Large Multimodal Models(LMMs): A Gigantic Leap in AI World
 NovitaAI
NovitaAI
Explore the transformative impact of Large Multimodal Models (LMMs) like CLIP and Flamingo, which can process and generate diverse data modalities such as text and images. Discover cutting-edge research directions, including incorporating new modalities, improving training efficiency, and generating multimodal outputs, with the potential to revolutionize industries and user interactions with AI.
Background
For a long time, machine learning models operated in one data mode: text for translation and language modeling, image for object detection and classification, and audio for speech recognition. Yet, human intelligence isn’t confined to just one modality. We read and write text, interpret images and videos, listen to music for relaxation, and rely on sounds to detect danger. To function effectively in the real world, AI must also be able to handle multimodal data.
Recognizing this, OpenAI emphasized the significance of incorporating additional modalities, like images, into Large Language Models (LLMs), marking a crucial frontier in AI research and development. This integration of additional modalities transforms LLMs into Large Multimodal Models (LMMs). Over the past year, major research labs have introduced a flurry of new LMMs, such as DeepMind’s Flamingo, Salesforce’s BLIP, Microsoft’s KOSMOS-1, Google’s PaLM-E, and Tencent’s Macaw-LLM. Even chatbots like ChatGPT and Gemini fall under the category of LMMs.
However, not all multimodal systems are LMMs. Models like Midjourney, Stable Diffusion, and DALL-E can process multiple modalities but lack a language model component. Multimodal systems can encompass a variety of scenarios: where input and output are of different modalities (e.g., text-to-image, image-to-text), where inputs are multimodal (e.g., processing both text and images), or where outputs are multimodal (e.g., generating both text and images).
What is Multimodal
Multimodal can mean one or more of the following:
Input and output are of different modalities (e.g. text-to-image, image-to-text)
Inputs are multimodal (e.g. a system that can process both text and images)
Outputs are multimodal (e.g. a system that can generate both text and images)
Why multimodal
Multimodality is indispensable in numerous use cases, particularly within industries that handle a blend of data modalities, including healthcare, robotics, e-commerce, retail, gaming, and more.
Indeed, integrating data from multiple modalities can enhance model performance significantly. It stands to reason that a model capable of learning from both text and images would outperform one limited to just one modality.
Multimodal systems offer a more adaptable interface, enabling users to interact with them in various ways depending on their preferences or circumstances. Imagine being able to pose a question by typing, speaking, or simply pointing a camera at an object.
Data modalities
Different data modalities include text, image, audio, tabular data, and more. Each modality can be translated or approximated into another form:
Audio can be depicted as images, such as mel spectrograms.
Speech can be transcribed into text, although this conversion may lose nuances like volume, intonation, and pauses.
An image can be converted into a vector, which can then be flattened and represented as a sequence of text tokens.
Videos consist of sequences of images combined with audio. However, current ML models typically treat videos solely as sequences of images, overlooking the significance of sound. This limitation is notable since sound contributes significantly to the video experience, as evidenced by 88% of TikTok users emphasizing its importance.
Text can be captured as an image simply by taking a photograph of it.
Data tables can be transformed into charts, which are essentially images.
Here are novita.ai’s various modalities:
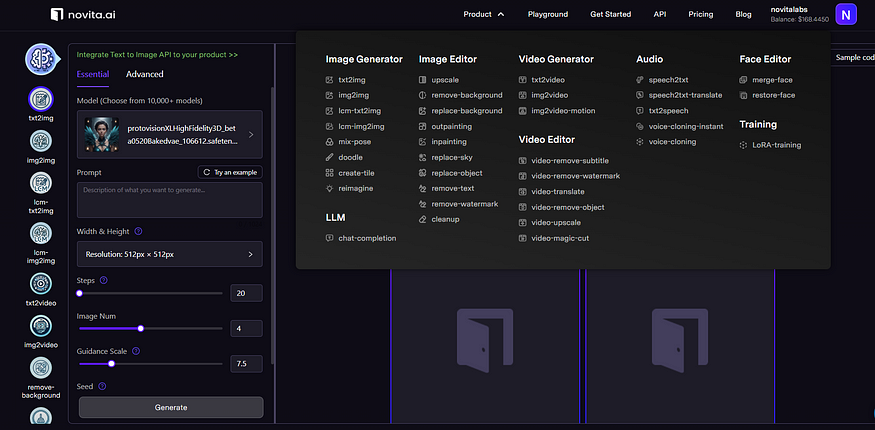
novita.ai is one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
Tasks of Multimodal
To grasp multimodal systems, examining the tasks they address proves insightful. These tasks vary widely, and their organization can take numerous forms. In literature, vision-language tasks are often categorized into two main groups: generation and vision-language understanding (VLU), which encompasses tasks not involving generation. However, it’s worth noting that the distinction between these groups is somewhat ambiguous, as the ability to generate responses inherently involves understanding as well.
