Hindi-Language AI Chatbot for Enterprises Using Qdrant, MLFlow, and LangChain
 M Quamer Nasim
M Quamer Nasim
In today's digital era, where businesses are increasingly leveraging technology to enhance customer interactions, AI-powered chatbots have emerged as a game-changer. These chatbots can have a natural conversation with users, providing real-time support and information. Though chatbots have become popular in the last two years, most of them are designed to interact in English.
However, in a country like India, where Hindi is spoken by millions as the first language, there is a need for chatbots that can interact in Hindi. Building a Hindi-language chatbot can help businesses cater to a wider audience and provide better customer service. In this blog, we will discuss the technical journey of building a Hindi-language AI chatbot for enterprises. By the end of this blog, you will understand the challenges associated with building a Hindi-language chatbot and how to overcome them.
Building an AI chatbot is a two-step process: Indexing and Querying. In the indexing phase, we will create a database of Hindi-language documents for the chatbot to refer to. This data is basically going to be the knowledge base of the chatbot. It can be a collection of FAQs, product manuals, or any other information that the chatbot needs to refer to while interacting with users. In the querying phase, we will use this indexed data to answer user queries with the help of an LLM.
In this blog, I will be using the following tools and frameworks for building the RAG-based AI-powered Hindi Chatbot:
LangChain: I'll be using LangChain to build the RAG application, which will enhance the chatbot's ability to generate responses by leveraging information retrieved from a knowledge base.
Qdrant: I'll be using Qdrant as the vector database to store the documents and their corresponding embeddings.
FastText: I'll be using FastText as the language embedding framework to load the Hindi language embedding model.
Ollama: Ollama will help us load the LLM very easily. We'll integrate the Ollama with LangChain to load the LLM.
MLFlow: I'll be using MLFlow to manage the configurations of the RAG pipeline.
To create a knowledge base for our chatbot, I'll be using the Hindi Aesthetic Corpus dataset. This dataset contains a large number of Hindi texts, more than 1000 text files. You can replace this dataset with your business-related data. It can be a collection of FAQs, product manuals, or any other information that you want your chatbot to have.
Great. Now that we have introduced you to all the tech stacks and data to use, let's start building one!
Indexing the Data and Creating the Knowledge Base
To start the process of indexing the data, we first need to load the dataset. As mentioned earlier, we will be using the Hindi Aesthetic Corpus dataset. Once the dataset is loaded, we will split the text into chunks using the RecursiveCharacterTextSplitter. Creating smaller chunks of text is essential since LLMs come with a limited context size.
Having a smaller and more relevant context will help us in two ways: First, we will only have high-quality and relevant context from which the LLM can learn. Second, processing a larger chunk or context means more tokens that need to be processed, which will increase the total runtime and be financially expensive.
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
data_path = '../Hindi-Aesthetics-Corpus/Corpus'
chunk_size = 500
chunk_overlap = 50
# Load the documents from the directory
loader = DirectoryLoader(data_path, loader_cls=TextLoader)
# Split the documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
is_separator_regex=False,
)
docs = loader.load_and_split(text_splitter=text_splitter)
Once we have converted the raw data into smaller chunks of text, we will then convert these chunks into embeddings using the FastText model. In this blog, we experimented with two different embedding models: the Hindi Model by FastText and IndicFT.
The performance of IndicFT was not that good, so we decided to go with the FastText model. We will use the FastText model to convert the text into embeddings. These embeddings will be stored in a vector database using Qdrant. The embeddings will be used to retrieve the most relevant documents for a given query.
import fasttext as ft
# You will need to download these models from the URL mentioned below
embedding_model_path = '../wiki.hi.bin' #https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hi.zip
# embedding_model_path = '../indicnlp.ft.hi.300.bin' #https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/embedding-v2/indicnlp.ft.hi.300.bin
embed_model = ft.load_model(embedding_model_path)
Once we have downloaded the Hindi embedding model, let's proceed to generate the embeddings for each chunk.
