Power of Reconciliation
 Priti Biyani
Priti BiyaniTable of contents

I consider myself lucky to have been part of a team tasked with rewriting the wealth management backend. This opportunity allowed me to witness firsthand the transformation of a legacy system that had served users for decades.
The system we were rewriting was a wealth management banking application handling portfolios and processing a large volume of transactions. The scale of operations was significant. Ensuring 100% correctness in financial data was crucial during the rewrite process.
Our team lead possessed excellent technical vision. Despite making quick decisions, each one was thoroughly analysed, considering our future roadmap, ultimate goals, and accepting certain obstacles that we cannot do anything about.
Why replace existing system
The decision to replace our legacy system resulted from a multitude of factors:
Lack of data immutability making it challenging to trace transaction histories and understand the reasoning behind applied rules.
Prohibitive licensing costs associated with the proprietary application.
Lengthy customisation timelines
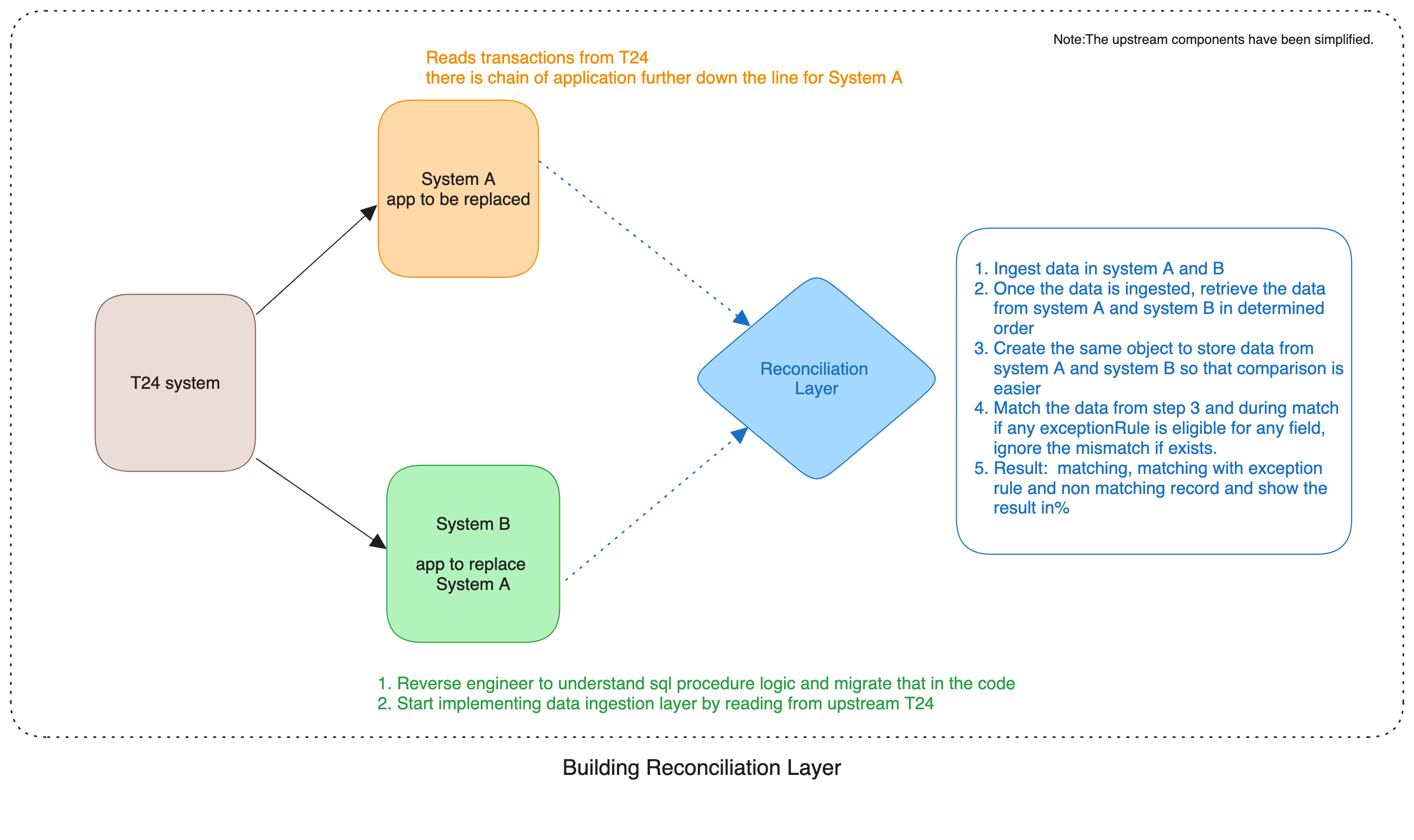
We started with small steps:
Build data ingestion layer for system B
Understanding the underlying logic was difficult, especially considering that much of the code was written in SQL procedures, a technology I had encountered back in my college days but was now seeing in action for the first time.