Generation
In generative tasks, the output can be either unimodal (such as text, image, or 3D rendering) or multimodal. While unimodal outputs are prevalent in current models, the development of multimodal outputs is still ongoing. We will delve into multimodal outputs towards the conclusion of this post.
Image generation (text-to-image synthesis)
This task category is straightforward. Examples: Dall-E, Stable Diffusion, and Midjourney.
Text generation
A prevalent task in text generation is visual question answering (VQA), where the model is provided with both text and images to derive context. This enables scenarios where users can utilize their cameras to ask questions such as: “What’s wrong with my car?” or “How do I prepare this dish?”.
Similarly, image captioning serves as another common application. It can be integrated into text-based image retrieval systems utilized by organizations housing vast image libraries comprising product images, graphs, designs, team photos, promotional materials, and more. By automatically generating captions and metadata, AI simplifies the process of locating specific images within these collections.
Vision-language understanding
Let’s focus on two types of tasks: classification and text-driven image retrieval (TBIR).
Classification
Classification models are limited to producing outputs that fall within a predefined list of classes. This is suitable when the goal is to discern among a set number of potential outcomes. For instance, in an Optical Character Recognition (OCR) system, the task is simply to predict whether a visual corresponds to one of the recognized characters, such as a digit or a letter.
A task closely related to classification is image-to-text retrieval: given an image and a set of predefined texts, the objective is to identify the text most likely to correspond with the image. This application can be particularly useful for product image searches, such as retrieving product reviews based on a given picture.

Document processing with GPT-4V. The model’s mistake is highlighted in red.
Text-based image retrieval (image search)
Image search holds significance not only for search engines but also for enterprises aiming to sift through their internal images and documents. Some refer to text-based image retrieval as “text-to-image retrieval.”
Various approaches exist for text-based image retrieval. Two notable methods include:
Generating captions and metadata for each image, either manually or automatically (as seen in image captioning within text generation). Given a text query, the aim is to identify images whose captions or metadata closely match the query.
Training a joint embedding space for both images and text. In this approach, a text query generates an embedding, and the objective is to locate images whose embeddings are most similar to the query’s embedding.
The latter approach offers greater flexibility and is anticipated to see broader adoption. It relies on the establishment of a robust joint embedding space for both vision and language, similar to the one developed by OpenAI’s CLIP.
Key Component of Multimodal Training
At a broad level, a multimodal system comprises the following components:
Encoders for each data modality tasked with generating embeddings specific to that modality.
Mechanisms to align embeddings from different modalities within a unified multimodal embedding space.
For generative models, a language model is necessary to generate text responses. Given that inputs may include both text and visuals, innovative techniques are required to enable the language model to base its responses not only on text but also on visuals.
Ideally, as many of these components as possible should be pretrained and reusable to enhance efficiency and versatility.
Introduction to Existing Multimodal System
Selecting which multimodal systems to focus on for this post posed a challenge due to the abundance of remarkable options available. Eventually, I opted to spotlight two models: CLIP (2021) and Flamingo (2022). These choices were based on their significance, as well as the availability and clarity of public information.
CLIP made history as the first model capable of generalizing to multiple image classification tasks using zero- and few-shot learning techniques. On the other hand, while Flamingo wasn’t the initial large multimodal model capable of generating open-ended responses (Salesforce’s BLIP preceded it by 3 months), its impressive performance led many to regard it as the defining moment akin to GPT-3 within the multimodal domain.
