Monitoring PostgreSQL Activity
 Itay Braun
Itay Braun
Tracking PostgreSQL Performance History
PostgreSQL is a powerful database system, but it doesn't keep a detailed history of its performance. If you want to know things like "How many transactions happened in 'db_2' every day over the last week?" or "Which query took the longest time to run in the last 24 hours?", you need to record this information yourself.
To capture these performance snapshots, you can use advanced monitoring tools like Prometheus or Metis, but there's also a straightforward way to do it with native PostgreSQL code. In this blog post, we'll show you a simple method for tracking PostgreSQL activity. This approach helps you gather the data you need to answer important questions about your database's performance over time.
What Is Metis Light?
Metis Light is a native solution designed to help you monitor and log PostgreSQL performance metrics using only SQL. This lightweight approach allows you to create a basic system for capturing key data points and storing them for future analysis.
No need of an Agent. Use
pg_cronto schedule the jobs.Data stored in a new DB called
metis.Built-in views to view the historical data.
Basic data cleaning.
Co-Pilot for DB Ops
I'm developing a co-pilot for database operations. Every recent post here is related to this huge project. The primary objective is to allow users to inquire about historical performance trends and investigate recent changes. This co-pilot will help answering questions such as identifying queries that ran significantly slower in the past hour compared to their typical behavior over the previous week.
Flow
Create a new DB called
metis.Create the extension
pg_stat_statements.Create the extension
pg_cron.Create a table to store the DB activity.
Create a function to take a snapshot of the DB activity.
Create a new pg_cron job to take a snapshot every 1 minute.
Create a view to view the data
Optional - View the DB performance history using a Jupyter Notebook or a Grafana report.
Create a new DB
The best practice is not to change any existing schema.
DO $$
BEGIN
IF NOT EXISTS (
SELECT * FROM pg_database
WHERE datname = 'metis_1'
) THEN
CREATE DATABASE metis_1;
ELSE
RAISE NOTICE 'The database metis_1 already exist.';
END IF;
END
$$;
Create the extension pg_stat_statements in the new DB.
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
Create a new schema. I prefer not using the public schema.
CREATE SCHEMA IF NOT EXISTS metis;
Create a table to store the DB activity snapshots
CREATE TABLE IF NOT EXISTS metis.pg_stat_database_history (
datid OID, -- Database ID
datname TEXT, -- Database name
numbackends INTEGER, -- Number of active connections
xact_commit BIGINT, -- Total number of transactions committed
xact_rollback BIGINT, -- Total number of transactions rolled back
blks_read BIGINT, -- Total number of disk blocks read
blks_hit BIGINT, -- Total number of disk blocks found in shared buffers
tup_returned BIGINT, -- Total number of tuples returned by queries
tup_fetched BIGINT, -- Total number of tuples fetched by queries
tup_inserted BIGINT, -- Total number of tuples inserted
tup_updated BIGINT, -- Total number of tuples updated
tup_deleted BIGINT, -- Total number of tuples deleted
conflicts BIGINT, -- Number of query conflicts
temp_files BIGINT, -- Number of temporary files created
temp_bytes BIGINT, -- Total size of temporary files
deadlocks BIGINT, -- Total number of deadlocks detected
blk_read_time DOUBLE PRECISION, -- Time spent reading blocks (in milliseconds)
blk_write_time DOUBLE PRECISION, -- Time spent writing blocks (in milliseconds)
stats_reset TIMESTAMP, -- Timestamp of the last statistics reset
time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- Timestamp of data insertion
);
Create a function to take a snapshot. The best practice is to simply the cron jobs by calling a function, rather than a long SQL.
Notice the function excluded the databases template0 and template1. It also ignores the backend processes shown as a "NULL" db.