import pandas as pd
# convert the documents to a dataframe
# This dataframe will be used to create the embeddings
# And later will be used to update the Qdrant Vector Database
data = []
for doc in docs:
# Get the page content and metadata for each chunk
# Meta data contains chunk source or file name
row_data = {
"page_content": doc.page_content,
"metadata": doc.metadata
}
data.append(row_data)
df = pd.DataFrame(data)
# Replace the new line characters with space
df['page_content'] = df['page_content'].replace('\\n', ' ', regex=True)
# Create a unique id for each document.
# This id will be used to update the Qdrant Vector Database
df['id'] = range(1, len(df) + 1)
# Create a payload column in the dataframe
# This payload column includes the page content and metadata
# This payload will be used when LLM needs to answer a query
df['payload'] = df[['page_content', 'metadata']].to_dict(orient='records')
# Create embeddings for each chunk
# This embeddings will be used when doing a similarity search with the user query
df['embeddings'] = df['page_content'].apply(lambda x: (embed_model.get_sentence_vector(x)).tolist())
Great. Now that we have the embeddings, we need to store them in a vector database. We will be using Qdrant for this purpose. Qdrant is an open-source vector database that allows you to store and query high-dimensional vectors. The easiest way to get started with the Qdrant database is using the docker.
Follow the below steps to get the Qdrant database up and running:
# Run the following command in terminal to get the docker image of the qdrant
docker pull qdrant/qdrant
# Run the following command in terminal to start the qdrant server
docker run -p 6333:6333 -v Hindi-Language-AI-Chatbot-for-Enterprises-using-Qdrant-MLFlow-and-LangChain/:/qdrant/storage qdrant/qdrant
Now, let's open a connection to the Qdrant database using the qdrant_client. We then need to create a new collection in the Qdrant database in which we will store the embeddings. Once this is done, we will insert the embeddings, along with the corresponding document IDs and payloads, into the collection. The document IDs will be used to identify the documents; the payloads will contain the actual text of the document, and the embeddings will be used to retrieve the most relevant documents for a given query.
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, Batch
# Create a QdrantClient object
host = 'localhost'
port = 6333
client = QdrantClient(host=host, port=port)
# delete the collection if it already exists
client.delete_collection(collection_name="my_collection")
# Create a fresh collection in Qdrant
client.recreate_collection(
collection_name="my_collection",
vectors_config=VectorParams(size=300, distance=Distance.COSINE),
)
# Update the Qdrant Vector Database with the embeddings
# We are updating the embeddings in batches
# Since the data is large, we will only update the first batch of size 4000
batch_size = 4000
client.upsert(
collection_name="my_collection",
points=Batch(
ids=df['id'].to_list()[:batch_size],
payloads=df['payload'][:batch_size],
vectors=df['embeddings'].to_list()[:batch_size],
),
)
# Close the QdrantClient
client.close()
After saving the embeddings in the Qdrant database, we can view the collection in the Qdrant dashboard. We can see from the dashboard that each chunk has 3 pieces of information: metadata, chunk text, and embeddings.
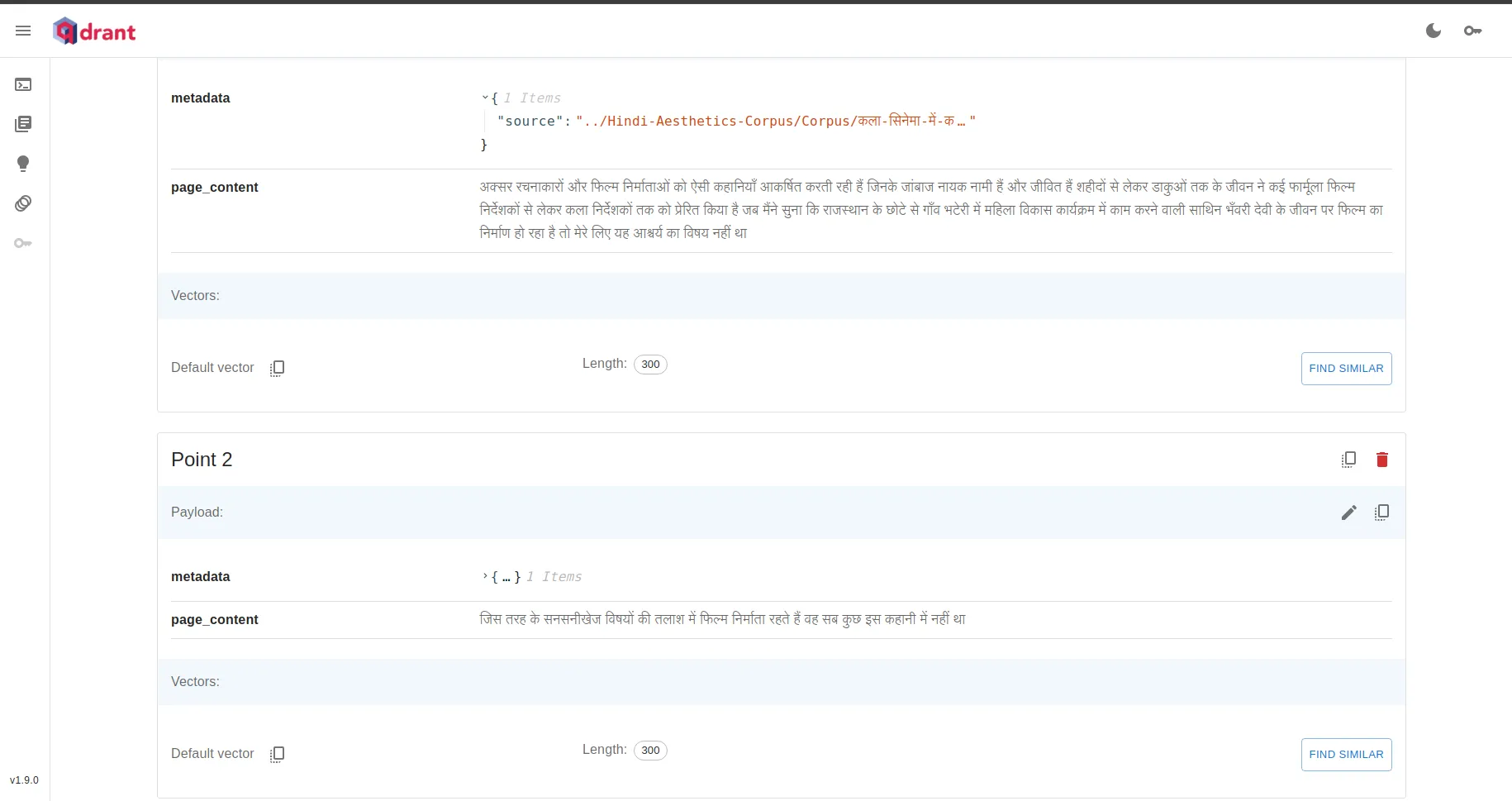
Great. We have completed the first part of building our Hindi Chatbot. Let’s now move on to the next part, querying.
Querying the LLM
Now, let's start building the next part of the chatbot. In this part, we will be using the LLM from Ollama and integrating it with the chatbot. More particularly, we will be using the Llama-3 model. Llama-3 is Meta's latest and most advanced open-source large language model (LLM). It is the successor to the previous Llama 2 model and represents a significant improvement in performance across a variety of benchmarks and tasks. Llama 3 comes in two main versions - an 8 billion parameter model and a 70 billion parameter model. Llama 3 supports longer context lengths of up to 8,000 tokens.
We will be using MLFlow to track all the configurations and the model results. Let's first install Ollama and get the Llama 3 model from Ollama and MLFlow.
# install the Ollama
curl -fsSL https://ollama.com/install.sh | sh
# get the llama3 model
ollama pull llama2
# install the MLFlow
pip install mlflow
Now, let's start by loading the Qdrant Client, which will be used to retrieve the context for a given query. We will also start logging the configurations and the results of the workflows using MLFlow.
import mlflow
from qdrant_client import QdrantClient
mlflow_lgging = True
if mlflow_lgging:
# set the experiment name in the mlflow
mlflow.set_experiment("Hindi Chatbot")
# start the mlflow run
mlflow.start_run()
# load the Qdrant client from the same host and port
# this client will be used to interact with the Qdrant server
host = "localhost"
port = 6333
client = QdrantClient(host=host, port=port)
# log the parameters in the mlflow
if mlflow_lgging:
mlflow.log_param("qdrant_host", host)
mlflow.log_param("qdrant_port", port)
We also need to load the embedding model. This embedding model is necessary to convert the query to the embedding that can be used to do a similarity search in Qdrant. The ultimate goal is to retrieve the context for a given query based on the similarity of the query embedding with the context embeddings.