Despite being older models, the techniques employed by CLIP and Flamingo remain relevant today. They serve as foundational pillars for comprehending newer models within the rapidly evolving multimodal landscape, where numerous innovative ideas are continually being developed.
Clip: Contrastive Language-Image Pre-training
CLIP’s major breakthrough lies in its capability to map data from different modalities — text and images — into a shared embedding space. This shared multimodal embedding space significantly simplifies tasks such as text-to-image and image-to-text.
Moreover, training this multimodal embedding space has resulted in a robust image encoder within CLIP. Consequently, CLIP demonstrates competitive zero-shot performance across various image classification tasks. The strength of this image encoder extends to other applications, including image generation, visual question answering, and text-driven image retrieval. Notably, Flamingo and LLaVA leverage CLIP as their image encoder, while DALL-E utilizes CLIP for reranking generated images. However, it remains uncertain whether GPT-4V incorporates CLIP into its architecture.
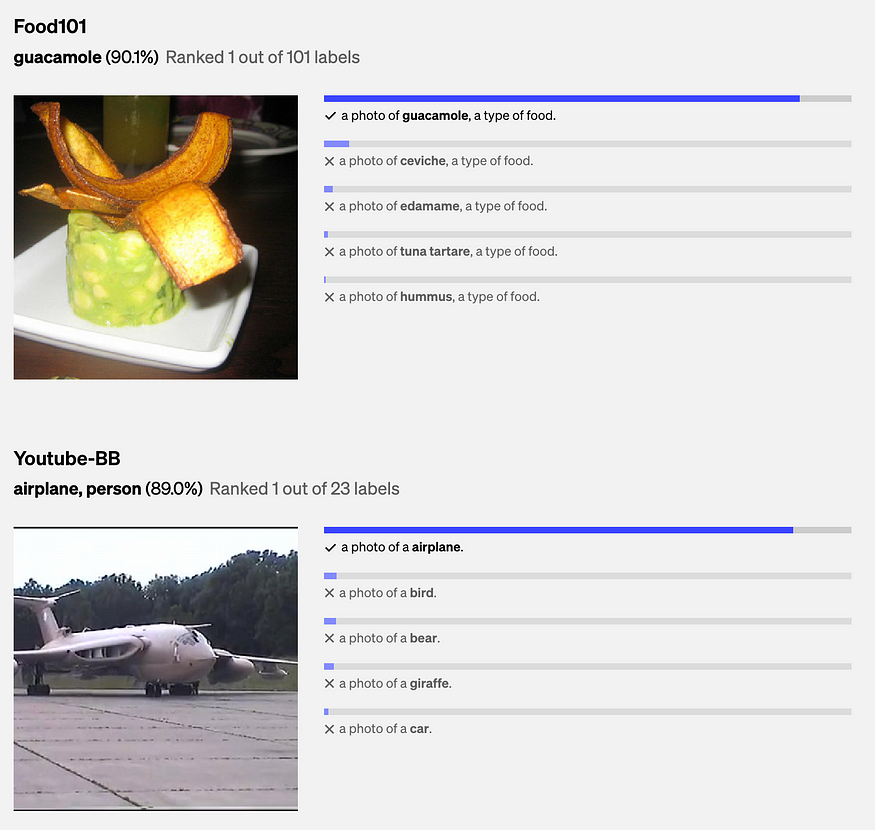
CLIP utilized natural language supervision and contrastive learning techniques, enabling the model to scale up its data and enhance the efficiency of training.
