Python RAG with Complex PDFs
 Pablo Sanchidrian
Pablo Sanchidrian
INTRO
If you are here, it means you have the same problem I had. We can help each other.
I want to create a RAG capable of understanding complex PDFs. Dealing with complex documents is very hard. If your client does not want to change their documents, you have a big problem. The success of this project depends on how well we handle these documents. The better we handle them, the better the results.
MUST KNOW
This method depends on the LlamaIndex ecosystem.
Now, let's talk about the components we will use.
LLAMA PARSE
"LlamaParse is an API created by LlamaIndex to efficiently parse and represent files for efficient retrieval and context augmentation using LlamaIndex frameworks."
This tool will be key as will allow us to parse our PDF documents to Markdown.
OLLAMA
Well, when building a RAG you will need to use LLMs, with this platform you can run many LLMs without needing to handle a complex installation, it is just like docker, but instead of pulling an image, you will be pulling an LLM.
Here are some LLMs available with Ollama:
Mistral (We will be using this one)
Llama2
Llava
Falcon
And more...
Chroma DB
A vector database manages and organizes vector embeddings to facilitate quick retrieval and similarity searches. It supports essential functionalities such as Create, Read, Update, and Delete (CRUD) operations, filters based on metadata, scales horizontally and can operate in a serverless architecture. We are going to use ChromaBD
REDIS
We will store our index here. But what exactly is an index? The explanation from LlamaIndex is quite clear, so let me share it:
An index is a tool that quickly locates the necessary information when someone asks a question. It is crucial for developing intelligent systems that can effectively search and utilize information.
In other words, an index consists of numerous pieces of information known as documents. These documents are used to build systems capable of answering questions and interacting with users regarding the data.
While LlamaIndex lets you store this data on your computer if you prefer not to have additional files and are inclined towards using the cloud, keeping data on a local disk may not be the most suitable option.
LET'S CODE
Let's divide this into three sections "setup", "Ingest" and "Chat"
Setup
In this section, we are going create all needed instances that we will need to use to make this RAG, this includes setting up the connections to ChromaDB and Redis among others.
from llama_parse import LlamaParse
parser = LlamaParse(
api_key=settings.llama_cloud.api_key,
result_type="markdown",
num_workers=4,
verbose=True,
language="en"
)
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
from src.env import settings
class LlamaIndexConfig:
"""Initializes the Llama Index llm and embedding configuration."""
@classmethod
def init(cls):
llm = Ollama(model=settings.llama_cloud.llm_model, request_timeout=settings.llama_cloud.timeout)
embedding_model = HuggingFaceEmbedding(model_name=settings.chroma.embedding_model)
Settings.llm = llm
Settings.embed_model = embedding_model
This class will instantiate the LLM and the Embedding model that the LLamaIndex tools and methods will use. from llama_index.core import Settings This settings object is a global variable, so there will be only one instance of it during the execution of the backend.
Now it is the turn of the ChromaDB handler (Llama Index provides this handler so we will not have to take all the datastore management).
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core.vector_stores.types import BasePydanticVectorStore
chroma_store: BasePydanticVectorStore = ChromaVectorStore(
host=settings.chroma.host,
port=settings.chroma.port,
collection_name=settings.chroma.collection_name
)
The same happens with our index store, and as I mentioned we will be using Redis.
from llama_index.storage.index_store.redis import RedisIndexStore
from llama_index.core.storage.index_store.keyval_index_store import KVIndexStore
index_store: KVIndexStore = RedisIndexStore.from_host_and_port(
host=settings.redis.host,
port=settings.redis.port,
namespace=settings.redis.namespace
)
StorageContext: LlamaIndex provides essential frameworks for storing nodes, indices, and vectors. We won't add any nodes yet because we are only setting up the instance. We will include nodes later during the ingestion process.
from llama_index.core import StorageContext
storage_context: StorageContext = StorageContext.from_defaults(
vector_store=chroma_store,
index_store=index_store
)
If we already created a vector store index, we don't need to do so again; instead, we just load it. We should create a configuration class designed to load the index. If loading fails because the index doesn't exist, then we will create a new one.