import fasttext as ft
# You will need to download these models from the URL mentioned below
embedding_model_path = '../wiki.hi.bin' #https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.hi.zip
# embedding_model_path = '../indicnlp.ft.hi.300.bin' #https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/embedding-v2/indicnlp.ft.hi.300.bin
embed_model = ft.load_model(embed_model_path)
if mlflow_lgging:
mlflow.log_param("embed_model_path", embed_model_path)
LangChain, by default, does not support the FastText embedding framework. It only supports Hugging Face and OpenAI models. So, that is why we need to define the custom LangChain retriever class that will be used to retrieve the context for a given query. In this class, we will have one method getrelevant_documents, which will do the similarity search in Qdrant based on the FastText embedding model and return the context for a given query.
from typing import List
from qdrant_client import QdrantClient
import fasttext as ft
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
# Define a custom retriever class that uses Qdrant for document retrieval
# Since we're using FastText embeddings, we won't be able to use the default lanchain retriever, as it only supports HuggingFace and OpenAI Models
class QdrantRetriever(BaseRetriever):
client: QdrantClient
embed_model: ft.FastText._FastText
collection_name: str
limit: int
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
"""Converts query to a vector and retrieves relevant documents using Qdrant."""
# Get the vector representation of the query using the FastText model
query_vector = self.embed_model.get_sentence_vector(query).tolist()
# Search for the most similar documents in the Qdrant collection
# The search method returns a list of hits, where each hit contains the most similar document
# we can limit the number of hits to return using the limit parameter
search_results = self.client.search(
collection_name=self.collection_name,
query_vector=query_vector,
limit=self.limit
)
# Finally, we convert the search results to a list of Document objects
# that can be used by the pipeline
return [Document(page_content=hit.payload['page_content']) for hit in search_results]
# use the Custom QdrantRetriever class to create a retriever object
retriever = QdrantRetriever(
client=client,
embed_model=embed_model,
collection_name=collection_name,
limit=limit
)
if mlflow_lgging:
mlflow.log_param("collection_name", collection_name)
mlflow.log_param("limit", limit)
Now, we need to load the Llama 3 model. We will be using the 8 billion parameter model. Instead of using Hugging Face to load the model, we will use Ollama to load it. Ollama provides a simple and easy way to load the models without much of a hassle. The class Ollama takes in a number of arguments, the most important of which are num_predict (number of tokens to be generated) and num_ctx (maximum context size).
from langchain_community.llms.ollama import Ollama
# Create an Ollama object with the specified parameters
# This will very easily load the llama3 8-B model without the need of separately handling tokenizer like we do in huggingface
llm=Ollama(model='llama3', num_predict=100, num_ctx=3000, num_gpu=2, temperature=0.7, top_k=50, top_p=0.95)
if mlflow_lgging:
mlflow.log_param("model_name", model_name)
mlflow.log_param("num_predict", num_predict)
mlflow.log_param("num_ctx", num_ctx)
mlflow.log_param("num_gpu", num_gpu)
mlflow.log_param("temperature", temperature)
mlflow.log_param("top_k", top_k)
mlflow.log_param("top_p", top_p)
Great. So far, we have been able to set up the retriever, which will retrieve the context from the database based on the similarity of the query embedding with the context embeddings. We have also loaded the Llama 3 model.
Now, there's just one more thing left to do. We need to create a chat template. The chat template includes two types of prompts. The first one is system prompts, and the other one is user prompts. System prompts are the prompts that are written to control the behavior of the chatbot or LLMs. It is very important to have a good system prompts to get responses as per expectations. A bad system prompt can lead to poor or incorrect behavior of your chatbot. I spent some time optimizing the system prompts to get the best results. User prompts are the prompts that are written to get the responses from the chatbot. These prompts are the questions or queries that the user wants to ask the chatbot. Just like a good system prompt, it is always recommended to have a good user prompt. It should be concise, informative, and to the point.
Next, we will create these chat templates based on these two prompts.
from langchain_core.prompts import ChatPromptTemplate
system_prompt = (
"""<s>[INST] आप एक सम्मानीय सहायक हैं। आपका काम नीचे दिए गए संदर्भ से प्रश्नों का उत्तर देना है। आप केवल हिंदी भाषा में उत्तर दे सकते हैं। धन्यवाद।
You are never ever going to generate responses in English. You are always going to generate responses in Hindi no matter what. You also need to keep your answer short and to the point.