CLIP’s high-level architecture
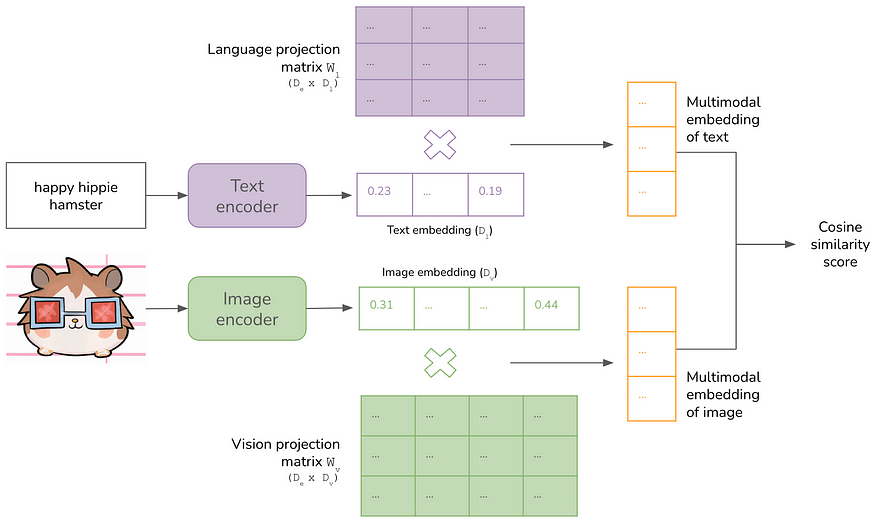
In CLIP’s architecture, both the encoders and projection matrices are trained jointly from scratch. The objective of training is to maximize the similarity scores of correct (image, text) pairs while minimizing the similarity scores of incorrect pairings, a technique known as contrastive learning.
CLIP applications
Classification
Currently, CLIP serves as a robust out-of-the-box baseline for numerous image classification tasks, either utilized in its original form or fine-tuned for specific applications.
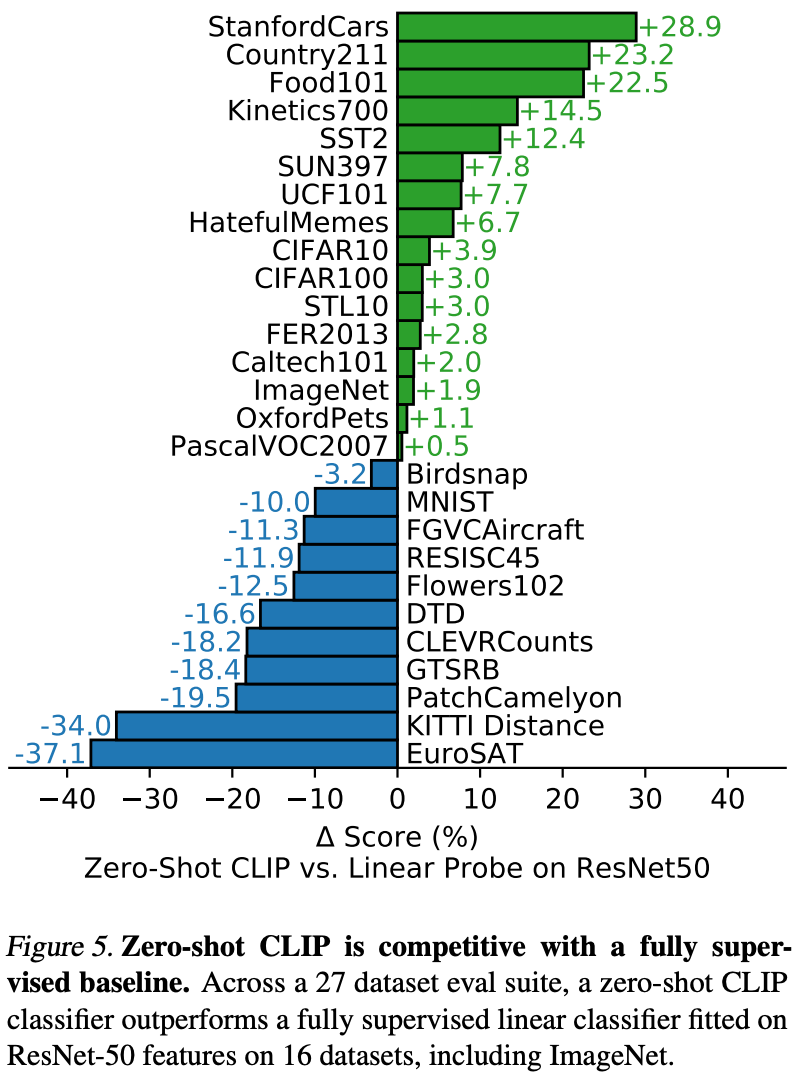
Text-based image retrieval
Given CLIP’s training process shares conceptual similarities with both image-to-text retrieval and text-to-image retrieval, it holds significant promise for broad applications like image retrieval or search. However, its performance relative to the overall state-of-the-art is notably lower in image retrieval tasks.