# load the vector store index from the storage if it exists
load_index_from_storage(storage_context)
# create the index from the storage
index = VectorStoreIndex.from_vector_store(storage_context=storage_context)
index.storage_context.persist()
The following snippet will create a query engine from the index. but this query engine will incorporate a reranker; This will help us to improve the results, but the retrieval phase, where we look for the relevant documents to the given user query will take more time thus, making the chatting process slower.
from llama_index.core.base.base_query_engine import BaseQueryEngine
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
reranker: FlagEmbeddingReranker = settings.llama_cloud.get_reranker()
streaming_query_engine: BaseQueryEngine = index.as_query_engine(
streaming=True,
similarity_top_k=10,
node_postprocessors=[reranker]
)
# or just a normal query engine without streaming
query_engine: BaseQueryEngine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[reranker]
)
Let me demonstrate how to integrate all of these components.
import nest_asyncio
import uvicorn
from fastapi import FastAPI
from llama_index.core import StorageContext
from llama_index.core.base.base_query_engine import BaseQueryEngine
from llama_index.core.indices.base import BaseIndex
from llama_index.core.storage.index_store.keyval_index_store import KVIndexStore
from llama_index.core.vector_stores.types import BasePydanticVectorStore
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.storage.index_store.redis import RedisIndexStore
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_parse import LlamaParse
from starlette.middleware.cors import CORSMiddleware
from src.config.llama_index_config import LlamaIndexConfig
from src.config.vector_store_index_config import VectorStoreIndexConfig
from src.env import settings
from src.routers.chat_router import ChatRouter
from src.routers.ingest_router import IngestRouter
from src.services.document_service import DocumentService
class Main:
@classmethod
def bootstrap(cls) -> None:
nest_asyncio.apply()
uvicorn.run(
cls._generate_app(),
host="0.0.0.0",
port=settings.port,
loop="asyncio"
)
@classmethod
def _generate_app(cls) -> FastAPI:
app: FastAPI = FastAPI(title="Retrieval-Augmented Generation With Complex Documents", version="0.0.1")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
LlamaIndexConfig.init()
chroma_store: BasePydanticVectorStore = ChromaVectorStore(
host=settings.chroma.host,
port=settings.chroma.port,
collection_name=settings.chroma.collection_name
)
index_store: KVIndexStore = RedisIndexStore.from_host_and_port(
host=settings.redis.host,
port=settings.redis.port,
namespace=settings.redis.namespace
)
storage_context: StorageContext = StorageContext.from_defaults(
vector_store=chroma_store,
index_store=index_store
)
index: BaseIndex = VectorStoreIndexConfig.init(storage_context)
reranker: FlagEmbeddingReranker = settings.llama_cloud.get_reranker()
streaming_query_engine: BaseQueryEngine = index.as_query_engine(
streaming=True,
similarity_top_k=10,
node_postprocessors=[reranker]
)
parser = LlamaParse(
api_key=settings.llama_cloud.api_key,
result_type="markdown",
num_workers=4,
verbose=True,
language="en"
)
app.include_router(ChatRouter(streaming_query_engine).router)
app.include_router(IngestRouter(index, DocumentService(parser)).router)
return app
if __name__ == "__main__":
Main.bootstrap()
from src.env import setting that is the object that will initialize and store all the .env variables.
from pydantic import BaseModel
from pydantic_settings import BaseSettings, SettingsConfigDict
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
class Redis(BaseModel):
host: str
port: int
namespace: str
class Chroma(BaseModel):
protocol: str
host: str
port: int
collection_name: str
embedding_model: str
dim: int
class LlamaCloud(BaseModel):
api_key: str
llm_model: str
reranker: str
timeout: int
def get_reranker(self):
return FlagEmbeddingReranker(model=self.reranker, top_n=5)
class Settings(BaseSettings):
model_config = SettingsConfigDict(env_file='.env', env_nested_delimiter='__')
port: int
llama_cloud: LlamaCloud
chroma: Chroma
redis: Redis
settings = Settings()
Ingest
Let me show you the components we built to make this ingest process.
