Fabric Mirroring: A Reflection of Time
 Nicolas Pappas
Nicolas PappasMirror, mirror on the wall, who is the data replicator of them all?
What is Fabric Mirroring, and why is it becoming significant in the data world now? I’d like to go through the history and talk about data mirroring and Change Data Capture being the foundation to the evolution of Fabric Mirroring.
Data mirroring, first introduced with Microsoft SQL Server 2005 Service Pack 1 (MSSQL SP1) on April 18, 2006, is a high-availability option providing data replication redundancy and failover capabilities at the database level. It was designed for business-critical applications database availability. The technology would transport the changes in the production database to a mirror database, either synchronously or asynchronously. The mirror database can reside either in the same data center to provide a high-availability solution, or in a remote data center to provide a disaster-recovery solution.
CDC (Change Data Capture) was introduced in SQL Server 2008 as a way to capture the data that is inserted, updated, or deleted for a specified table. As inserts, updates, and deletes are applied to a table (that has CDC enabled) the "Capture Process" of CDC gathers those changes from the transaction log and then adds the information to the associated change table.
Now, 18 years after the initial release of database mirroring in MSSQL SP1 and the innovation of Change Data Capture, Microsoft has released Fabric Mirroring. It takes an architectural pattern of the mirroring concept, uses CDC technology, and leverages the modern technology of Delta Lake to create Microsoft Fabric Mirroring. This replication method snapshots a database to OneLake in a Delta parquet file and keeps the replica in sync in near real-time.
Data Replicator of them all
As best practice would have it, starting off with the Fabric architecture (Figure 1: Microsoft Fabric Architecture) as a strong and reference base line.
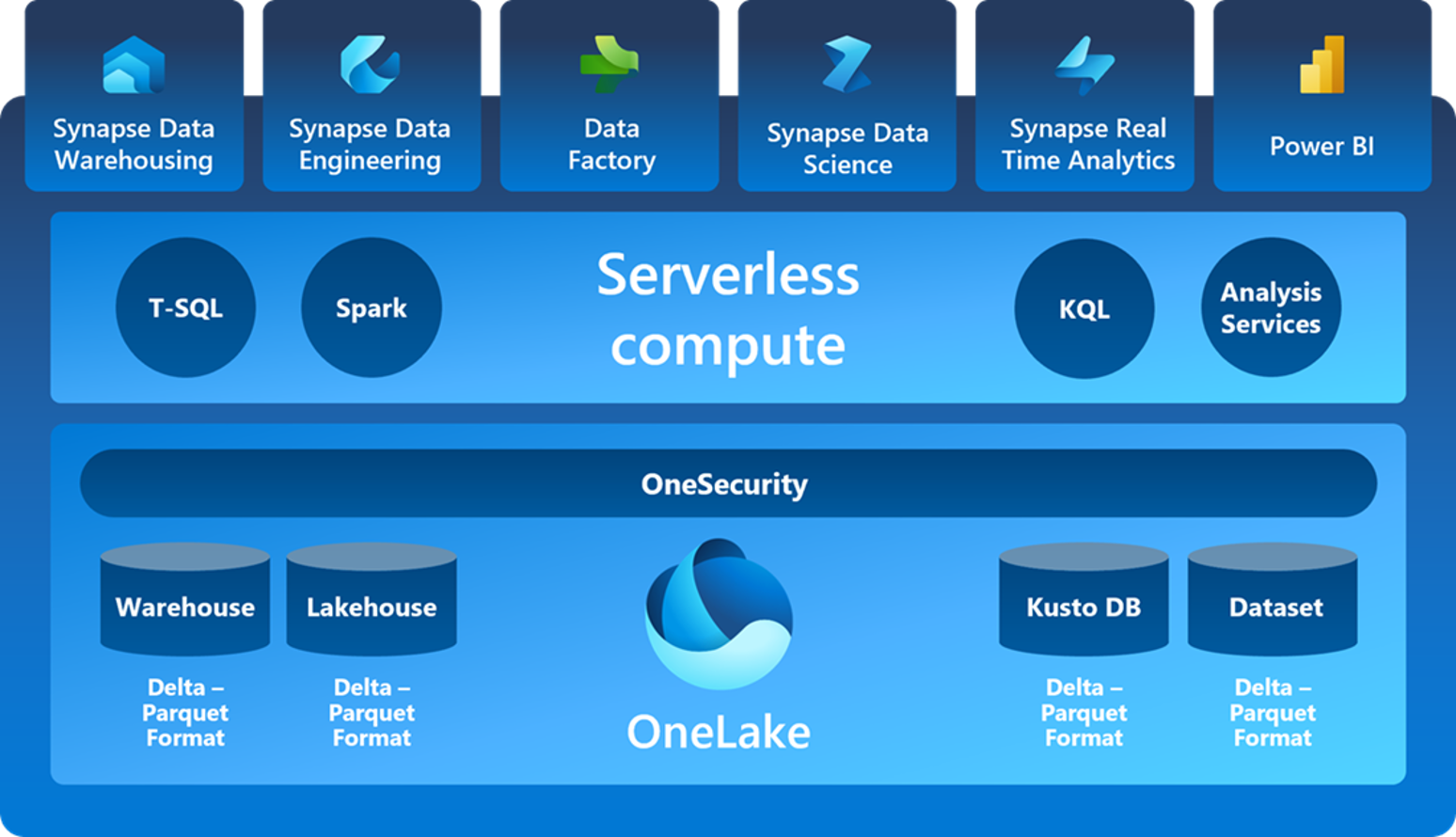
Figure 1: Microsoft Fabric Architecture
As to what makes Fabric Mirroring the replicator of them all, here is a summarize of some of the key features:
No complex ETL pipelines, near real-time replication of inserted, updated and deleted data.
No impact to transactional database (OLTP Source).
Automatic schema updates and datatype compatibility.
Mirroring in Fabric is a fully managed service by Microsoft.
Sharing = “Shared with Me” service enables you to share data within your organization.
Cross-database queries.
Bring your own language to querying data (SQL, Python or KQL).
At the moment, Fabric mirroring is free and is covered by Microsoft Fabric SKU’s.
As a use case looking at Figure 2: Fabric Mirroring (SQL Example), let’s take the example of a retail online store. When ordering online, you first register with your details which gets captured in a “Customer” table. While this information is getting written into the table it will only commit the transaction once the information is committed or submitted in this case in the online registration form. This data is then written to the Change Data Capture table because the CDC has picked up a new insert commit from the transaction log.
Fabric mirroring has its own Change Data Capture (CDC) process which has now picked up the new insert in the Change Data Capture table and can now replicate that new insert into Onelake as a Delta Parquet file. With Delta Parquet files, a new row of inserted information is added, incorporating another level of ACID transactions that encompass CDC technology. This allows for upstream analytics development and other forms of event or streaming methods.
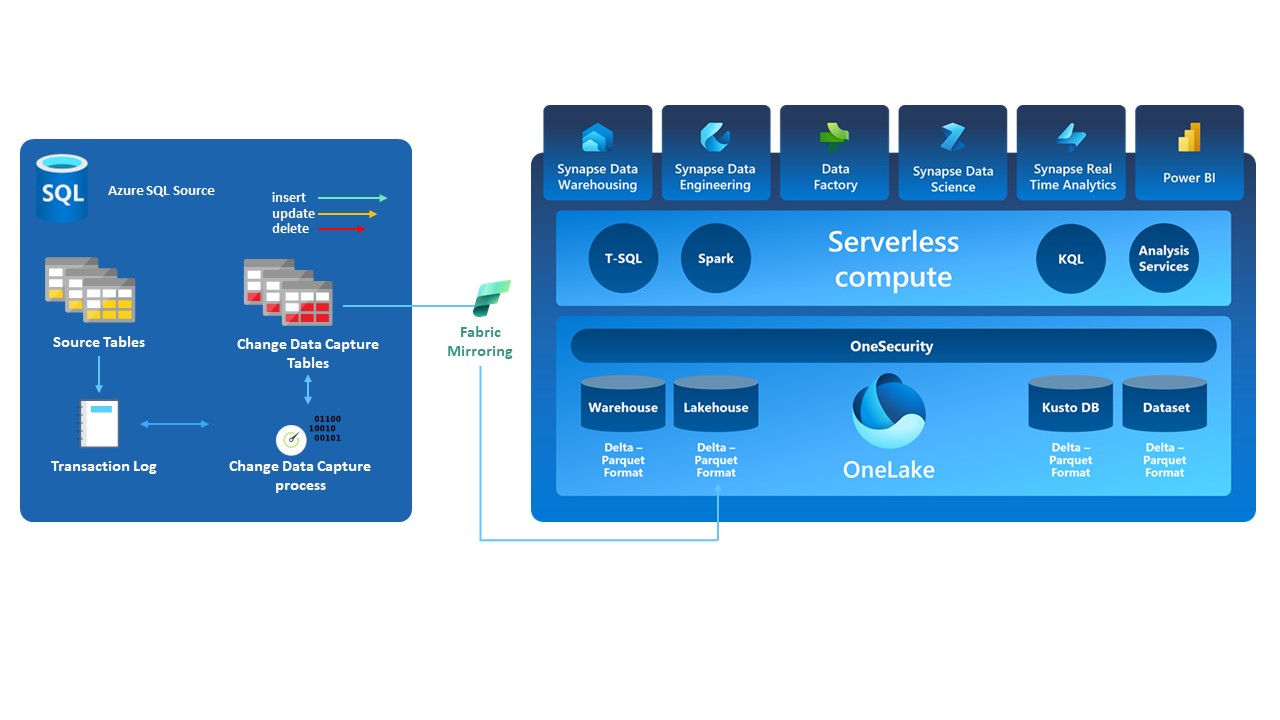
Figure 2: Fabric Mirroring (SQL Example)
Things to keep in mind.
There are some limitations that Fabric Mirroring has. Some may be resolved in future; however I believe some may not purely because the limitations are built in integrity measures that restrict issue that could be create downstream.
Azure SQL Limitations
Fabric Mirroring does not support Free, Basic or Standard tier Single Databases (S0, S1, S2) and databases in Elastic pools with max eDTU < 100 or vCore < 1.
Azure SQL Database cannot be mirrored if the database has: enabled Change Data Capture (CDC), Azure Synapse Link for SQL, or the database is already mirrored in another Fabric workspace.
Cross-Microsoft Entra tenant data mirroring is not supported where an Azure SQL Database and the Fabric workspace are in separate tenants.
For more details:https://learn.microsoft.com/en-us/fabric/database/mirrored-database/azure-sql-database-limitations
Snowflake Limitations
Any table names and column names with special characters,;{}()\= and spaces are not replicated.
If there are no updates in a source table, the replicator engine starts to back off with an exponentially increasing duration for that table, up to an hour. The same can occur if there is a transient error, preventing data refresh. The replicator engine will automatically resume regular polling after updated data is detected.
If you're changing most the data in a large table, it's more efficient to stop and restart Mirroring. Inserting or updating billions of records can take a long time.
Some schema changes are not reflected immediately. Some schema changes need a data change (insert/update/delete) before schema changes are replicated to Fabric.
For more details:https://learn.microsoft.com/en-us/fabric/database/mirrored-database/snowflake-limitations
Azure Cosmos Limitations
Mirroring is supported in a specific set of regions for Fabric and APIs for Azure Cosmos DB.
You can enable mirroring only if the Azure Cosmos DB account is configured with either 7-day or 30-day continuous backup.
If you only have viewer permissions in Fabric, you can’t preview or query data in the SQL analytics endpoint.
The Road Ahead
Right now, Microsoft Fabric Mirror is in public preview with only supporting the following databases Azure SQL, Snowflake and Azure Cosmos DB. However in the “Open Lake, Not Walled Gardens” document that Raghu Ramakrishnan (Technical Fellow, CTO for Data at Microsoft) and Josh Caplan (Head of Product for OneLake at Microsoft) publish, they aim to support on-prem SQL Server 2017 and up (On-prem and in VM’s), MySQL, PostgresQL, MongoDB, Oracle, Teradata, BigQuery and RedShift. Microsoft is also working and open to partnering up with other vendor.
All this excitement of new\old technology and how this low-cost and low latency solution is helping analytic platforms and its engineers. The real value I see in this lies in the nuances and the time spent creating infrastructure, configuring networks, and the back-and-forth of setting up everything to bring in data, which can take weeks or even months, based on my experience in the consulting world. With Mirror, the ease and flexibility of just requesting access and be up and running in a couple hours will just result in value to Analytic teams as well as the business stakeholder and the organization.
Subscribe to my newsletter
Read articles from Nicolas Pappas directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by