Linux x Docker : Exploring Essential Kernel Features for Containers
 Yogesh Kanwade
Yogesh Kanwade
Introduction
Containerization has revolutionized software development and deployment by enabling lightweight, portable, and scalable containerized applications. Behind the scenes, containerization tools like Docker use fundamental features of the Linux operating system to achieve process isolation, resource management, and filesystem abstraction. In this post, I want to cover the essential components of the Linux kernel that serve as the building blocks for container technology. Let's dive in!
Namespaces
Let's understand the concept of namespaces using a relatable analogy. Imagine our computer as a large building. In this building (our operating system), namespaces act like virtual rooms or partitions. Each room represents a different namespace, keeping certain things isolated and separate from each other, even though they're all part of the same building (our operating system). To put it simply, namespaces allow us to run processes or services in isolated 'rooms' within our computer, ensuring that they operate independently without causing conflicts to other parts of the system. A key objective of namespaces is to facilitate the implementation of containerization. By using namespaces, containerization platforms like Docker and Kubernetes can create lightweight, portable, and isolated environments for running applications.
Here’s a definition from man7.org:
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
Some commonly used namespaces in Linux
PID (Process ID) namespace
In Linux, each process is identified by a unique Process ID (PID). PID namespace gives each process its own unique PID. Processes in one room might have the same PID as processes in another room, but they're actually separate and cannot directly interact with processes in another namespace.
Network namespace
Network namespace is a way to isolate network resources so that different processes or containers can have their own independent network resources such as network devices, IP addresses, routing tables, firewall rules, etc. Each network namespace has its own network stack.
User namespace
User namespaces play a crucial role in computer systems by managing user-to-file ownership, which controls access to sensitive system files. This mechanism ensures that users sharing the same computer cannot access each other's files, enhancing security and privacy. Using user namespaces, we can map user IDs (UIDs) and group IDs (GIDs) within a container to different IDs on the host system. For instance, processes running as root with elevated privileges inside a container can be mapped to non-root users outside the container. This mapping is crucial from a security perspective, as it ensures that even if a user gains unauthorized access to the host system from within the container, they do not inherit root privileges, thus mitigating potential security risks.
Control groups (Cgroups)