Document Service: This service will manage the ingest process, where we pass a document, get all the nodes (chunks) of it, and store them; Here is where the magic happens.
When we start DocumentService, we set it up with the tools it needs:
A
parserthat will parse a standard PDF structure to a Markdown structure.A
node_parserspecifically designed to understand and organize Markdown documents
When we want to add a document to our system, we follow these steps:
Read the Document: First, our
parserreads the document and parses it to a markdown format.Understand the Document: The
node_parsertake a list of documents, and chunk them into Node objects, such that each node is a specific chunk of the parent document.Store the Nodes: Finally, these nodes are added to our index.
Saving Changes: Once all the new information is added, we make sure to save everything.
from llama_index.core.indices.base import BaseIndex
from llama_index.core.node_parser import MarkdownElementNodeParser
from llama_parse import LlamaParse
class DocumentService:
"""Service class for loading data into an index."""
def __init__(self, parser: LlamaParse) -> None:
self.parser = parser
self.node_parser = MarkdownElementNodeParser(workers=8)
def load_data(self, document: str, index: BaseIndex) -> None:
"""Load data into the given index."""
documents = self.parser.load_data(document)
nodes = self.node_parser.get_nodes_from_documents(documents)
base_nodes, objects = self.node_parser.get_nodes_and_objects(nodes)
index.insert_nodes(base_nodes + objects)
index.storage_context.persist()
Ingest Router: Here we will expose the endpoint that the user is going to use to add new documents to the knowledge base.
import shutil
import tempfile
from fastapi import UploadFile
from fastapi.responses import JSONResponse
from llama_index.core.indices.base import BaseIndex
from ..services.document_service import DocumentService
from .base_router import BaseRouter
class IngestRouter(BaseRouter):
prefix: str = "/ingest"
def __init__(self, index: BaseIndex, document_service: DocumentService):
super().__init__()
self.index = index
self.document_service = document_service
self.router.add_api_route(
'/document',
self.add_document,
methods=['POST'],
description='Add a document to the index'
)
async def add_document(self, file: UploadFile) -> JSONResponse: # Annotated[bytes, File()]
"""Add a document to the index."""
temp = tempfile.NamedTemporaryFile(delete=True, suffix=".pdf")
shutil.copyfileobj(file.file, temp)
try:
self.document_service.load_data(temp.name, self.index)
except Exception as e:
return JSONResponse(status_code=400, content={'message': f'Error: {e}'})
finally:
temp.flush()
temp.close()
return JSONResponse(status_code=200, content={'message': 'Document added successfully'})
Chat
Finally, we expose the Chat Router, here is where we stream the LLM response to the user. We could return a String with all the text for simplicity, but I want to show you how easy is to enable streaming and how good it looks in the frontend, just to make it look like ChatGPT.
from llama_index.core.base.base_query_engine import BaseQueryEngine
from sse_starlette.sse import EventSourceResponse
from .base_router import BaseRouter
class ChatRouter(BaseRouter):
prefix: str = "/chat"
def __init__(self, query_engine: BaseQueryEngine):
super().__init__()
self.query_engine: BaseQueryEngine = query_engine
self.router.add_api_route(
'/ask',
self.chat,
methods=['GET'],
description="Ask a question and get a streamed response."
)
async def chat(self, query: str):
stream = self.query_engine.query(query).response_gen
return EventSourceResponse(stream)
Let's give it a look!!!
If you want to check out the code, click here, and feel free to make improvements. I intend to improve this backend alongside the open-source community and see what this project becomes.
To try it out we built a chatbot UI and uploaded two documents both of which have different structures but the content is related (CO2 and emissions):
Here are some results:
"Which EV model consumes less electricity EV1 EV2 or EV5 ??"