संदर्भ: {context} </s>
"""
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
if mlflow_lgging:
mlflow.log_param("system_prompt", system_prompt)
Now, let's tie up everything and create a chain of actions. We first want to retrieve the relevant documents based on the prompt. We then want to generate the response based on the context and the prompt. create_stuff_documents_chain and create_retrieval_chain is exactly what we need to do this.
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# Create a chain that combines the retriever and the question-answer chain
# essentially, this chain will retrieve relevant documents using the retriever
# and the prompts
question_answer_chain = create_stuff_documents_chain(llm, prompt)
chain = create_retrieval_chain(retriever, question_answer_chain)
Finally, we have successfully built the chatbot using the Llama 3 model. Let's now test the chatbot and see how it performs.
query = 'किस तरह के किरदार और कहानी तत्व रचनाकारों और फिल्म निर्माताओं को आकर्षित करते हैं?'
if mlflow_lgging:
mlflow.log_param("query", query)
response = chain.invoke({"input": query})
if mlflow_lgging:
mlflow.log_param("context", response['context'])
mlflow.log_param("response", response['answer'])
print(response)
# end the logging of the mlflow
mlflow.end_run()
Let’s see how our chatbot responded to the query.
{'input': 'किस तरह के किरदार और कहानी तत्व रचनाकारों और फिल्म निर्माताओं को आकर्षित करते हैं?',
'context': [Document(page_content='अक्सर रचनाकारों और फिल्म निर्माताओं को ऐसी कहानियाँ आकर्षित करती रही हैं जिनके जांबाज नायक नामी हैं और जीवित हैं शहीदों से लेकर डाकुओं तक के जीवन ने कई फार्मूला फिल्म निर्देशकों से लेकर कला निर्देशकों तक को प्रेरित किया है जब मैंने सुना कि राजस्थान के छोटे से गाँव भटेरी में महिला विकास कार्यक्रम में काम करने वाली साथिन भँवरी देवी के जीवन पर फिल्म का निर्माण हो रहा है तो मेरे लिए यह आश्चर्य का विषय नहीं था')],
'answer': 'सामान्य तौर पर, रचनाकारों और फिल्म निर्माताओं को ऐसे किरदार और कहानी तत्व आकर्षित करते हैं जिनके साथ सम्बंधित लोग हों, या जिनके साथ उनका अपना अनुभव हो। इसके अलावा, रचनाकारों और फिल्म निर्माताओं को ऐसे किरदार'}
Great, we can see that our chatbot was able to retrieve the right chunk from the database and answer the question correctly.
We have also been logging the chatbot parameters in MLFlow. Let's now check that out and see how it looks. In order to view the content of MLFlow, we’ll need to launch the dashboard of MLFlow using the following command.