CREATE OR REPLACE FUNCTION metis.insert_pg_stat_database_history()
RETURNS VOID AS $$
BEGIN
-- Insert the current data from pg_stat_database into metis.pg_stat_database_history
INSERT INTO metis.pg_stat_database_history (
datid,
datname,
numbackends,
xact_commit,
xact_rollback,
blks_read,
blks_hit,
tup_returned,
tup_fetched,
tup_inserted,
tup_updated,
tup_deleted,
conflicts,
temp_files,
temp_bytes,
deadlocks,
blk_read_time,
blk_write_time,
stats_reset,
time -- Default value of CURRENT_TIMESTAMP
)
SELECT
datid,
datname,
numbackends,
xact_commit,
xact_rollback,
blks_read,
blks_hit,
tup_returned,
tup_fetched,
tup_inserted,
tup_updated,
tup_deleted,
conflicts,
temp_files,
temp_bytes,
deadlocks,
blk_read_time,
blk_write_time,
stats_reset,
CURRENT_TIMESTAMP -- Insert timestamp
FROM pg_stat_database
WHERE datname NOT IN ('template1', 'template0')
AND datname IS NOT NULL;
END;
$$ LANGUAGE plpgsql;
Create a view. Data is grouped by 10 minutes
CREATE VIEW metis.v_pg_stat_database_history
AS
SELECT *
FROM (
WITH max_values_per_10min AS (
-- Group by 10-minute intervals and find the maximum values for each group
SELECT
date_bin('10 minutes', time, date_trunc('hour', time)) AS rounded_time,
datname,
MAX(xact_commit) AS max_xact_commit,
MAX(xact_rollback) AS max_xact_rollback,
MAX(blks_read) AS max_blks_read,
MAX(blks_hit) AS max_blks_hit,
MAX(tup_returned) AS max_tup_returned,
MAX(tup_fetched) AS max_tup_fetched,
MAX(tup_inserted) AS max_tup_inserted,
MAX(tup_updated) AS max_tup_updated,
MAX(tup_deleted) AS max_tup_deleted,
MAX(conflicts) AS max_conflicts,
MAX(temp_files) AS max_temp_files,
MAX(temp_bytes) AS max_temp_bytes,
MAX(deadlocks) AS max_deadlocks,
MAX(blk_read_time) AS max_blk_read_time,
MAX(blk_write_time) AS max_blk_write_time
FROM
metis.pg_stat_database_history
GROUP BY
rounded_time,
datname
)
SELECT
rounded_time,
datname,
max_xact_commit - LAG(max_xact_commit) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_xact_commit,
max_xact_rollback - LAG(max_xact_rollback) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_xact_rollback,
max_blks_read - LAG(max_blks_read) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_blks_read,
max_blks_hit - LAG(max_blks_hit) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_blks_hit,
max_tup_returned - LAG(max_tup_returned) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_tup_returned,
max_tup_fetched - LAG(max_tup_fetched) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_tup_fetched,
max_tup_inserted - LAG(max_tup_inserted) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_tup_inserted,
max_tup_updated - LAG(max_tup_updated) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_tup_updated,
max_tup_deleted - LAG(max_tup_deleted) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_tup_deleted,
max_conflicts - LAG(max_conflicts) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_conflicts,
max_temp_files - LAG(max_temp_files) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_temp_files,
max_temp_bytes - LAG(max_temp_bytes) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_temp_bytes,
max_deadlocks - LAG(max_deadlocks) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_deadlocks,
max_blk_read_time - LAG(max_blk_read_time) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_blk_read_time,
max_blk_write_time - LAG(max_blk_write_time) OVER (PARTITION BY datname ORDER BY rounded_time) AS diff_blk_write_time
FROM
max_values_per_10min
ORDER BY
datname,
rounded_time desc
) AS T1
Create a new Cron Job using pg_cron
Create the extension pg_cron.
REMEMBER! The extension can be created in ONE db only. I assume this DB is not the new metis one. In this example I used a PG server on Tembo.io PGaaS. The extension pg_cron was created in the DB called postgres.
We'll use the function cron.schedule_in_database to run a job on another database, in this case metis.
The job takes the snapshot directly from the metis DB since the view pg_stat_database exist in this DB and contains data about every other DB. Later we'll see more advanced jobs using db_link.
The job runs every 1 minute.