Efforts have been made to leverage CLIP for image retrieval. For instance, the clip-retrieval package operates as follows:
Generate CLIP embeddings for all images and store them in a vector database.
Generate a CLIP embedding for each text query.
Query the vector database for all images whose embeddings closely match the text query embedding.
Image Generation
CLIP’s joint image-text embeddings offer valuable support for image generation tasks. For instance, DALL-E (2021) utilizes CLIP to rerank a multitude of generated visuals based on a given text prompt, presenting users with the top-ranked visuals.
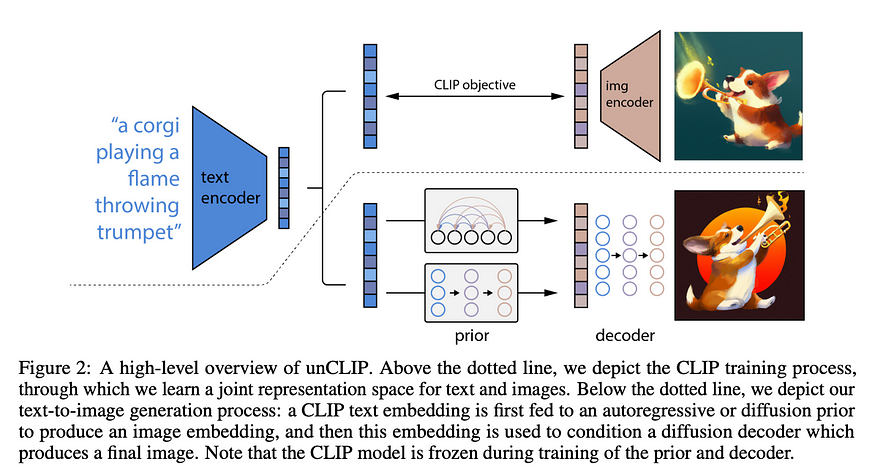
In 2022, OpenAI introduced unCLIP, a text-to-image synthesis model conditioned on CLIP latents. It comprises two primary components:
CLIP is trained and kept fixed. The pretrained CLIP model can produce embeddings for both text and images within the same embedding space.
During image generation, two steps occur: a. Utilize CLIP to generate embeddings for the given text. b. Employ a diffusion decoder to generate images conditioned on these embeddings.
Text Generation
The authors of CLIP did explore the creation of a text generation model. One variant they experimented with is known as LM RN50. However, while this model could generate text responses, its performance consistently lagged approximately 10% behind the best-performing CLIP model across all vision-language understanding tasks evaluated.
While CLIP itself is not directly utilized for text generation today, its image encoder frequently serves as the foundation for Large Multimodal Models (LMMs) capable of generating text.
Flamingo: the dawns of LMMs
In contrast to CLIP, Flamingo has the ability to produce text responses. In simplified terms, Flamingo can be viewed as CLIP combined with a language model, incorporating additional techniques to enable the language model to generate text tokens conditioned on both visual and text inputs.

Flamingo can generate text responses conditioned on both text and images
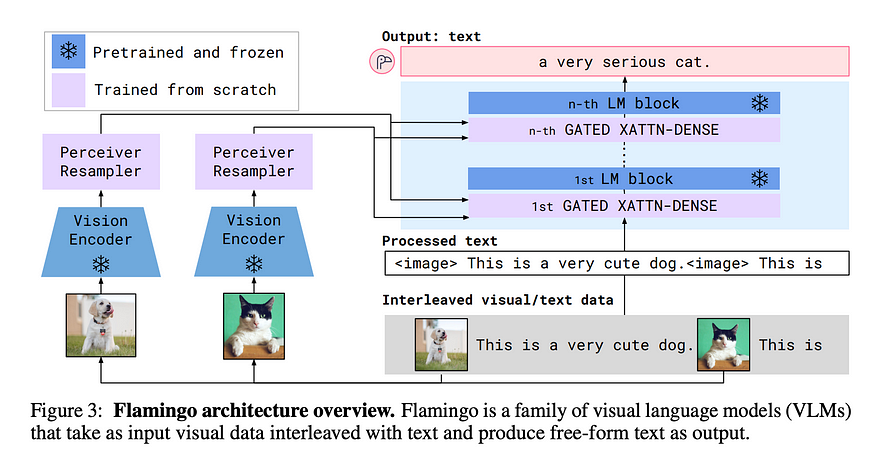
Flamingo’s high-level architecture
Flamingo can be broken down into two main components:
Vision encoder: This aspect entails training a CLIP-like model using contrastive learning. Following this, the text encoder of the model is discarded, leaving the vision encoder frozen for integration into the primary model.
