Exploring Top Open Source Text-to-Video Models in Generative AI
 Spheron Network
Spheron Network
After introducing DALL-E, a text-to-image AI model, companies advanced to create text-to-video models. Over the course of two years, the technology has progressed from producing noisy outcomes to generating hyper-realistic results with text prompts. While the output may still not be perfect, several models today exhibit high controllability and the ability to create videos in various artistic styles.
Here are some of the latest text-to-video AI models you can try.
1. CogVideo

A team of researchers from the University of Tsinghua in Beijing has developed a large-scale pre-trained text-to-video generative model called CogVideo. They utilized a pre-trained text-to-image model called CogView2 to leverage the knowledge it had acquired from pre-training.
A computer artist, Glenn Marshall, tested the model and was initially impressed. He even suggested that directors might lose their jobs to it. The short film he created with CogVideo, titled "The Crow", was successful and even gained recognition at the BAFTA Awards.
2. Text2Video-Zero
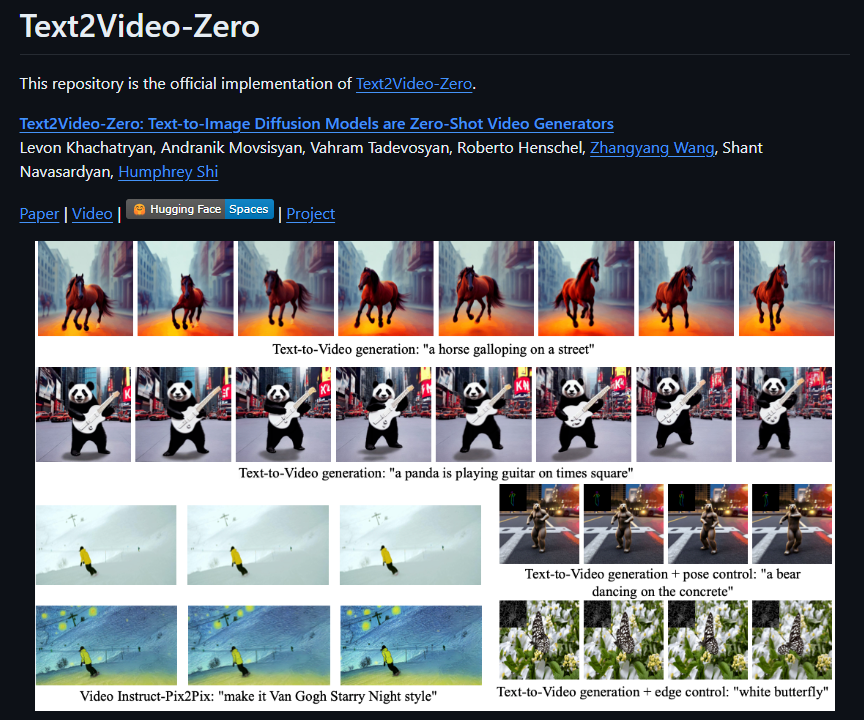
This is a description of a sophisticated AI system that can convert text into videos without the need for any training or optimization. The system uses existing text-to-image synthesis methods, like Stable Diffusion, but modifies them to create high-quality and consistent videos that match the text. Additionally, it can generate videos using text and image inputs, like poses or edges, and can even perform instruction-guided video editing.
3. NUWA

Microsoft Research has developed a series of advanced multimodal generative models that can create or manipulate images and videos. NUWA-Infinity has the ability to generate videos of any length, while NUWA-XL is trained on lengthy films and can create extremely long videos.
4. Open Sora

Open-Sora is an initiative dedicated to efficiently producing high-quality videos and making the model, tools, and content accessible to all. By embracing open-source principles, Open-Sora democratizes access to advanced video generation techniques and offers a streamlined and user-friendly platform that simplifies the complexities of video production. Open-Sora, its aim is to inspire innovation, creativity, and inclusivity in content creation.
Common features
AI models generate video content from textual input using powerful techniques, such as deep learning, recurrent neural networks, transformers, diffusion models, and GANs. These techniques enable the models to grasp the context and semantics of the textual input, creating highly realistic and coherent video frames.
Some of the common features of text-to-video AI models are:
It's possible to generate videos solely from text descriptions or a combination of text and image inputs.
With their advanced technology, they can produce videos in a plethora of artistic styles and moods, all while possessing the ability to understand 3D objects.
Videos of any length, be it a few seconds or several minutes, can be effortlessly generated.
These days, video editing has become a piece of cake. Instruction-guided video editing software can now perform tasks such as setting the background or focusing on a particular video subject with utmost precision.
Utilizing publicly available datasets or fine-tuning specific datasets are both viable options.
They can be accessed through various platforms, such as Hugging Face, RunwayML, NightCafe, and others.
The reason why does converting text into video content holds significance?
Text-to-video technology holds enormous potential across various fields:
Film and Animation: Animated features and short films creators can generate preliminary scenes or entire sequences from script excerpts, revolutionizing the animation industry.
Advertising and Marketing: Brands can use this technology to produce affordable, customized video content for marketing campaigns that target diverse audiences.
Gaming and Virtual Reality: Narrative construction in games and VR environments can potentially create real-time, story-specific scenes and backgrounds that are more dynamic.
Conclusion
The recent advancements in text-to-video conversion technology are a major breakthrough in AI-driven content creation. These technologies have the potential to offer a combination of efficiency, quality, and creativity, making it possible for users to bring their complex and imaginative ideas to life in video format. Open-source communities and commercial services are playing a significant role in the field by providing tailored tools and platforms for different applications and users.
As technology continues to advance, we can expect to see even more sophisticated and user-friendly solutions that will democratize video creation further, expanding its use in various fields. The future of Text-to-Video technology looks promising and is likely to revolutionize how video content is created and consumed.
Join Spheron's Private Testnet and Get Complimentary Credits for your Projects
As a developer, you now have the opportunity to build on Spheron's cutting-edge technology using free credits during our private testnet phase. This is your chance to experience the benefits of decentralized computing firsthand at no cost to you.
If you're an AI researcher, deep learning expert, machine learning professional, or large language model enthusiast, we want to hear from you! Participating in our private testnet will give you early access to Spheron's robust capabilities and receive complimentary credits to help bring your projects to life.
Don't miss out on this exciting opportunity to revolutionize how you develop and deploy applications. Sign up now by filling out this form: https://b4t4v7fj3cd.typeform.com/to/Jp58YQB2
Join us in pushing the boundaries of what's possible with decentralized computing. We look forward to working with you!
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute