Benchmarking Hetzner's Storage Classes for Database Workloads on Kubernetes
 Sven Eliasson
Sven Eliasson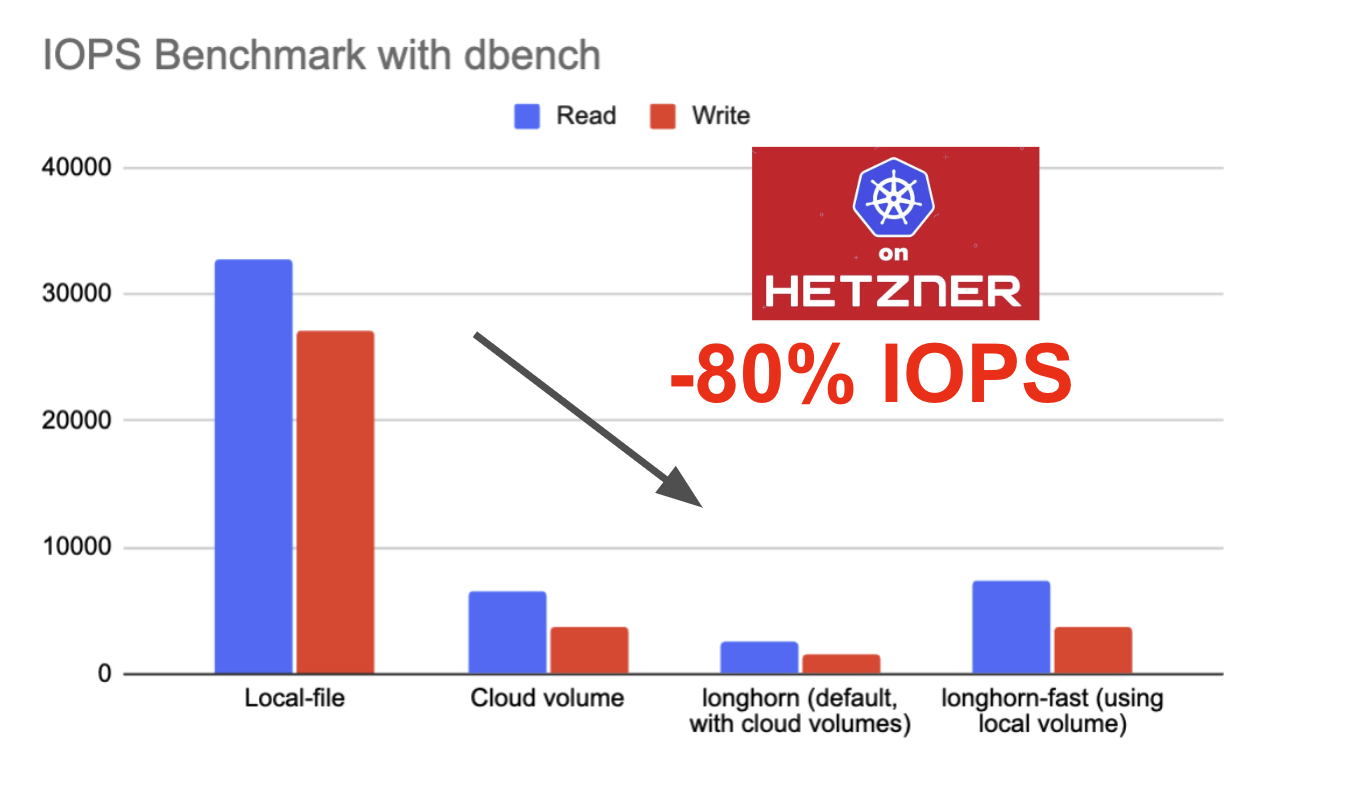
TLDR: Running Kubernetes on Hetzner offers cost-effective options, but handling production workloads, especially stateful ones like databases, raises concerns. Hetzner provides instance and cloud volume storage options with significant differences in IOPS performance. Longhorn, a distributed block storage system, can be used to leverage local volumes, but benchmarks show a slowdown compared to raw local files. Probably host a datatbase either on a dedicated host or use a hosted option instead.
Running Kubernetes on Hetzner is likely one of the most cost-effective options available. The Hetzeners Terrraform Kubernetes project simplifies the process of setting up a basic cluster within minutes. However, is this sufficient for handling production workloads?
One controversial topic about running a Kubernetes cluster is whether one should run stateful workloads like databases on Kubernetes. There are valid arguments for both sides. I used to avoid running databases on Kubernetes, but changed my mind. I think the widespread adoption of Kubernetes operators, including those for most databases, has changed the game. There are battle-proven operators that handle most of the pain points. However, there is one critical issue those operators cannot solve: IOPS.
