Learning AWS Day by Day — Day 43 — Amazon Athena
 Saloni Singh
Saloni Singh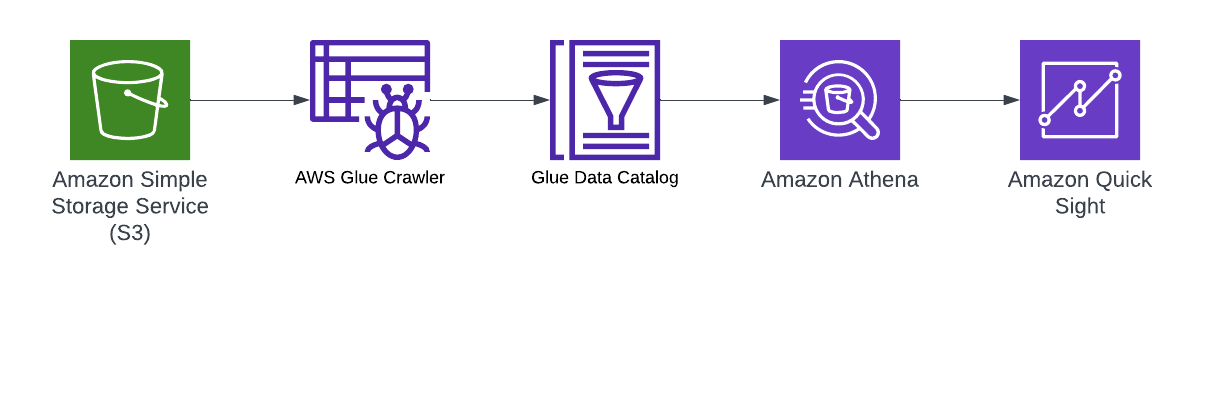
Exploring AWS !!
Day 43:
Amazon Athena
Serverless, Interactive query Platform, works on data stored in S3.
It uses standard SQL for querying data
It supports variety of formats: CSV, JSON, Avro, ORC (Columnar), Parquet (Columnar)
Only pay for querying the data
Quickly query unstructured, semi-structured and structured data.
Uses Presto (SQL query engine for Big Data)
Ways to access — AWS Console, Athena API, Athena CLI, JDBC connection
Integrates with AWS Glue Data Catalogue
Integrates with Quicksight for data visualization
Used to query large S3 database
No need to spin up servers or Hadoop Clusters.
-> Query editor, saved Queries, History, Data sources, Workgroup: primary
Use Case: Analyzing CloudTrail/CloudFront/VPC/ELBlogs
Integration through ODBC/JDBC with other visualization tool
Ad-hoc logs analysis
You need to setup a crawler to run periodically, scan your data and automatically populate the Glue Data Catalogue

Cost -> $5 per TB data scanned, no charges for DDL queries and failed queries, charges for cancelled queries
Save -> Columnar formats, using partitions, compression, number of files
Athena Queries:
Query results and metadata information is stored.
You specify output folder in S3 for storing output.
Stored Procedures are not supported.
Certain DDL operation are also not supported.
Athena Federated Query (preview feature).
Subscribe to my newsletter
Read articles from Saloni Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saloni Singh
Saloni Singh
• A Software Engineer with hands-on experience in AWS and Aws DevOps • Experience in CodePipeline using CodeCommit, CodeBuild and CodeDeploy • Experience with Terraform, Gitlab, Kubernetes, AWS DevOps, Helm charts, Golang, Python and NodeJS • Hands-on experience on AWS Migration projects including services - DMS, Glue, Aurora, Lambda, S3 • Possesses good knowledge on Bash Shell Scripting and Python Programming