Retrieval Augmentation Generation Using Spring AI
 Vineeta
Vineeta
With technological advancements, the AI field is booming, leading to the release of numerous LLM models typically trained on extensive general datasets rather than specific domain or enterprise data. For instance, if an organization has its unique employee policies and an employee attempts to seek answers regarding these policies on a ChatGPT interface, the system might either generate incorrect information or respond that it lacks the necessary details on the subject.
To address this issue, the following approaches can be taken:
Provide the organization-specific data to the current LLM by retraining the model, also known as finetuning.
Develop a new model tailored to enterprise data.
Implement retrieval augmented generation or prompt stuffing.
The two approaches mentioned earlier are either costly in terms of data or hardware, or they pose security risks associated with exposing enterprise data to the outside world.
This is where the third approach mentioned above, RAG, comes into play. Retrieval-augmented generation (RAG) is a method that improves the precision and dependability of generative AI models by incorporating information obtained from external sources.
Terminologies
Before delving into the workflow of Retrieval-augmented generation (RAG), let's first grasp some core terminologies that form the foundation of this architecture.
Embeddings
In the context of Retrieval-augmented generation (RAG), let's consider the concept of Embeddings. For instance, if we compare the sentences "He runs every morning" and "Each morning he jogs," despite the different wording, they convey the same meaning, indicating the same activity. This similarity in meaning is crucial for retrieving data using natural language. Embeddings serve as vector representations of words, sentences, and documents, enabling us to retrieve data effectively based on natural language understanding.
Vector Store
The data transformed into embeddings is kept in a vector store database, which functions as an embedding database capable of storing embeddings and their associated metadata, embedding documents and queries, and searching embeddings. This setup enables the retrieval of data according to its semantic similarity.
Some examples of Vector DB are:
Chroma
Pinecone
Qdrant, etc
RAG Architecture
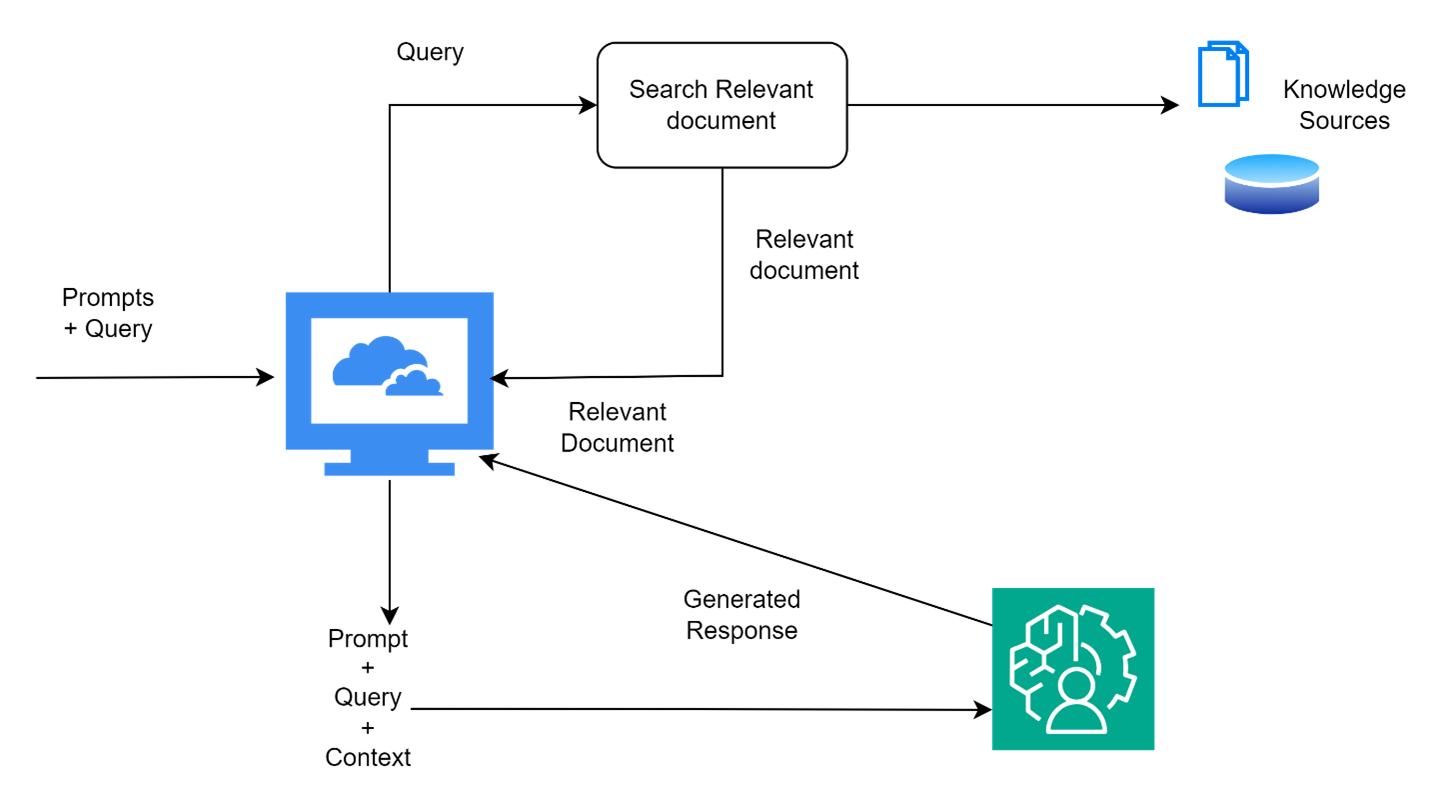
The process begins with a prompt and a user query.
The query is used to fetch relevant documents through semantic search in knowledge sources.
Once relevant documents are retrieved, they are returned to the application.
The application utilizes these documents to generate a template using the prompt, user query, and context (retrieved documents are used as context here).
This template is then given to the LLM. The LLM, using the prompt, user query, and context, generates the responses.
The responses are sent back to the client application.
RAG Based Architecture for QnA Use Case
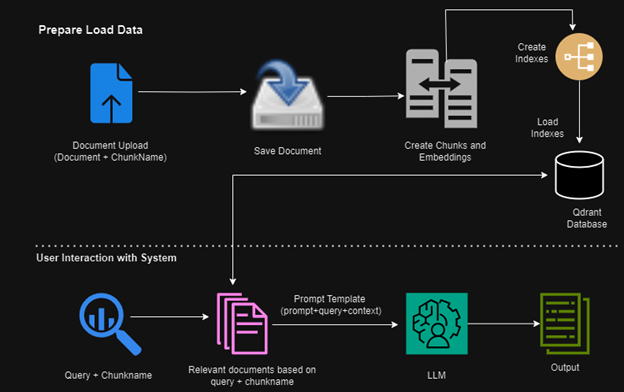
The image above illustrates a fundamental workflow for implementing Retrieval-augmented generation (RAG) for structured or unstructured enterprise data.
Let's break down the workflow above into two steps:
RAG Ingestion - preparing and loading data.
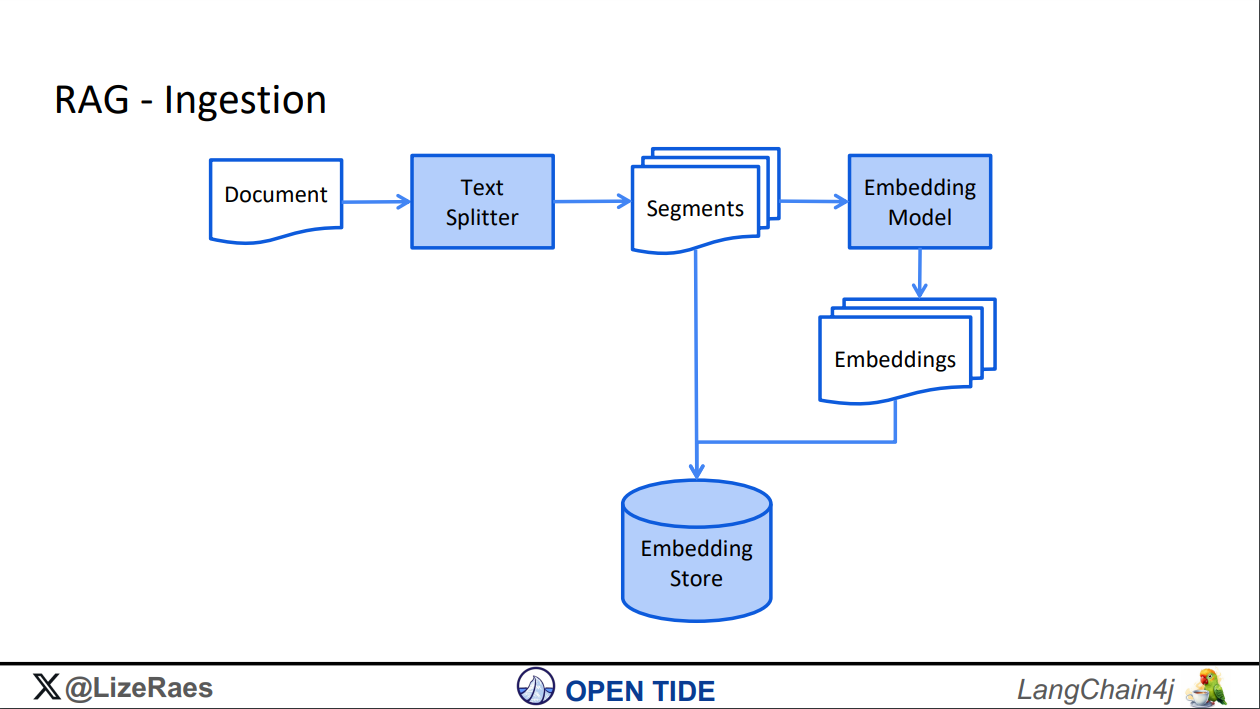
Image Credits -https://www.jfokus.se/jfokus24-preso/Java-Meets-AI--How-to-build-LLM-Powered-Applications-with-LangChain4j.pdf
At this stage, embeddings are created for the uploaded documents, such as PDFs. This process involves splitting the PDF content into segments using a text splitter. These segments are then passed to an embedding model, such as the Azure OpenAI model listed below. Once the embeddings are generated, they are stored in a vector store database like Qdrant.
RAG Retrieval - user interaction with the system
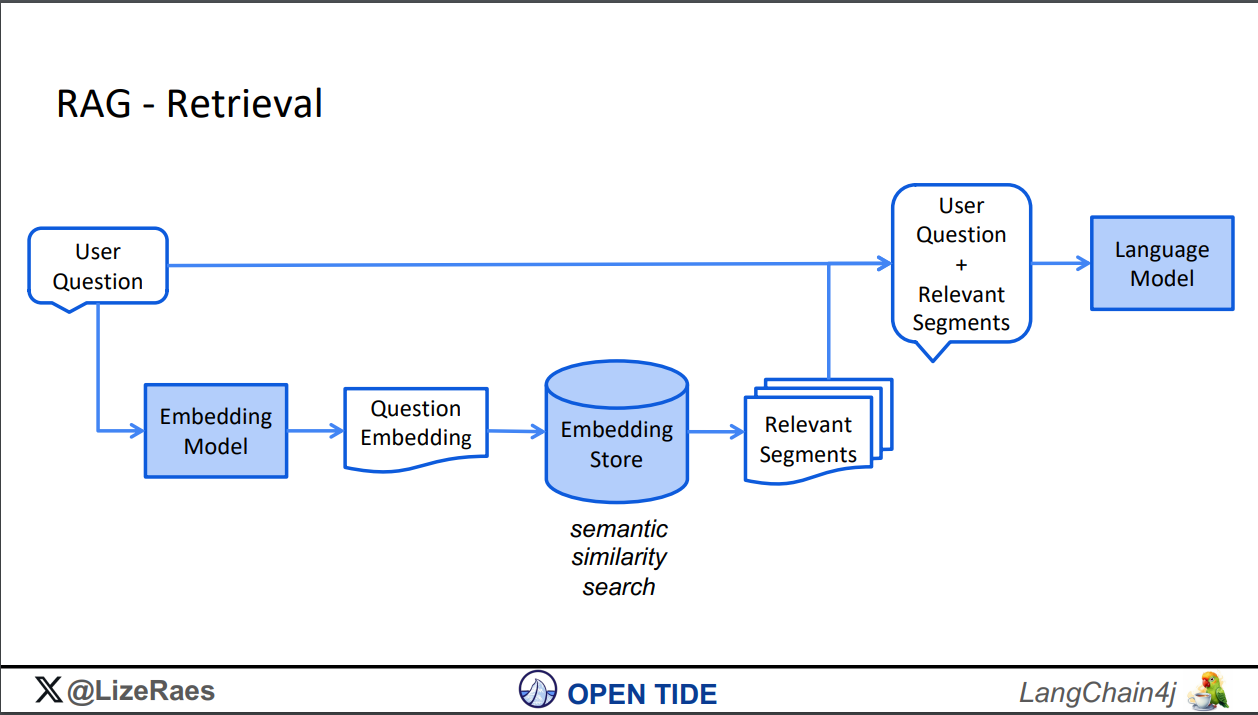
Image Credits -https://www.jfokus.se/jfokus24-preso/Java-Meets-AI--How-to-build-LLM-Powered-Applications-with-LangChain4j.pdf
Now that we have the data loaded into the vector database, during this phase, the user query goes through the same embedding model to create a vector. This vector is then used to check for semantic similarity between the query vector and the stored/loaded vectors. The segments that are semantically similar are retrieved and used to provide context to the user query. This contextualized query is then passed to the LLM model to perform various Gen AI tasks such as summarization, content generation, etc., using enterprise data.
