How to Run Llama 3 - 8B and Llama 3 - 70B Locally
 Pradeep Vats
Pradeep VatsLlama 3 is the latest breakthrough in large language models. These models have garnered significant attention due to their impressive performance across various natural language processing tasks. If you're interested in harnessing their power locally, this guide will walk you through the process using the ollama tool.
Model developers Meta
Variations Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
Input Models input text only.
Output Models generate text and code only.
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
Model Release Date April 18, 2024.
Status This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
What is Llama 3?
Before diving into the technical details, let's briefly explore the key differences between the Llama 3 8B and 70B models.
https://huggingface.co/meta-llama
Llama 3 8B
The Llama 3 8B model strikes a balance between performance and resource requirements. With 8 billion parameters, it offers impressive language understanding and generation capabilities while remaining relatively lightweight, making it suitable for systems with modest hardware configurations.
Llama 3 70B
On the other hand, the Llama 3 70B model is a true behemoth, boasting an astounding 70 billion parameters. This increased complexity translates to enhanced performance across a wide range of NLP tasks, including code generation, creative writing, and even multimodal applications. However, it also demands significantly more computational resources, necessitating a robust hardware setup with ample memory and GPU power.
Performance Benchmarks of Llama 3
Llama-3-8B and Llama-70B Benchmarks
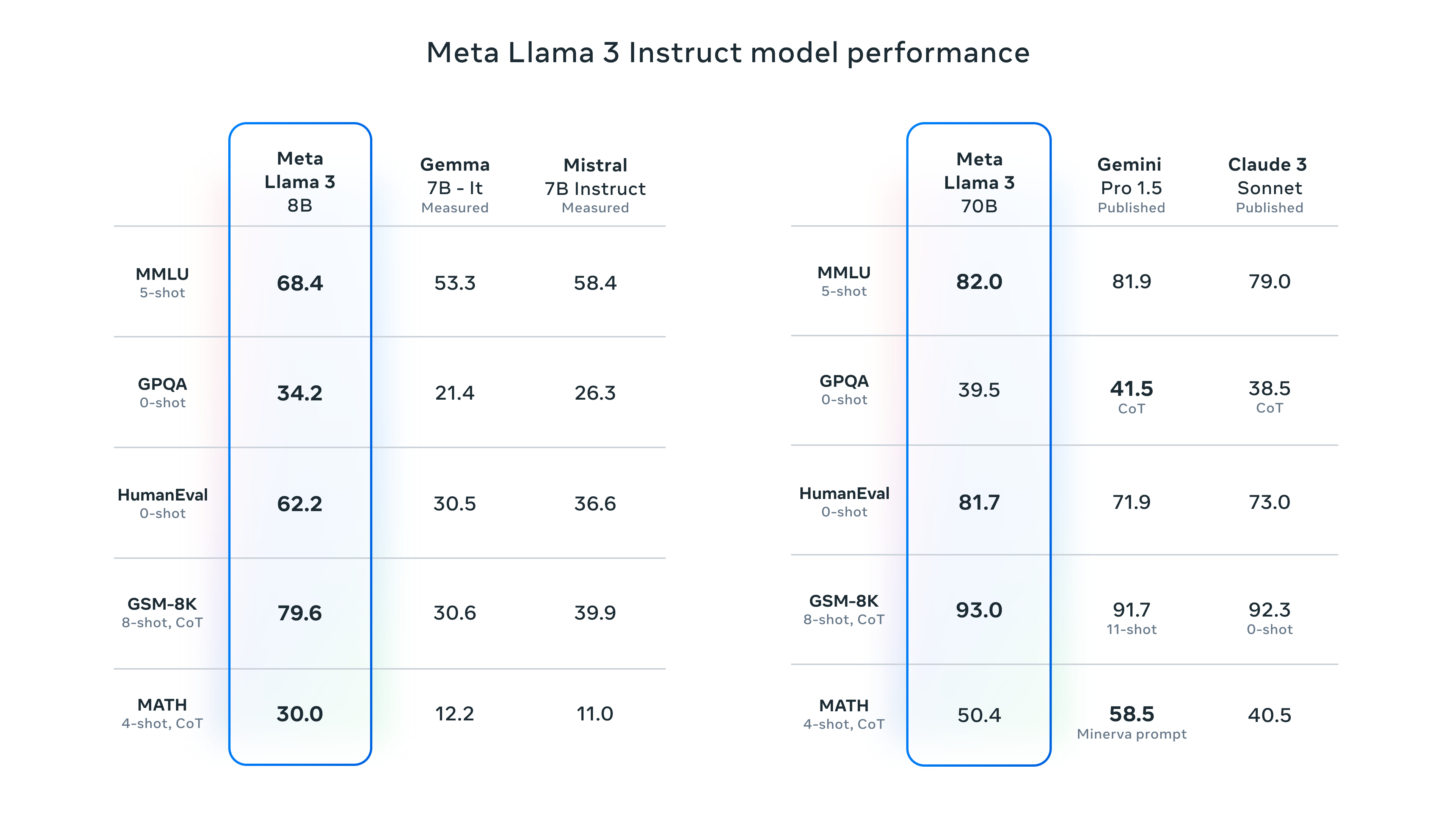
To help you make an informed decision, here are some performance benchmarks comparing the Llama 3 8B and 70B models across various NLP tasks:
| TASK | LLAMA 3 8B | LLAMA 3 70B |
| Text Generation | 4.5 | 4.9 |
| Question Answering | 4.2 | 4.8 |
| Code Completion | 4.1 | 4.7 |
| Language Translation | 4.4 | 4.9 |
| Summarization | 4.3 | 4.8 |
Note: Scores are based on a scale of 1 to 5, with 5 being the highest performance.
As you can see, the Llama 3 70B model consistently outperforms the 8B variant across all tasks, albeit with higher computational demands. However, the 8B model still delivers impressive results and may be a more practical choice for those with limited hardware resources.
Prerequisites to Run Llama 3 Locally
To run Llama 3 models locally, your system must meet the following prerequisites:
Hardware Requirements
RAM: Minimum 16GB for Llama 3 8B, 64GB or more for Llama 3 70B.
GPU: Powerful GPU with at least 8GB VRAM, preferably an NVIDIA GPU with CUDA support.
Disk Space: Llama 3 8B is around 4GB, while Llama 3 70B exceeds 20GB.
Software Requirements
Docker: ollama relies on Docker containers for deployment.
CUDA: If using an NVIDIA GPU, the appropriate CUDA version must be installed and configured.
How to Use Ollama to Run Lllama 3 Locally
ollama is a powerful tool that simplifies the process of running Llama models locally. Follow these steps to install it:
Open a terminal or command prompt.
Run the following command to download and execute the ollama installation script:
curl -fsSL https://ollama.com/install.sh | sh
This script will handle the installation process, including downloading dependencies and setting up the required environment.
Downloading Llama 3 Models
With ollama installed, you can download the Llama 3 models you wish to run locally. Use the following commands:
For Llama 3 8B:
ollama download llama3-8b
For Llama 3 70B:
ollama download llama3-70b
Note that downloading the 70B model can be time-consuming and resource-intensive due to its massive size.
Running Llama 3 Models
Once the model download is complete, you can start running the Llama 3 models locally using ollama.
For Llama 3 8B:
ollama run llama3-8b
For Llama 3 70B:
ollama run llama3-70b
This will launch the respective model within a Docker container, allowing you to interact with it through a command-line interface. You can then provide prompts or input text, and the model will generate responses accordingly.
Advanced Usage of Llama 3 Models
ollama offers a range of advanced options and configurations to enhance your experience, including:
Fine-tuning: Fine-tune the Llama models on your own data to customize their behavior and performance for specific tasks or domains.
Quantization: Reduce the memory footprint and improve inference speed by quantizing the models.
Multi-GPU Support: Leverage multiple GPUs to accelerate inference and fine-tuning processes.
Containerization: Export containerized versions of your fine-tuned or quantized models for easy sharing and deployment across different systems.
Fine-tuning Llama 3 Models
Fine-tuning is the process of adapting a pre-trained language model like Llama 3 to a specific task or domain by further training it on a relevant dataset. This can significantly improve the model's performance and accuracy for the target use case.