Language model: Flamingo refines Chinchilla through fine-tuning to produce text tokens conditioned on both visual and textual inputs. This process involves employing language model loss and incorporating two additional components: the Perceiver Resampler and GATED XATTN-DENSE layers.
Dataset
Flamingo used 4 datasets: 2 (image, text) pair datasets, 1 (video, text) pair dataset, and 1 interleaved image and text dataset.


Flamingo’s language model
In Flamingo, Chinchilla serves as the language model, with a specific focus on freezing the 9 pretrained Chinchilla LM layers. Unlike a traditional language model, which predicts the next text token solely based on preceding text tokens.
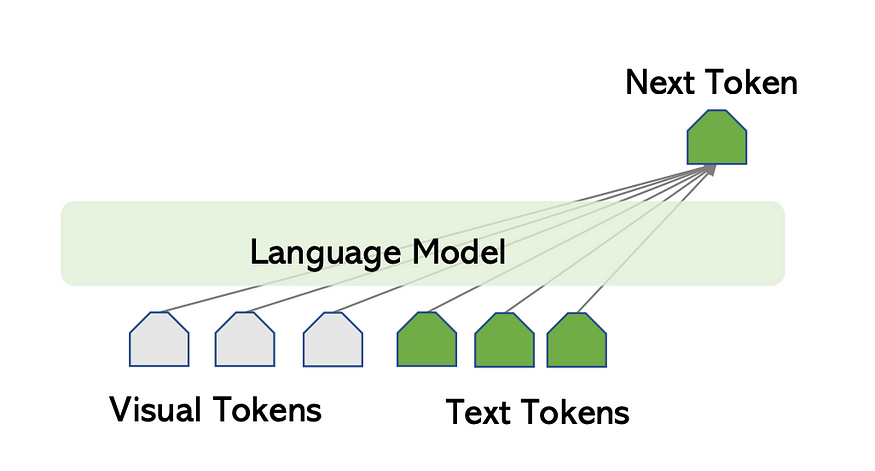
Flamingo extends this by predicting the next text token considering both the preceding text and visual tokens. This capability to generate text conditioned on both text and visual inputs is facilitated by the integration of Perceiver Resampler and GATED XATTN-DENSE layers.
CLIP vs. Flamingo
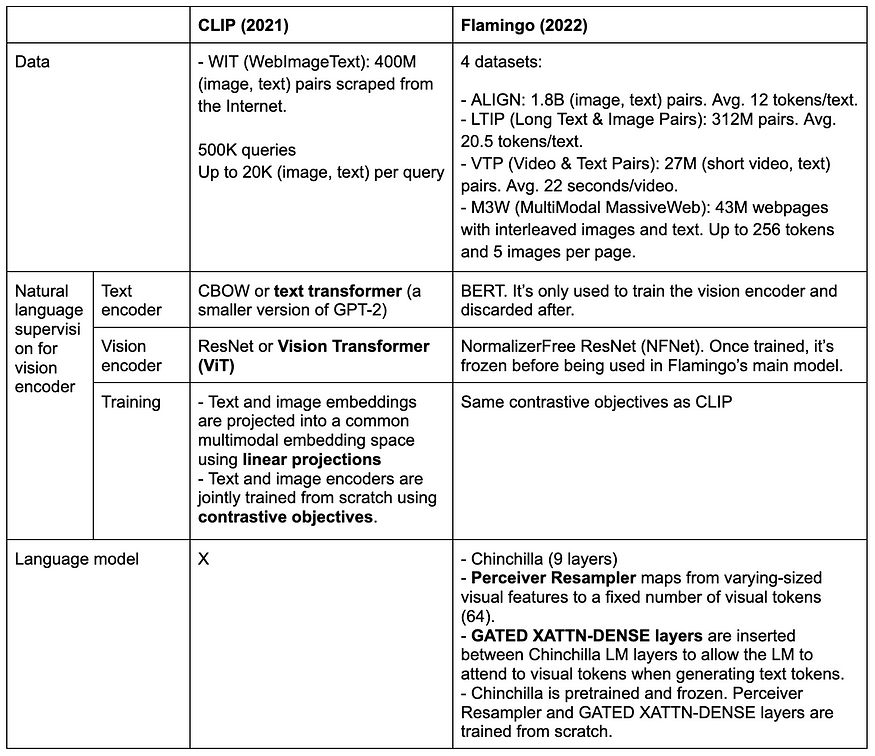
Future Directions for LMMs
CLIP has been around for 3 years, and Flamingo is nearing its second anniversary. While their architectures provide a solid foundation for understanding the construction of Large Multimodal Models (LMMs), numerous advancements have occurred in this field.