Gen-AI Models
The following section describes Azure OpenAI models that can be utilized to implement a QnA generative AI application.

Now, let's see how to build the question-answering system using the Spring Starter dependency, Spring AI Build, designed specifically for creating generative AI applications. It acts as a wrapper for interacting with LLM models and embedding vector stores.
Spring AI
Spring AI is an application framework designed for AI engineering, aiming to incorporate Spring ecosystem design principles into the AI domain. It emphasizes portability and modular design, advocating for the use of POJOs as fundamental components within an AI application.
Let's begin configuring the Spring Boot application for generative AI.
The following class dependencies are necessary in the classpath for configuration. Please refer to the screenshot below.
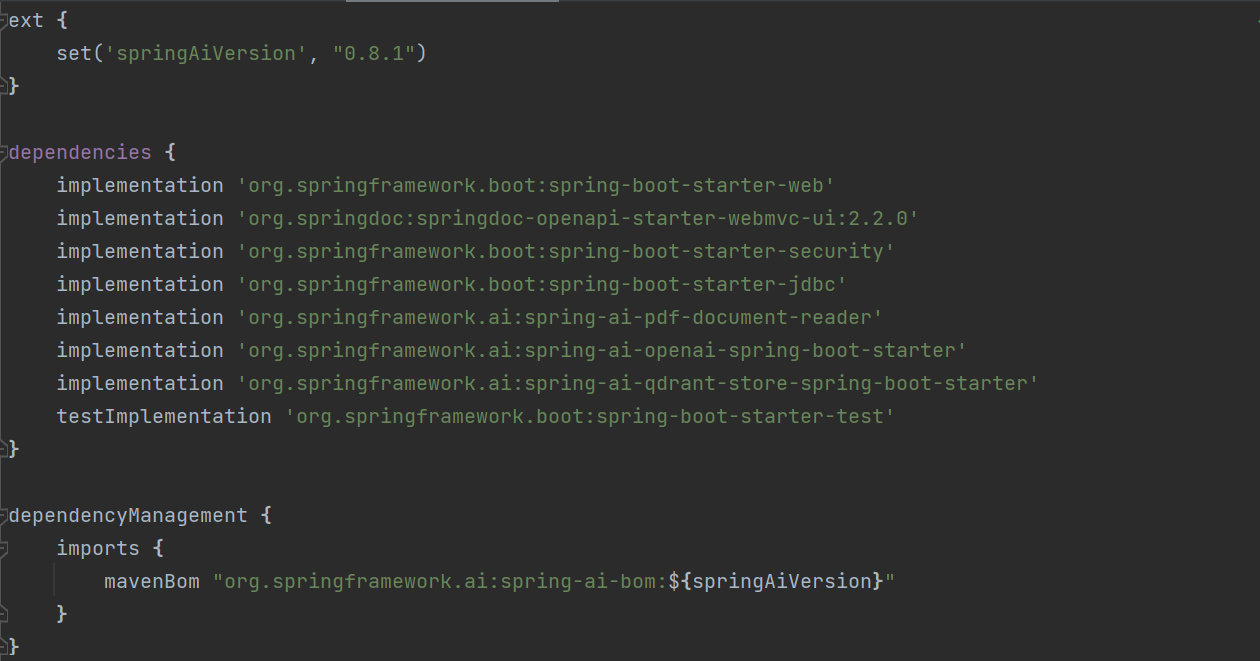
All required class path dependencies are described below:
org.springframework.ai:spring-ai-pdf-document-reader - This class provides methods for reading and processing PDF documents.
org.springframework.ai:spring-ai-openai-spring-boot-starter - Spring AI provides Spring Boot auto-configuration for the OpenAI Chat Client.
org.springframework.ai:spring-ai-qdrant-store-spring-boot-starter -
Qdrant is accessible as a supported vector database for utilization in Spring AI projects.
