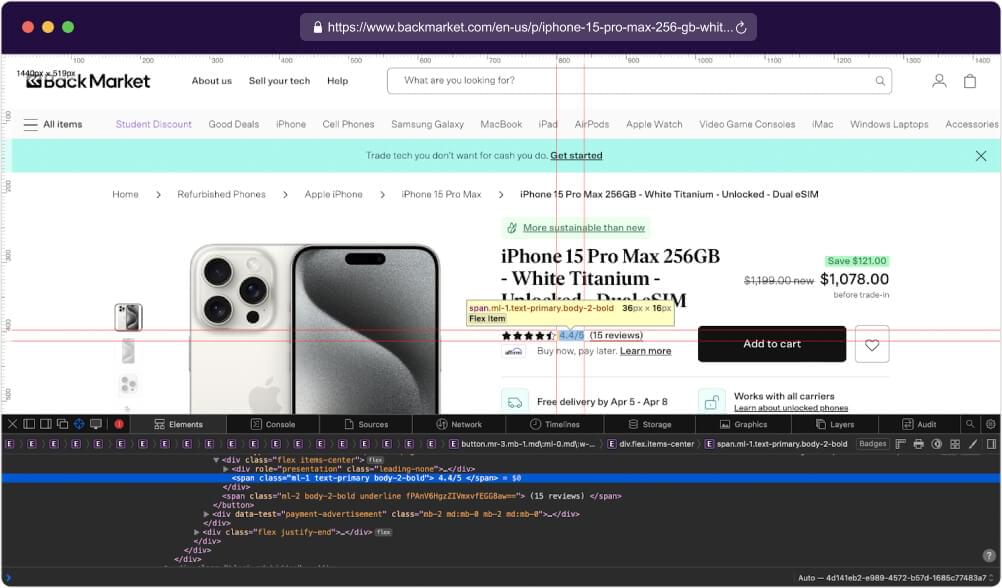
Here’s the code snippet for extracting the ratings of the product:
// Extract ratings of the product |
8. Scraping Product Reviews Count using Playwright
Once again, you’ll want to use the getValueBySelector to extract the count of reviews for the product. Pass in the CSS selector to select the element displaying the reviews count based on its attribute. Once found, store the count value in the variable reviewsCount for further use.
// Extract reviews count of the product |
9. Scraping Product Reviews with Playwright
Lastly, we will scrape the reviews of the product. Get the associated HTML code as shown below:
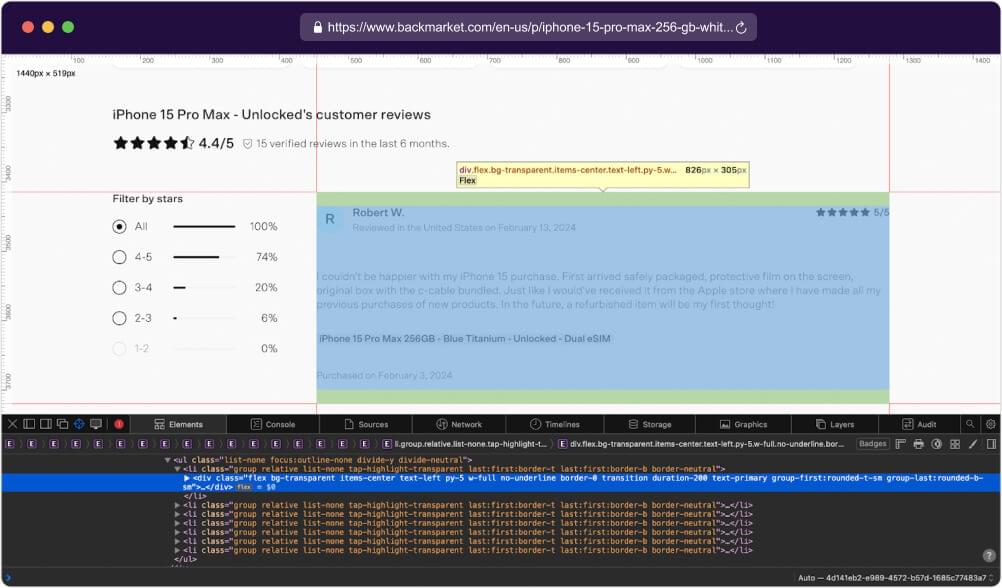
Select All Review Elements: Use document.querySelectorAll() to select all list items containing reviews. Store them in a variable named reviewElements.
Map Over Each Review Element: Use map() to iterate over each review element in reviewElements. Inside the map() function, extract relevant information such as author name, review URL, ratings, and review text.
Extract Author Name: Use querySelector() to find the element with the class .body-1-bold inside the current review element. Extract the text content and trim any leading or trailing spaces.
Extract Review URL: Use querySelector() to find the anchor (<a>) element with the attribute rel set to “noreferrer noopener”. Get the value of the href attribute and prepend it with the base URL https://www.backmarket.com/. This will give you the complete review URL.