# launches the MLFlow dashboard
mlflow ui --port 5000
This is what the dashboard of MLFlow looks like. We can see what our Hindi Chatbot project is showing.
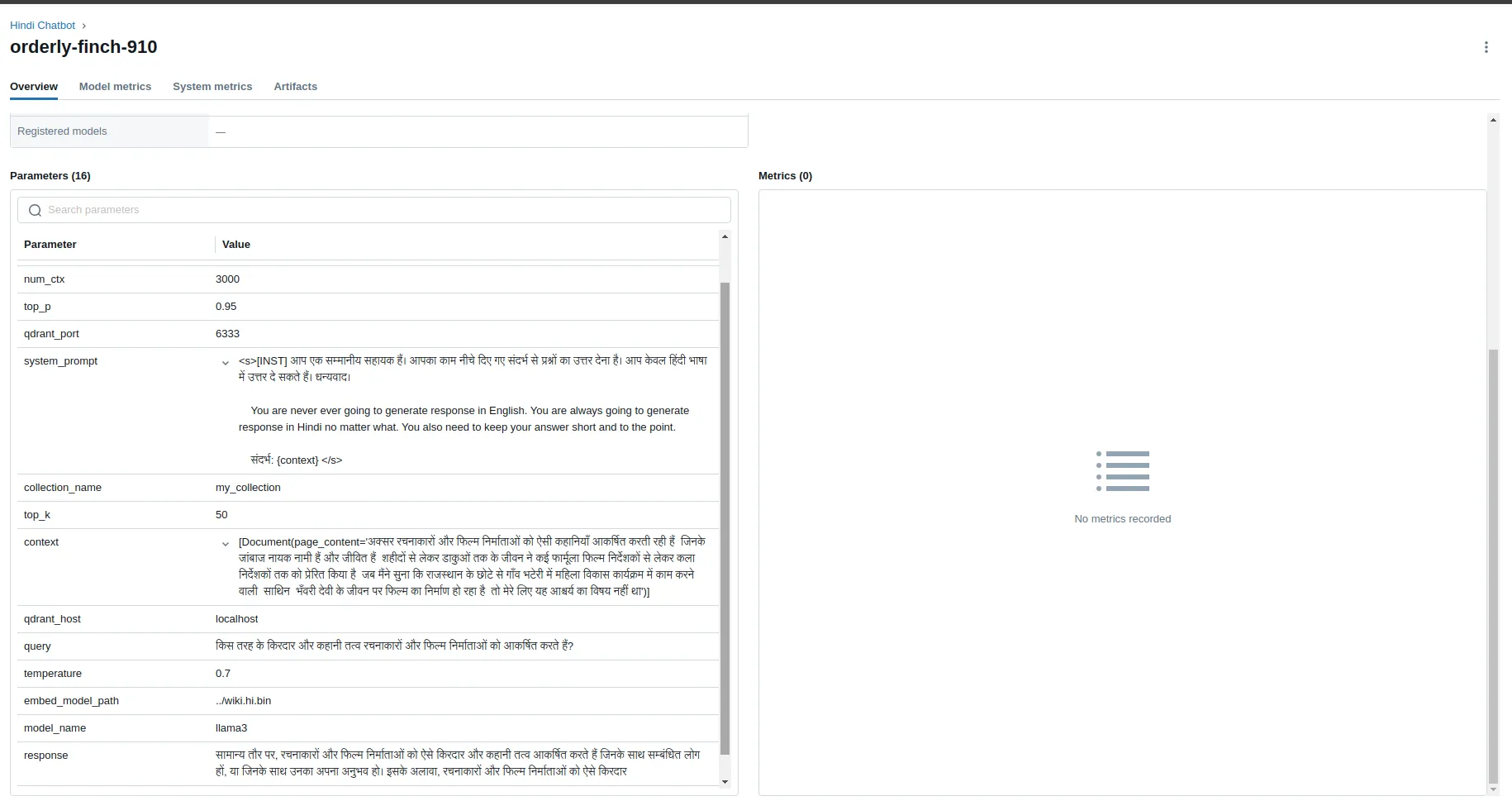
We can also see that all the parameters – query, context, and response – have been saved in MLFlow.
Great. In this blog, we saw how we can use LangChain, Ollama, Qdrant, MLFlow, and Llama 3 model to build a Hindi-language chatbot. We also saw how to track the parameters and the results of the chatbot using MLFlow. As a bonus, let's also build a Gradio UI for the chatbot.
import gradio as gr
def answer_question(query, history):
response = chain.invoke({"input": query})
return response['answer']
gr.ChatInterface(answer_question).launch(share=True)
That's it for this blog. I hope you enjoyed reading it.
You can find the code related to this blog at the below-mentioned GitHub link: https://github.com/quamernasim/Hindi-Language-AI-Chatbot-for-Enterprises-using-Qdrant-MLFlow-and-LangChain
References
https://blog.stackademic.com/hindi-language-rag-pipeline-with-mistral-and-qdrant-d2bcf162b6e5
https://medium.com/@kmkaran212/word-embeddings-for-indian-languages-d69ed933aecd
This article was originally published on: https://quamernasim.medium.com/hindi-language-ai-chatbot-for-enterprises-using-llama-3-qdrant-ollama-langchain-and-mlflow-9b69391d3348
Subscribe to my newsletter
Read articles from M Quamer Nasim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
M Quamer Nasim
M Quamer Nasim
👋 Hello! I'm M Quamer Nasim, a passionate Data Scientist with over 3.5 years of experience in the field. 🔍 Specializing in Computer Vision and LLMs, I thrive on transforming complex data into actionable insights. My expertise extends to building RAG-Powered applications that drive innovation and efficiency. 🤝 Collaborative by nature, I enjoy working in cross-functional teams to deliver impactful solutions that meet business objectives and exceed expectations. 📈 Continuous learning is a cornerstone of my professional journey, and I am always eager to explore new technologies and methodologies to stay ahead in this ever-evolving field. 🔗 Let's connect! I'm always open to networking with like-minded professionals and exploring opportunities for collaboration.