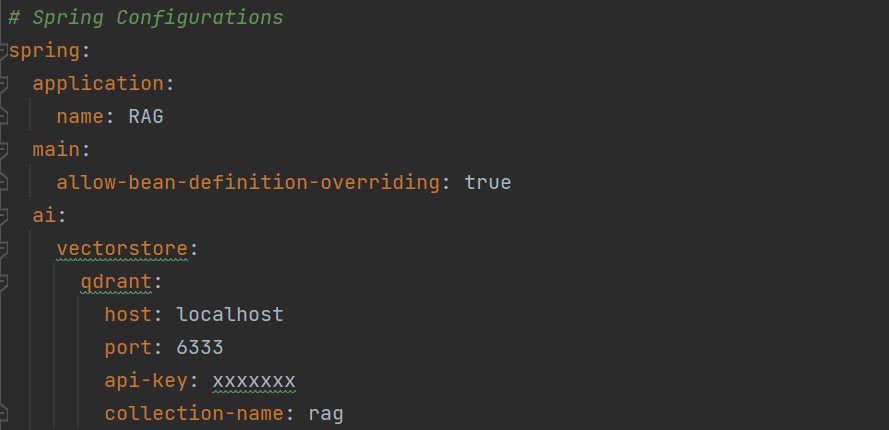
Now let's configure the application properties. Please refer to the screenshot below for setting up the vector DB (Qdrant) and OpenAI.
Vector DB configuration - Add host, port, api-key and collection name for vector DB.
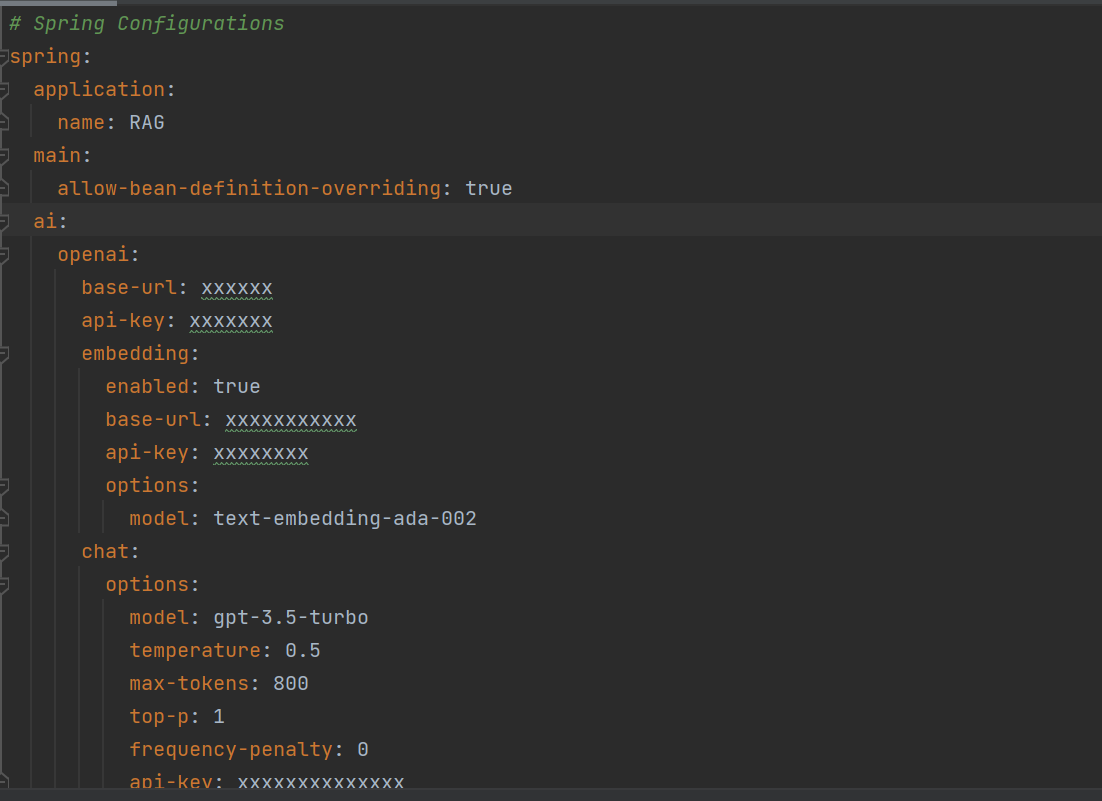
Open AI and Embedding Configuration - Configure base-url, embedding base-url, models and api-keys.
