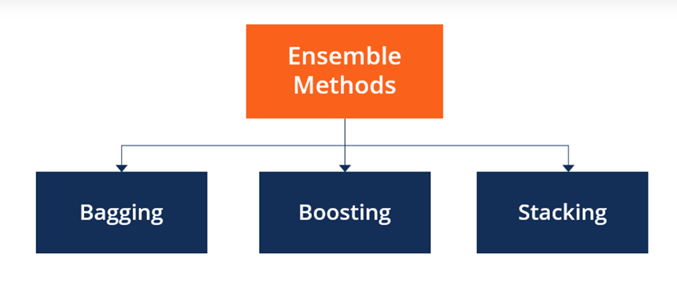
Ensemble Methods
 Yaseen G
Yaseen GA group of predictors is called an ensemble; thus, this technique is called Ensemble Learning, and an Ensemble Learning algorithm is called an Ensemble method.
Ensemble methods are techniques that aim at improving the accuracy of results in models by combining multiple models instead of using a single model. The combined models increase the accuracy of the results significantly. This has boosted the popularity of ensemble methods in machine learning.
Monitoring Ensemble Learning Models
Ensemble learning improves a model’s performance in mainly three ways:
By reducing the variance of weak learners
By reducing the variance of weak learners
By reducing the bias of weak learners, by improving the overall accuracy of strong learners.
Note:
Bagging is used to reduce the variance of weak learners. Boosting is used to reduce the bias of weak learners. Stacking is used to improve the overall accuracy of strong learners.
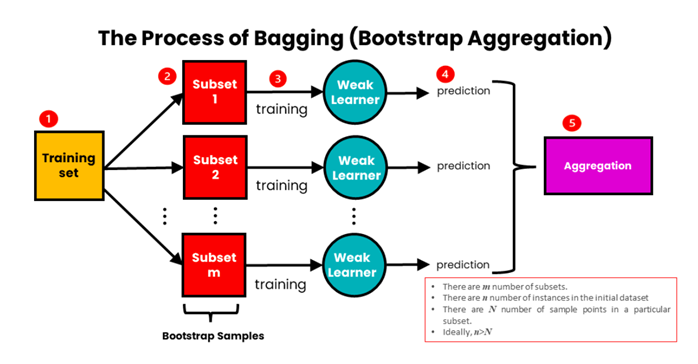
Bagging(Bootstrap Aggregating):
The idea behind bagging is combining the results of multiple models (for instance, all decision trees) to get a generalized result. There is a high chance that these models will give the same result since they are getting the same input.
Working Steps:
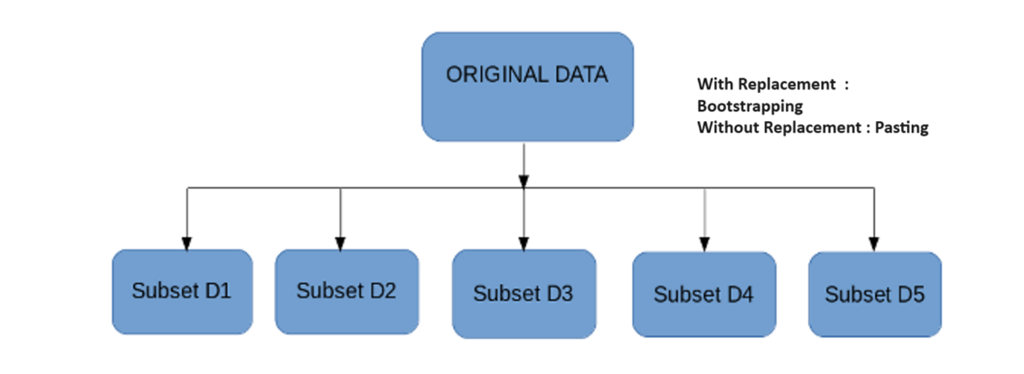
Bagging involves creating multiple subsets of the original dataset by randomly sampling with replacement (Without replacement it is “Pasting”, with replacement its “Bootstrapping”). Each subset has a smaller size than the original dataset.
On each subset, a base learning algorithm is trained independently.
Once all the base learners are trained, their predictions are combined through averaging (for regression) or voting (for classification) to make the final prediction.
We use bagging for combining weak learners of high variance. Bagging aims to produce a model with lower variance than the individual weak models.
Bootstrapping:
Involves resampling subsets of data with replacement from an initial dataset. In other words, subsets of data are taken from the initial dataset. These subsets of data are called bootstrapped datasets or bootstraps. Resampled ‘with replacement’ means an individual data point can be sampled multiple times. Each bootstrap dataset is used to train a weak learner.
Aggregating:
The individual weak learners are trained independently from each other. Each learner makes independent predictions. The results of those predictions are aggregated at the end to get the overall prediction. The predictions are aggregated using either max voting(for classification problems) or averaging(for regression problems)
We have a class in SKLearn to implement problems.
Out of the box(obb):
With bagging, some instances may be sampled several times for any given predictor, while others may not be sampled at all. By default, a BaggingClassifier() samples "m" training instances with replacement (bootstrap=True), where "m" is the size of the training set. This means that only about 63% of the training instances are sampled on average for each predictor. The remaining 37% of the training instances that are not sampled are called out-of-bag (oob) instances. Note that they are not the same 37% for all predictors Since a predictor never sees the oob instances during training, it can be evaluated on these instances, without the need for a separate validation set. You can evaluate the ensemble itself by averaging out the oob evaluations of each predictor.