Control groups (cgroups) are a kernel feature in Linux that provide a means to control and limit system resources (such as CPU, memory, disk I/O, and network bandwidth) among groups of processes. In container orchestration platforms like Docker and Kubernetes, cgroups are utilized extensively to provide the necessary resource isolation and management for running and scaling containers efficiently. When allocating a specific percentage of system resources to a cgroup (such as cgroup-1), the remaining resources are available to other cgroups and individual processes on the system. Take a look at the diagram below to better visualize this resource allocation process.
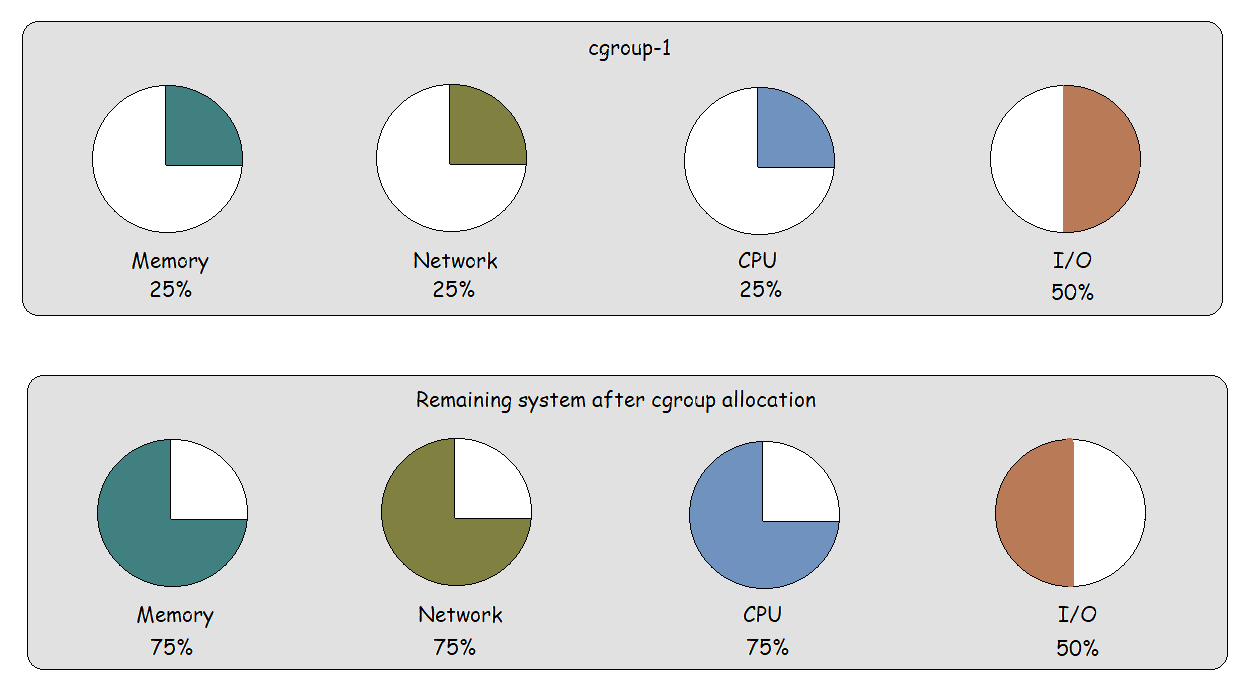
Key Features and Benefits of cgroups
Resource Limitation
Cgroups facilitate the setting of resource limits and constraints for processes within a group. Limits can be imposed on CPU usage, memory consumption, I/O bandwidth, and more, preventing individual processes or groups from monopolizing resources.
Dynamic Resource Adjustment
Cgroups support dynamic adjustments of resource allocations based on system demands. This flexibility ensures adaptive resource management to accommodate varying workloads and priorities.
Process Monitoring and Reporting
With cgroups, system administrators can monitor and report resource usage at both the group and individual process levels. This granular visibility allows for better resource optimization.
Controlling Processes
Cgroups empower system administrators to control the status (freeze, stop, restart) of all processes within a designated group using straightforward commands, providing efficiency in process management.
Union File System (UFS)
A union filesystem, also known as a union mount, is a type of filesystem that allows multiple directories or filesystems to be combined and presented as a single directory. This merging is done in such a way that the contents of the individual directories appear to coexist seamlessly within the unified view. The key idea behind a union filesystem is the concept of layers. Each layer represents a separate filesystem or directory. When files are accessed, the union filesystem presents a merged view of all layers, with files from higher layers (closer to the top of the stack) taking precedence over files in lower layers.
In containerization, tools like Docker use union filesystems to build container images efficiently. Imagine a container image as a stack of layers. Each layer in the stack represents a change or addition to the filesystem. Let's say you're building a web server container. You start with a base layer containing the operating system. Then, you add a layer for the web server software. Any configuration changes or updates become additional layers. Below, you'll find a visual representation of the concept of Union Filesystem (UFS) layering. This diagram aims to illustrate the layering structure discussed above.
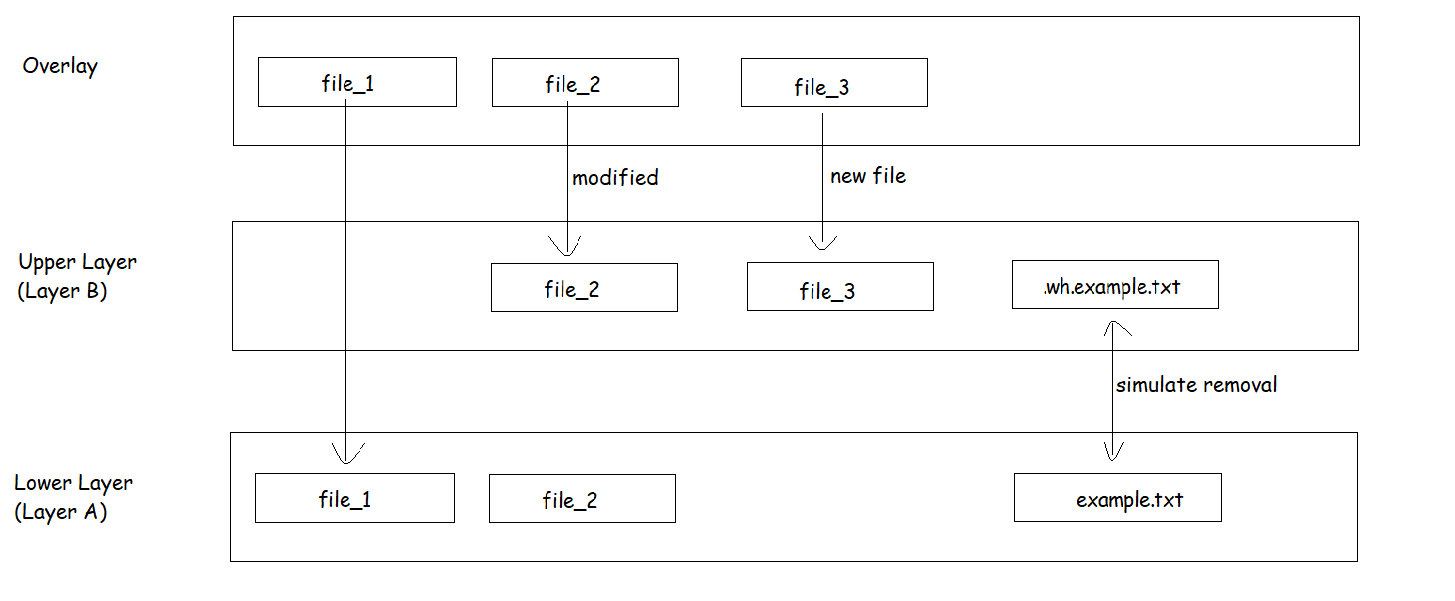
In the merged view (Overlay Layer):
'file_1' : accessed directly from Layer A, as it is unchanged in Layer B.
'file_2' : Users retrieve the modified version from Layer B, overlaying the original from Layer A.
'file_3' :Users access the newly added file exclusively from Layer B.
'example.txt' : This file is hidden or masked using whiteout file '.wh.example.txt' in upper layer (Layer B).
Key Features and Benefits of Union File System
Disk Space Optimization