The Fine-tuning Process
Prepare Dataset: Gather a high-quality dataset relevant to your target task or domain. The dataset should be formatted correctly, typically as a collection of input-output pairs or prompts and expected responses.
Load Pre-trained Model: Load the pre-trained Llama 3 model (8B or 70B) that you want to fine-tune.
Set Hyperparameters: Determine the appropriate hyperparameters for the fine-tuning process, such as learning rate, batch size, and number of epochs.
Fine-tune: Run the fine-tuning process, which involves updating the model's parameters using your dataset and the specified hyperparameters.
Evaluate: Evaluate the fine-tuned model's performance on a held-out test set or relevant benchmarks.
Deploy: Deploy the fine-tuned model for your target application or use case.
Fine-tuning with ollama
ollama provides a convenient way to fine-tune Llama 3 models locally. Here's an example command:
ollama finetune llama3-8b --dataset /path/to/your/dataset --learning-rate 1e-5 --batch-size 8 --epochs 5
This command fine-tunes the Llama 3 8B model on the specified dataset, using a learning rate of 1e-5, a batch size of 8, and running for 5 epochs. You can adjust these hyperparameters based on your specific requirements.
Replace llama3-8b with llama3-70b to fine-tune the larger 70B model.
Using Llama 3 on Azure
While ollama allows you to run Llama 3 models locally, you can also leverage cloud resources like Microsoft Azure to access and fine-tune these models.
Azure OpenAI Service
Microsoft Azure offers the Azure OpenAI Service, which provides access to various language models, including Llama 3. This service allows you to integrate Llama 3 into your applications and leverage its capabilities without the need for local hardware resources.
To use Llama 3 on Azure, you'll need to:
Create an Azure Account: Sign up for a Microsoft Azure account if you don't have one already.
Subscribe to the Azure OpenAI Service: Navigate to the Azure OpenAI Service in the Azure portal and subscribe to the service.
Obtain API Keys: Generate API keys to authenticate and access the Llama 3 models through the Azure OpenAI Service.
Integrate with Your Application: Use the provided SDKs and APIs to integrate Llama 3 into your application, allowing you to leverage its natural language processing capabilities.
Azure Machine Learning
Alternatively, you can use Azure Machine Learning to fine-tune Llama 3 models on Azure's scalable compute resources. This approach allows you to leverage Azure's powerful infrastructure for training and fine-tuning large language models like Llama 3.
Set up an Azure Machine Learning Workspace: Create an Azure Machine Learning workspace in the Azure portal.
Upload Dataset: Upload your fine-tuning dataset to an Azure storage account or Azure Machine Learning datastore.
Create a Compute Cluster: Provision a compute cluster with the necessary GPU resources for fine-tuning Llama 3.
Fine-tune Llama 3: Use Azure Machine Learning's built-in tools or custom code to fine-tune the Llama 3 model on your dataset, leveraging the compute cluster for distributed training.
Deploy Fine-tuned Model: Once fine-tuning is complete, deploy the fine-tuned Llama 3 model as a web service or integrate it into your application using Azure Machine Learning's deployment capabilities.
By leveraging Azure's cloud resources, you can access and fine-tune Llama 3 models without the need for local hardware, enabling you to take advantage of scalable compute power and streamlined deployment options.
Conclusion
Running large language models like Llama 3 8B and 70B locally has become increasingly accessible thanks to tools like ollama. By following the steps outlined in this guide, you can harness the power of these cutting-edge models on your own hardware, unlocking a world of possibilities for natural language processing tasks, research, and experimentation.
Whether you're a developer, researcher, or an enthusiast, the ability to run Llama 3 models locally opens up new avenues for exploration and innovation. With the right hardware and software setup, you can push the boundaries of what's possible with language models and contribute to the ever-evolving field of artificial intelligence.
While the 70B model offers unparalleled performance, the 8B variant strikes a balance between capability and resource requirements, making it an excellent choice for those with more modest hardware configurations. Ultimately, the decision between the two models will depend on your specific needs, available resources, and the trade-offs you're willing to make.
Subscribe to my newsletter
Read articles from Pradeep Vats directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by