Several directions in the multimodal space are particularly intriguing to me, although this list is by no means exhaustive. The length of this post and my ongoing exploration of the subject contribute to its incompleteness. If you have any insights or recommendations, I’d greatly appreciate them!
Incorporating more data modalities
In the realm of multimodal systems, the current focus predominantly revolves around text and images. However, it’s only a matter of time before the need arises for systems capable of integrating other modalities such as videos, music, and 3D data. The prospect of having a unified embedding space accommodating all data modalities is indeed exciting.
Some noteworthy works in this area include:
ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding (Xue et al., December 2022)
ImageBind: One Embedding Space To Bind Them All (Girdhar et al., May 2023)
NExT-GPT: Any-to-Any Multimodal Large Language Model (Wu et al., September 2023)
Additionally, Jeff Dean’s ambitious Pathways project (2021) aims to “enable multimodal models that encompass vision, auditory, and language understanding simultaneously.”

Training more efficient multimodal
While Flamingo utilized 9 pretrained and frozen layers from Chinchilla, it required pretraining its vision encoder, Perceiver Resampler, and GATED XATTN-DENSE layers from scratch. Training these modules from scratch can be computationally intensive. Consequently, many recent works have focused on developing more efficient methods to bootstrap multimodal systems with reduced training from scratch.
Some of these works show promising results. For instance, BLIP-2 surpassed Flamingo-80B by 8.7% on zero-shot VQA-v2 with 54 times fewer trainable parameters.
Notable works in this domain include:
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
[LAVIN] Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
The images below are sourced from Chunyuan Li’s Large Multimodal Models tutorial at CVPR 2023, which is highly recommended for its comprehensive coverage of the subject matter.

Generating multimodal outputs
As models capable of processing multimodal inputs become increasingly prevalent, the development of multimodal output capabilities still lags behind. Many practical scenarios necessitate multimodal outputs. For instance, when soliciting an explanation from ChatGPT about RLHF, an effective response might entail the inclusion of graphs, equations, and even basic animations.
To generate multimodal outputs, a model must first produce a shared intermediate output. A critical consideration is the nature of this intermediate output.
One approach for the intermediate output is text, which subsequently guides the generation or synthesis of other actions.
For instance, CM3 (Aghajanyan et al., 2022) produces HTML markup, which can be compiled into webpages containing not only text but also formatting, links, and images. GPT-4V generates LaTeX code, which can then be reconstructed into data tables.

Conclusion
The evolution from single-modal to multimodal AI systems marks a significant advancement in artificial intelligence research and development. Models like CLIP and Flamingo have paved the way for Large Multimodal Models (LMMs), capable of processing and generating diverse data modalities such as text, images, and more. As the field continues to progress, researchers are exploring new frontiers, including incorporating additional modalities like videos and 3D data, enhancing training efficiency, and developing methods for generating multimodal outputs. These advancements hold immense promise for revolutionizing various industries and enhancing user interactions with AI systems.
Originally published at novita.ai
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.
Subscribe to my newsletter
Read articles from NovitaAI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by