Machine Learning : Random Forest Classification (Part 16)
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulIt's also referred to as Ensemble learning (using multiple ml algorithm to predict something)

Steps:

It's basically a cluster of a lot of decision tree classification. Takes what majority of the decision tree predicts.
Let's code it down:
Problem statement: We are launching a new SUV in the market and we want to know which age people will buy it. Here is a list of people with their age and salary. Also, we have previous data of either they did buy any SUV before or not.
Let's import libraries , dataset and split
Feature Scaling
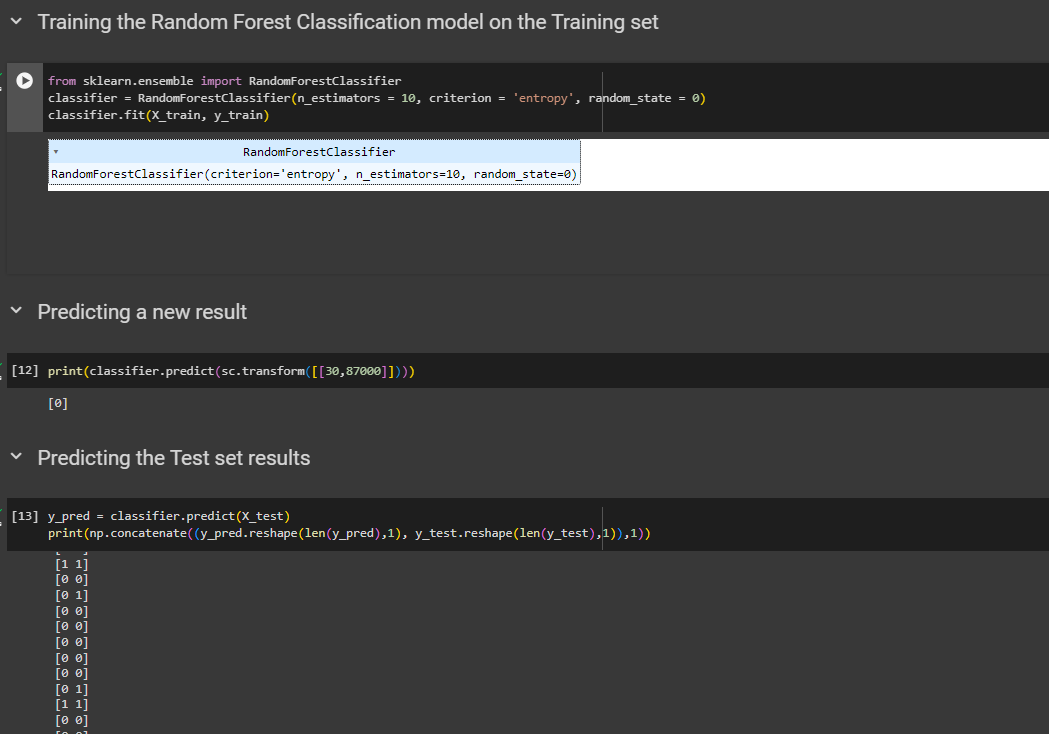
Training the Random Forest Classification model on the Training set
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) #we are taking 10 trees
classifier.fit(X_train, y_train)
Predicting a new result
print(classifier.predict(sc.transform([[30,87000]])))
Predicting the Test set results
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
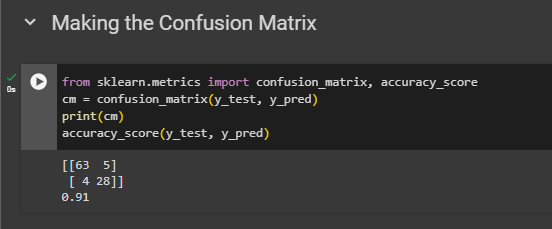
Making the Confusion Matrix
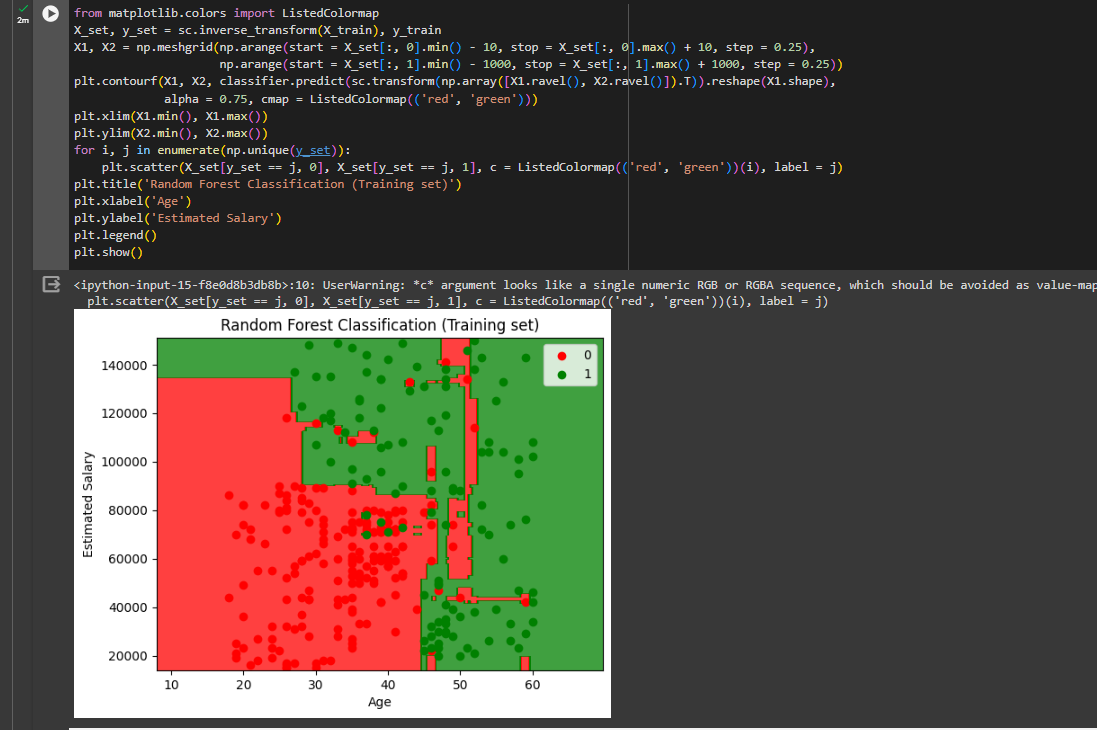
Visualizing the Training set results
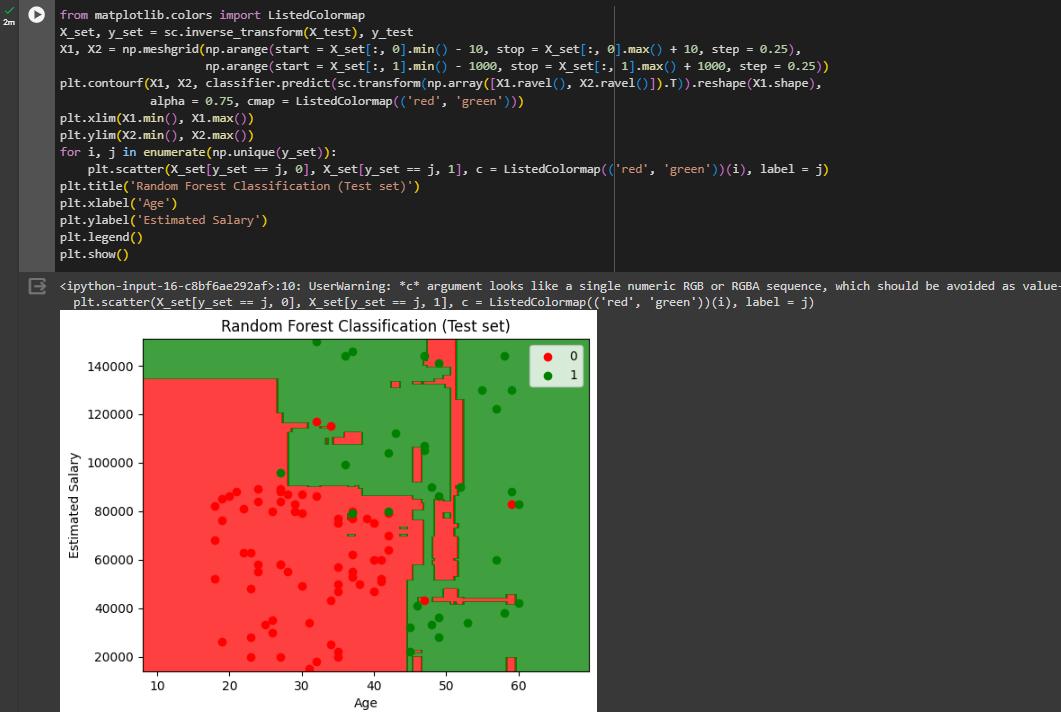
Visualizing the Test set results
The code and dataset
Done!
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by