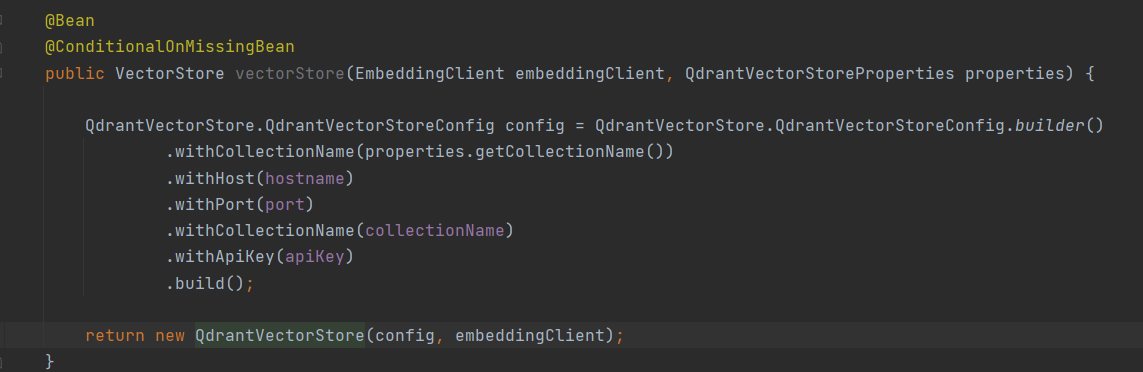
Configure vector store with embeddings model configuration refer screenshot below.
Now that the application properties are configured, we can move on to the RAG Ingestion step using the data. Please refer to the screenshot below for guidance.
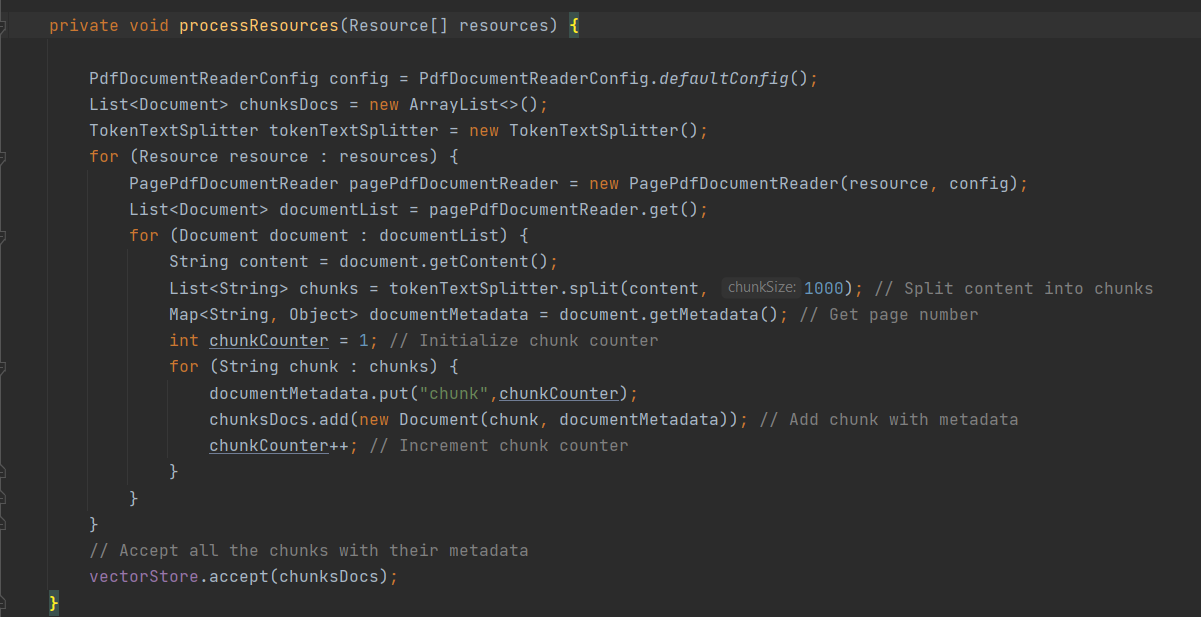
Steps performed are listed below:
Split the PDF content into segments using a text splitter.