Let's say you have 10 containers based on the same image. With a union file system like OverlayFS used by Docker, the common layers shared across these containers (such as the base operating system and application code) are stored only once on disk. This can significantly reduce the amount of disk space required compared to using traditional file systems like ext* or NFS.
Copy-on-Write (CoW)
Copy on Write is a technique that allows multiple processes or users to initially share the same data or resource (such as a file or memory block) without making physical copies of it. The system creates a new, separate copy of the data only when a modification (write operation) is attempted. The process that intends to modify the data is given a separate, writable copy of the resource. The original shared data remains unchanged and continues to be accessible by other processes. Copy on Write optimizes memory usage by deferring duplications until necessary. It avoids unnecessary copying of data upfront, saving time and resources.
Read-only Lower layers, Writable Upper layer
Building on the example from point 1, each container utilizes a combination of read-only lower layers (common to all containers) and a writable upper layer where changes specific to that container are stored. When a container needs to modify a file, the union file system employs copy-on-write, and stores it in the container's writable layer, ensuring isolation and preventing interference with other containers.
Whiteout Files
In a union filesystem, when we want to mask or hide a file or directory that exists in a lower layer, we can use a special type of file called a "whiteout" file. When a whiteout file is created in an upper layer and overlaid on top of an existing file or directory from a lower layer, the lower-layer file or directory becomes hidden or "removed" from the merged view. They allow for file deletions and modifications without directly altering the underlying read-only layers, preserving the integrity of the original filesystem snapshots. For example, to achieve the removal or masking of 'example.txt' from Layer A, we can create a whiteout file named '.wh.example.txt' in the upper layer (Layer B). Place this whiteout file in the same directory where 'example.txt' exists in Layer A. When the union filesystem combines Layer A and Layer B, we can achieve the simulated removal of 'example.txt' through the use of whiteout file.
Wrapping Up
It was exciting to learn about the underlying technologies that form the foundation of containerization. I plan to continue learning more about Docker and Linux and look forward to write more as I progress along this journey. Thank you!
Let's connect:
Subscribe to my newsletter
Read articles from Yogesh Kanwade directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yogesh Kanwade
Yogesh Kanwade
I'm Yogesh Kanwade, a final year Computer Engineering student with a deep passion for software development. I am a continuous learner, with hardworking and goal-driven mindset and strong leadership capabilities. I am actively exploring the vast possibilities of Web Development along with AWS and DevOps, fascinated by their impact on scalable and efficient web solutions.