That is a question that can be answered using the first document
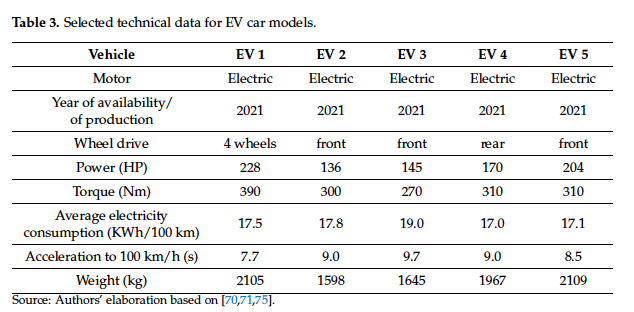
Here is the context needed to answer that question
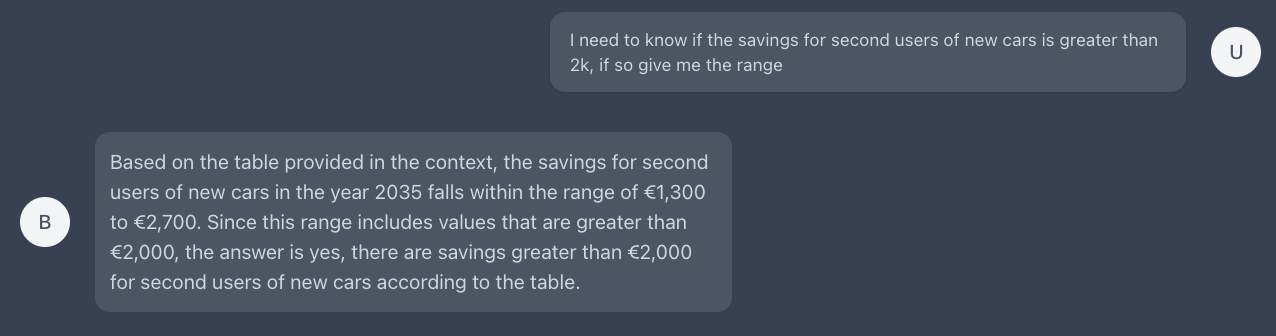
"Tell me about the savings in total cost of ownership for second users of new cars by 2035"
This question can be answered using the second document
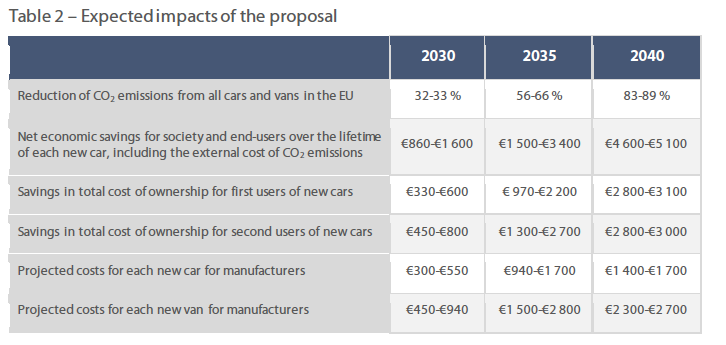
Here is the context needed to answer that question
We can even make trickier questions and still be able to give a correct answer
Conclusion
This AI framework seems okay, but it has some problems such as the time it takes to answer. I plan to show you how to create a RAG with complex documents, but this system should not completely depend on LlamaIndex if you want it to be scalable. Imagine if your system is fully connected with LlamaIndex and then you find a bug, or you need to change something that LlamaIndex can't handle. You will have a big problem because you'll need to change EVERYTHING. So, I advise making wrappers that let you switch the AI framework you are using so it is decoupled from the framework. Then, you only need to update the repositories, but the business logic (routers and services) stays the same.
If you enjoyed this reading, please consider reviewing my other posts.
Subscribe to my newsletter
Read articles from Pablo Sanchidrian directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pablo Sanchidrian
Pablo Sanchidrian
I'm a Software Engineer who loves diving into system design and the creative world of software development. My experience spans working with Java, and Typescript, and I get genuinely excited about contributing to open-source projects. I've also got experience with cloud platforms, always to make strong, efficient systems that can handle whatever is thrown at them. I'm just someone who loves making software that makes a difference, using my skills to solve problems