You can increase the computing power of a database as much as you like, but if the IOPS are low, the database performance will suffer. Ultimately, you have to retrieve data from a disk, which significantly hampers query performance. In this short article, I intend to outline my benchmarks for different storage options.
Kubernetes on Hetzner storage options
There are two main types of storage options available on the Hetzner Cloud:
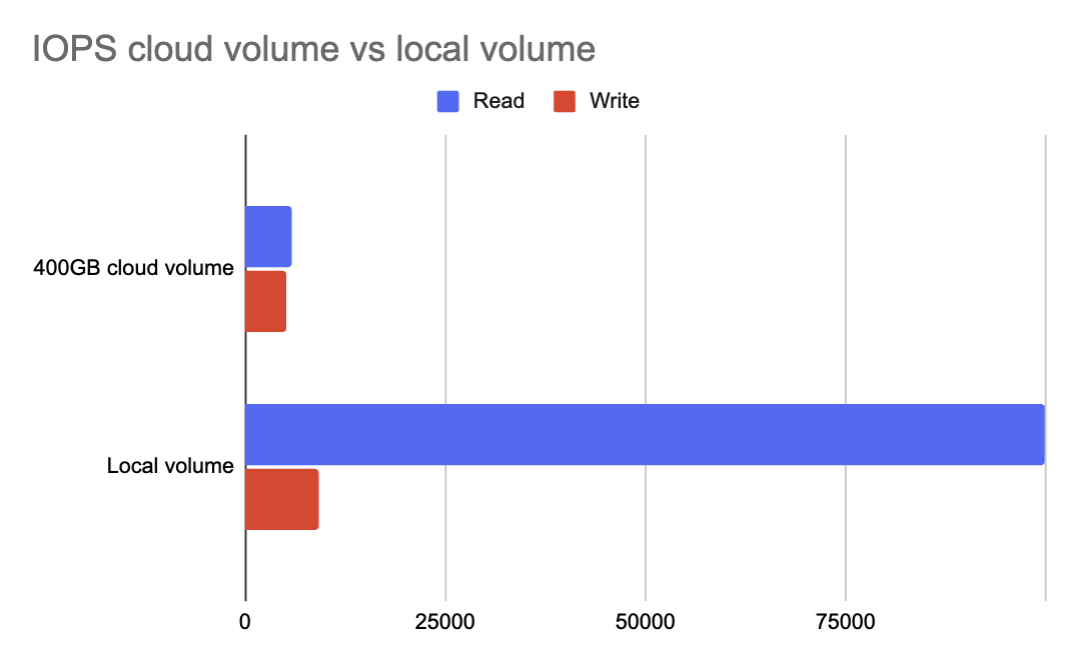
Instance volume storage: This is the NVMe storage linked to the node you rent. This volume scales only with the number of CPU and Memory you choose, making it quite costly.
Cloud volume storage: This is a block storage volume that is relatively inexpensive but offers lower performance.
The difference in IOPS is significant. For a medium-sized instance, the read IOPS on a local volume are 17 times higher than on cloud storage. You can find a detailed benchmark of IOPS performance for all instance types here: https://pcr.cloud-mercato.com/providers/hetzner/flavors/ccx21/performance/iops
In Hetzner's Kubernetes solution, there are three built-in storage classes that can be used out of the box:
hcloud-volumes: This is a block storage drive, the slower option.
longhorn-volumes: Longhorn is an open-source, distributed block storage system. It can optionally utilize the local drive of each node.
local-file: This is Rancher's implementation that simplifies the use of local host files as a volume.
Using local files in Kubernetes has several drawbacks and should generally be avoided. These files are inherently tied to specific hosts, complicating adaptation to changes in node architecture. This approach also introduces security vulnerabilities and significantly increases maintenance complexity.
Longhorn can be enabled during cluster installation using Terraform, and it aims to make use of local volumes. To achieve this, you must configure Longhorn as described here: https://gist.github.com/ifeulner/d311b2868f6c00e649f33a72166c2e5b
In summary: You need to enable the default disk on nodes first via settings.
defaultSettings:
createDefaultDiskLabeledNodes: true
kubernetesClusterAutoscalerEnabled: true # if autoscaler is active in the cluster
defaultDataPath: /var/lib/longhorn
# ensure pod is moved to an healthy node if current node is down:
node-down-pod-deletion-policy: delete-both-statefulset-and-deployment-pod
Label the nodes and assign a portion of the drive to a disk type "nvme":
kubectl label node <node> node.longhorn.io/create-default-disk='config'
kubectl annotate node <storagenode> node.longhorn.io/default-disks-config='[ { "path":"/var/lib/longhorn","allowScheduling":true, "storageReserved":21474836240, "tags":[ "nvme" ]}, { "name":"hcloud-volume", "path":"/var/longhorn","allowScheduling":true, "storageReserved":10737418120,"tags":[ "ssd" ] }]'
Now you can define a longhorn storage clas0 that will utilize the nvme disk like this:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-fast
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880" # 48 hours in minutes
fromBackup: ""
fsType: "ext4"
diskSelector: "nvme"
Ok, we are ready to go. Lets benchmark!