SELECT cron.schedule_in_database('insert_pg_stat_database_history',
'* * * * *',
'SELECT metis.insert_pg_stat_database_history();',
'metis_1');
check the job history to ensure it's functioning correctly
SELECT *
FROM cron.job_run_details jrd
WHERE jrd.jobid = (SELECT jobid FROM cron.job WHERE jobname = 'insert_pg_stat_database_history')
View DB Activity History
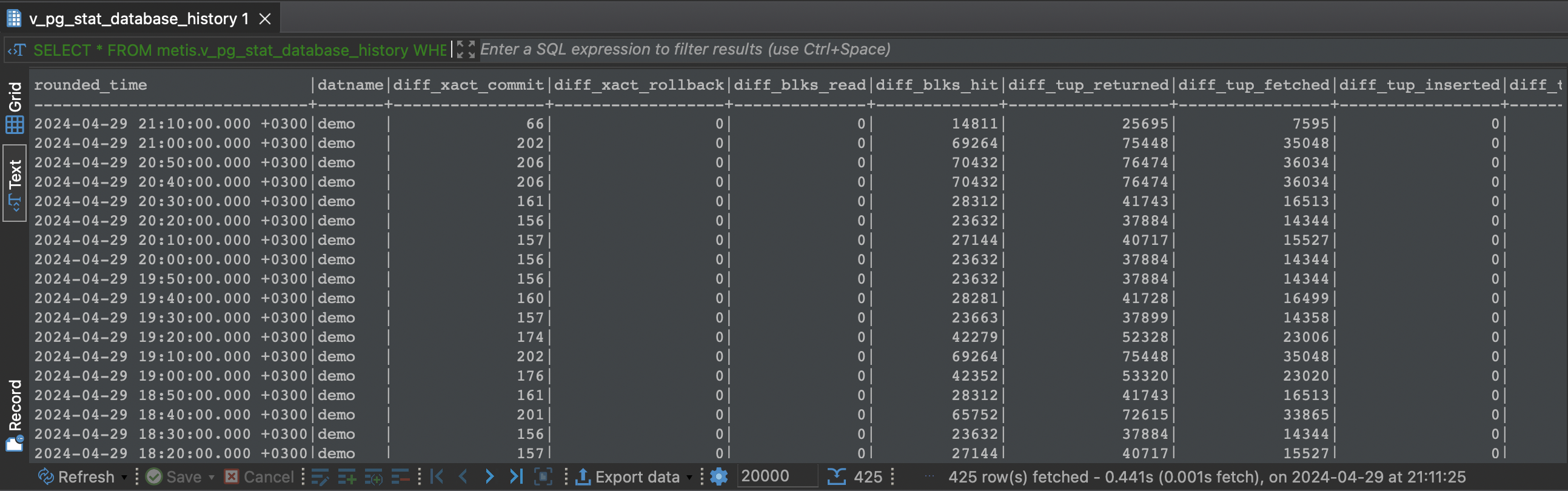
The view uses hard-coded time buckets (data bins) of 10 minutes.
SELECT *
FROM metis.v_pg_stat_database_history
WHERE datname = 'demo'
Cleaning the Data
In PostgreSQL, certain performance metrics, like the number of transactions, can get reset under certain conditions. This behavior can lead to unexpected results when analyzing data.
Consider this scenario:
You check the transaction count at 09:00 and it shows 1,000,000.
At 09:01, it's 1,000,300. That indicates 300 transactions occurred in that time frame.
You check again at 09:02 and find only 70 transactions, you can't be sure how many actually happened between 09:01 and 09:02—it could be 70, or it could be a lot more if the value got reset.
This is why taking frequent snapshots of the data is crucial. By doing so, you can minimize the impact of these resets and get a more accurate view of what's happening in the database over time.
It's also important to ignore any differences in data that suggest a negative change (like seeing 70 after 1,000,300), as that could indicate a reset or other anomaly, not actual database activity.
Here is an example of such data reset. Cleaning the data means a bucket of 10 minutes will have 9 samples of valid data and one "junk row" which should be discarded.

Next Tasks
Teach the DB Ops co-pilot to use this data to respond to questions about database activity.
Develop an installer.
Track the size and activity of each database's tables.
Keep an eye on the top queries for each database.
Create a job to remove outdated records.
Subscribe to my newsletter
Read articles from Itay Braun directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by