Pass segments to an embedding model, like the Azure OpenAI embedding model.
Store embeddings in a vector store database called Qdrant.
Now that the RAG Ingestion step is completed, we can proceed to the RAG retrieval step using the data. Please refer to the screenshot below for guidance.
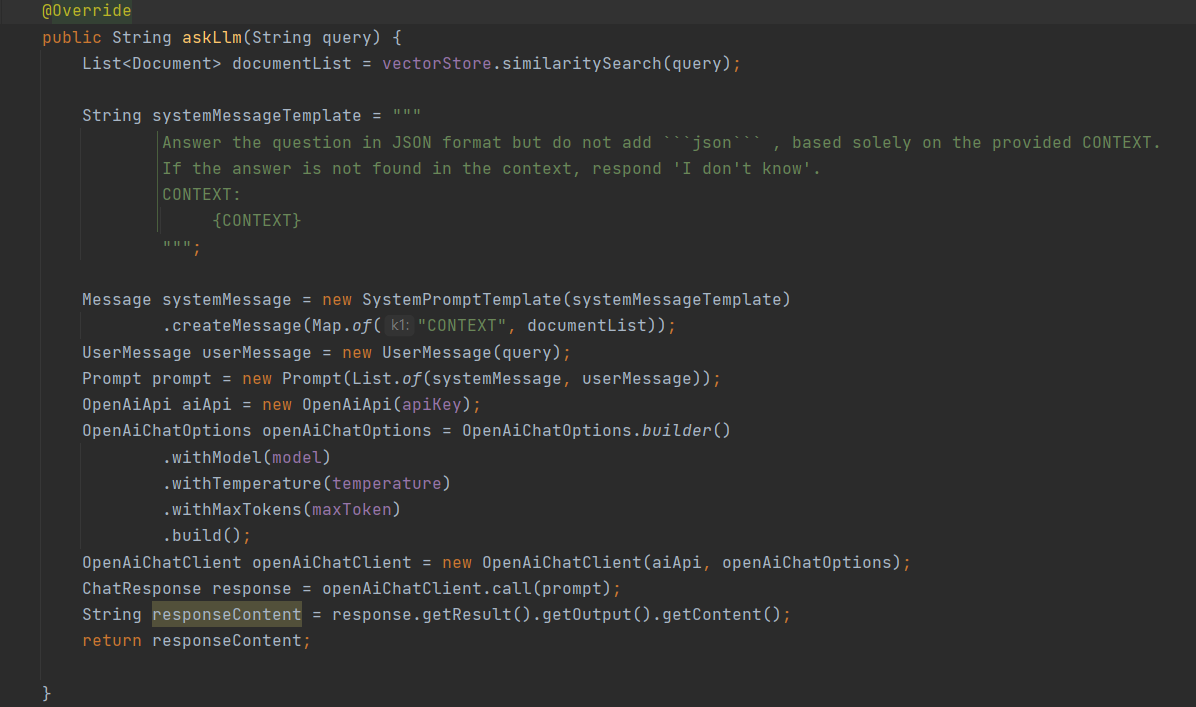
Steps performed are listed below:
User query goes through the same embedding model to create a vector.
Vector is then used to check for semantic similarity.
The segments that are semantically similar are retrieved and used to contextualize the user query.
This contextualized query is then passed to the LLM model to perform various Gen AI tasks.
Refer this GitHub repository as starting point to build RAG applications using spring AI and Qdrant.
https://github.com/vineetaparodkar/rag-with-openai-spring-ai.git
References
Subscribe to my newsletter
Read articles from Vineeta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vineeta
Vineeta
Experienced Software Engineer with 4+ years of expertise, specializing in cutting-edge technologies.