Extract Ratings: Use querySelector() to find the element with the attribute data-qa set to “user-comment”. Extract the text content and trim any leading or trailing spaces.
Extract Review Text: Use querySelector() to find the element with the classes .body-1-light, .text-grey-500, and .whitespace-pre-line. Extract the text content and trim any leading or trailing spaces.
Return Extracted Information: Return an object containing the extracted information for each review element.
Filter Out Reviews: Use filter() to remove any reviews where either the author name or review text is missing.
Here’s how you can write the code:
const reviews = await page.evaluate(() => { |
10. Code Compiling and Execution for Playwright Scraping
Now that we have the code snippets for each element we want to scrape from backmarket.com, let’s compile them and save them as index.js.
// Import required modules |
Open your terminal or command prompt and navigate to the directory where index.js is saved. Execute the script by running the following command:
node index.js |
After running the script, check the output. If successful, you should see the extracted data printed to the console or saved to a file, depending on how you’ve implemented the code.
{ |
11. Scraper using Crawlbase Crawling API and Cheerio
Scraping using Crawlbase Crawling API and Cheerio is relevant to this tutorial as it offers an alternative approach to web scraping. This method stands out as one of the best alternatives because it utilizes the Crawlbase Crawling API, which can help prevent potential blocks and CAPTCHAs imposed by the target website.
Additionally, integrating the Crawlbase Crawling API with parsers like Cheerio provides a more stable solution for extracting data from web pages without encountering issues commonly faced in traditional scraping methods like getting blocked or being heavily rate limited. This method ensures that we can get the information we want from a website reliably and effectively.
To start, simply install the packages below:
mkdir scraper |
These commands will create a directory called scraper, create an index.js file, and install the Crawlbase and Cheerio libraries.
Now, we will apply a similar approach as we did with Playwright. However, this time, we’ll be utilizing an HTTP/HTTPs request to the Crawling API to obtain the HTML code of the page. We’ll then use Cheerio to extract the same sets of data from this HTML code.
// import Crawlbase Crawling API package |
After saving the code above, navigate to the directory where index.js is saved in your terminal or command prompt. Execute the script by running node index.js.
Check the output afterward. If successful, you’ll see the extracted data printed as shown below:
{ |
12. Conclusion
In conclusion, this tutorial has demonstrated two effective methods for scraping data from backmarket.com using Node.js. We explored the utilization of Playwright, showcasing how to extract specific information from a website. Also, we introduced an alternative approach using the Crawling API with Cheerio, offering a solution to bypass captchas and potential blocks while efficiently parsing HTML content.
Choosing between Playwright and the Crawling API with Cheerio will greatly depend on what you need for your project. Playwright provides a robust solution for dynamic web scraping and interaction with modern web applications, while the Crawling API with Cheerio offers a reliable method for accessing and parsing HTML content.
So, go ahead and choose what suits your project best. Don’t forget, the code we’ve shared here is all free for you to use. Feel free to apply it to scrape data from other websites too!
If you are interested on other scraping projects, we recommend checking the tutorials below:
How to Scrape Crunchbase Company Data
How to Scrape Websites with ChatGPT
13. Frequently Asked Questions
Q. Can Playwright be used for Scraping?
A. Yes. To scrape websites using Playwright, you can follow these general steps:
Step 1: Install Playwright: Begin by installing Playwright via npm using the command npm install playwright.
Step 2: Write Your Script: Create a JavaScript file (e.g., scrape.js) and write the code to automate your scraping tasks using Playwright. This may include navigating to the website, interacting with elements, and extracting data.
Step 3: Run Your Script: Execute your script by running node scrape.js in your terminal or command prompt.
Step 4: Check Output: After running the script, check the output to ensure that the desired data has been scraped successfully.
Step 5: Refine Your Script: Refine your script as needed to handle any edge cases or errors that may arise during the scraping process.
Q. Is Playwright easier than Selenium?
In terms of ease of use, Playwright is often considered to have a more user-friendly approach compared to Selenium. Playwright offers a simpler and more modern interface for automating browser interactions. It has features like automatic installation of browser drivers and built-in support for multiple programming languages.
On the other hand, Selenium has been around for longer and has a larger community and ecosystem. It’s widely used and has extensive documentation and resources available.
In short, the choice between Playwright and Selenium depends on factors such as the specific requirements of your project, team preferences, and existing infrastructure.
Q: Can you get blocked when you scrape a website using Playwright?
Yes, it’s possible to get blocked when scraping a website using Playwright. Websites may implement measures to detect and block automated scraping activities, such as detecting unusual traffic patterns or high-frequency requests from the same IP address.
To avoid blocks and CAPTCHAs, we recommend using Crawlbase. By integrating your code with Crawlbase API, you can benefit from its features, including the use of millions of rotating IPs and AI-based algorithm to mimic human interaction. This helps to mitigate the risk of detection and ensures smoother scraping operations.
Subscribe to my newsletter
Read articles from Crawlbase directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by