Example Code:
dataset link : https://www.kaggle.com/datasets/iabhishekofficial/mobile-price-classification
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging_clf = BaggingClassifier(estimator = DecisionTreeClassifier(max_depth = 2,max_features = 10),
bootstrap = True,oob_score=True)
bagging_clf.fit(x_train,y_train)
bagging_clf.score(x_test,y_test) #accuracy score 99.75%
bagging_clf.oob_score_ # Out of the box classification
#Score ==> 92.1%
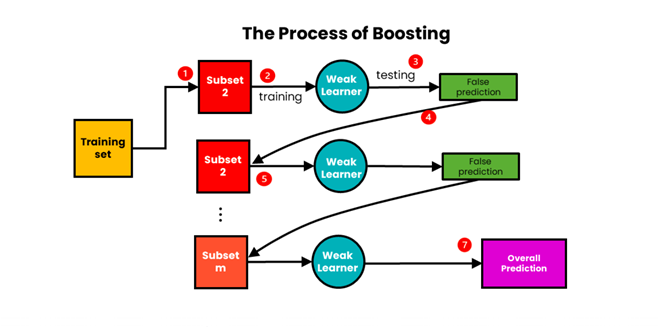
Boosting:
We use boosting for combining weak learners with high bias. Boosting aims to produce a model with a lower bias than that of the individual models.
Boosting involves sequentially training weak learners. A sample of data is first taken from the initial dataset. This sample is used to train the first model, and the model makes its prediction. The samples can either be correctly or incorrectly predicted. The samples that are wrongly predicted are reused for training the next model. In this way, subsequent models can improve on the errors of previous models. They are aggregated using weighted averaging.
Weighted averaging involves giving all models different weights depending on their predictive power. In other words, it gives more weight to the model with the highest predictive power. This is because the learner with the highest predictive power is considered the most important.
Working:
Initially, a base learner is trained on the entire dataset.
After the first iteration, the misclassified instances are assigned higher weights, while correctly classified instances are assigned lower weights. This emphasizes the importance of the misclassified instances in subsequent iterations.
Additional base learners are sequentially trained on the dataset, with each subsequent learner focusing more on the misclassified instances from the previous iterations. This iterative process continues until a predefined number of base learners are trained or until a certain level of accuracy is achieved.
Boosting algorithms, such as AdaBoost (Adaptive Boosting) and Gradient Boosting Machines (GBM), are widely used in practice due to their ability to improve the accuracy of weak learners and handle complex datasets effectively.
AdaBoost:
To build an AdaBoost classifier, a first base classifier (such as a DecisionTree) is trained and used to make predictions on the training set. The relative weight of misclassified training instances is then increased. A second classifier is trained using the updated weights and again it makes predictions on the training set, weights are updated.
Scikit-Learn actually uses a multiclass version of AdaBoost called SAMME16 (which stands for Stagewise Additive Modeling using a Multiclass Exponential loss function). When there are just two classes, SAMME is equivalent to AdaBoost. Moreover, if the predictors can estimate class probabilities (i.e., if they have a predict_proba() method), Scikit-Learn can use a variant of SAMME called SAMME.R (the R stands for “Real”), which relies on class probabilities rather than predictions and generally performs better.
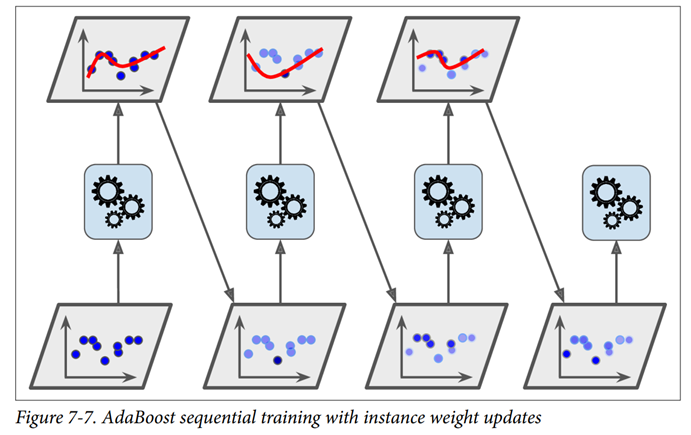
We have class for AdaBoost in sklearn package
sklearn.ensemble.AdaboostClassifier()
sklearn.ensemble.AdaboostRegressor()
from sklearn.ensemble import AdaBoostClassifier
adaboost_clf = AdaBoostClassifier(estimator = DecisionTreeClassifier(max_depth = 1),learning_rate = 0.5)
adaboost_clf.fit(x_train,y_train)
adaboost_clf.score(x_test,y_test) # returns the accuracy score
adaboost_clf.learning_rate #Returns learing rate of the model
Gradient Boosting :
Gradient boosting is a machine learning ensemble technique that combines the predictions of multiple weak learners, typically decision trees, sequentially. It aims to improve overall predictive performance by optimizing the model’s weights based on the errors of previous iterations, gradually reducing prediction errors and enhancing the model’s accuracy.
Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor. However, instead of tweaking the instance weights at every iteration as AdaBoost does, this method tries to fit the new predictor to the residual errors made by the previous predictor.
for detailed implementation and see how it works:
Watch out my GitHub Jupiter notebook program:
https://github.com/yaseeng-md/graient_boosting_implementation-/tree/main
References:
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/
https://www.youtube.com/watch?v=OtD8wVaFm6E
https://www.youtube.com/watch?v=C6aDw4y8qJ0
Book:
Hands-on Machine Learning with Scikit Learn and TensorFlow (Chapter 7: Ensemble Learning and Random Forests)
Subscribe to my newsletter
Read articles from Yaseen G directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by