The rules in SQL procedure were far from simple, often relying on cryptic strings without clear explanations for their usage. Thankfully, we had SQL experts and domain specialists on our team whom we could rely on for clarification.
We started creating the data ingestion layer slowly by understanding these procedures, adding tests around those as we added any rule in system B. Adding this was error-prone, given three probabilities:
Our understanding of existing logic might go wrong, and there's no quick way to validate it due to the lack of tests for SQL procedures.
The existing logic might reside in some other layer and not entirely in SQL procedures. (Note: diagram is simplified and we were sort of replacing 2 layers)
We might miss adding edge test cases or combinations of tests, thus potentially escaping detection during unit tests.
This lead to birth of reconciliation layer, and that's step 2.
Reconciliation layer
As unit tests might not catch all the bugs, we required a layer to verify if the data remains consistent after ingestion into both system A and system B – and that's precisely what we implemented!
Initially, building the reconciliation layer seemed straightforward: retrieve instruments from both system A and system B and match them. However, we encountered several challenges.
During the development of system A, numerous rules were established that are no longer applicable in today's context or are handled by other systems. Consequently, we had to incorporate an exception layer – hence the introduction of the ExceptionRule. If a specific rule is valid during matching, we ignore any mismatches for that field and label the record as "match_with_exception," along with the name of the exception rule. This helped us with a detailed reconciliation report.
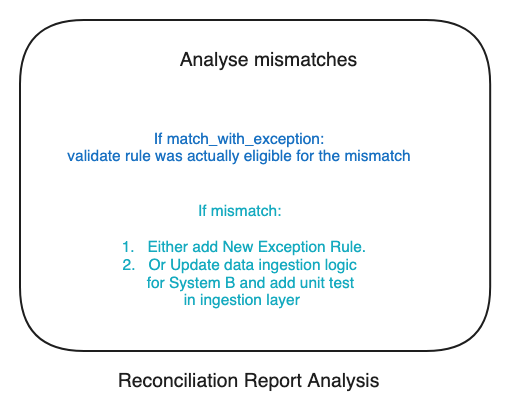
We stored the artifact output as a CSV file for ease of analyzing mismatches. The analysis results were then fed back into the DSL in the form of ExceptionRule, or we updated the code and corresponding ingestion logic accordingly.
Reconciliation DSL
Little bit about code journey and how it evolved. I joined the team when the reconciliation layer was under construction, and the matching of instruments and portfolios was already underway.
We began with a straightforward reconciliation system, achieving an impressive near 99% match rate with our initial efforts. However, as we progressed to matching transactions and instruments, we encountered challenges that lead to the introduction of the ExceptionRule.
Recognizing recurring patterns in our code, our lead guided us in developing a Domain-Specific Language (DSL) to streamline repetitive tasks. This proved invaluable, particularly for reconciling next entities. It saved lot of time and all we had to do was to read from upstream, transform to common structure and add known Exception Rule.
Incorporating the ExceptionRule into the DSL, we structured our code to handle field-level rules, multiple field rules, and entity-specific rules. This enhanced our ability to generate detailed reports as we debugged mismatches and iteratively refined our approach.
Performance issues surfaced when we started to run reconciliation on large data sets. To address this, we transitioned to a chunking approach, caching specific data to optimize rule execution, especially for those requiring cross-entity information.
The final phase involved scheduling daily reconciliation that runs against a clean environment.
If the match rate was below 99%, we analyzed the mismatches. The outcome of the analysis typically involved either adding more ExceptionRules or updating the transformation logic in the data ingestion layer, along with appropriate tests.Once we achieved a 99% match rate, we continued to monitor progress as part of our standup activities, ensuring ongoing accuracy and reliability.
Take away
Building a robust reconciliation layer provided invaluable feedback on our ingestion layer, ultimately accelerating our progress in the long run. Rather than constructing it all at once, we iteratively refined it as needed, tailoring it to our specific requirements, particularly with regards to the ExceptionRule and ReportBuilding functionalities.
Adopting a DSL-based development approach significantly enhanced the structure and clarity of our codebase, making it easier to update.
💡In legacy systems which need to be replaced, where existing code lacks testing and the prospect of retroactively adding tests seems daunting, using this approach can serve as a pragmatic solution for automated faster feedback cycle, leads to the development of an error-free rewrite.
Subscribe to my newsletter
Read articles from Priti Biyani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Priti Biyani
Priti Biyani
Ten-year ThoughtWorks veteran, based in Singapore. Skilled in full-stack development and infrastructure setup, now focusing on backend work. Passionate about TDD, clean code, refactoring, DDD and seamless deployment. I thrive on the entire software delivery spectrum, relishing the journey from conceptualisation to deployment Enjoys painting and dancing outside of work.