Benchmark storage IOPS for a given storage class in Kubernetes.
We need a simple solution to benchmark a given storage class. I used dbbench's docker container to spin up a simple benchmark job in kubernetes. First we need to define some sample PVCs to work with.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench-pv-claim-localpath
spec:
storageClassName: local-path
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench-pv-claim-longhorn
spec:
storageClassName: longhorn-fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench-pv-claim-hcloud
spec:
storageClassName: hcloud-volumes
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
We utilize kubernetes jobs to run the individual benchmark.
---
apiVersion: batch/v1
kind: Job
metadata:
name: db-bench-01
spec:
template:
spec:
containers:
- name: dbench
image: storageos/dbench:latest
env:
- name: DBENCH_MOUNTPOINT
value: /data
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench-pv-claim-longhorn
#claimName: dbench-pv-claim-hcloud
#claimName: dbench-pv-claim-localpath
A typical benchmark result will look like this:
Random Read/Write IOPS: 32.7k/27.1k. BW: 2854MiB/s / 2140MiB/s
Average Latency (usec) Read/Write: 325.47/216.90
Sequential Read/Write: 5741MiB/s / 4689MiB/s
Mixed Random Read/Write IOPS: 23.8k/7946
I ran benchmarks for all storage options and got a rather disappointing result. Longhorn adds some overhead, causing a 4.5x slowdown compared to a raw local file, and only slightly outperforms a cloud volume.
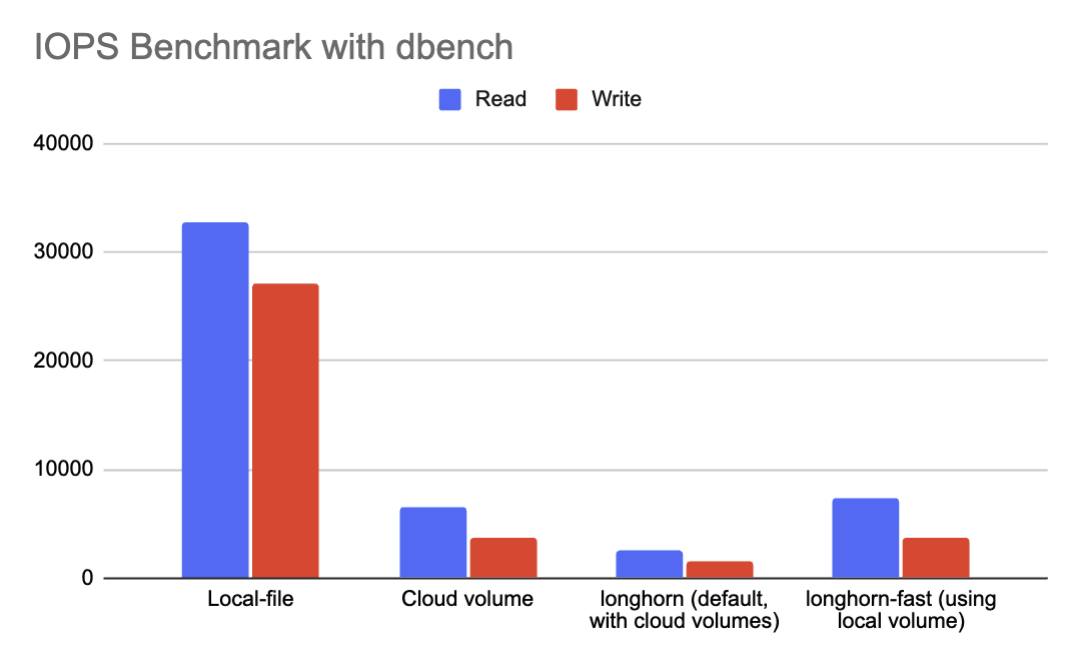
I'm not sure if there are optimizations available for Longhorn. I halted my evaluation here; it appears that using a local file on the host node might be the best choice for a database workload.
In my upcoming post, I will share my experience of running a database workload on Hetzner in production using local files.
Subscribe to my newsletter
Read articles from Sven Eliasson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sven Eliasson
Sven Eliasson
TimeSeries Expert Full stack, DevOps Kubernetes, Clickhouse DB