Making Systems Reliable Part 1: Resiliency
 Ayman Patel
Ayman PatelTable of contents

Reality of Software Systems
Most systems, for better or worse will have services integrations. Be it internal or external; there will be some sort of service that you cannot control and cannot know its characteristics like peak load capacity, bandwidth limits, uncaught exception etc. By laws of probability, you will definitely face a downtime. Either it is you that will go down, or something that you rely on. At this moment, graceful degradation is the name of the game. You have to put in place a strategy to handle these scenarios.
There are 4 key methodologies for making systems reliable
Resiliency Engineering as part of architecture or business logic.
Load testing for real world peak loads
Chaos Engineering for simulation
Observing the universe that you own
This blog is part 1 of making systems reliable & predictable. It will go into the concept of resiliency and go into topics such reason for resiliency, architectural design patterns, small scale code-level implementation using Spring(Java) and finally on leveraging proxies to enforce resiliency.
Fallacies of Distributed Systems
Whenever you work with Microservices, you have isolated failures. It is not the question of if your service will fail, but when.
There are the 8 fallacies of Distributed Computing that are usually assumed to be true, either advertently or inadvertently. These were coined by Peter Deutsh and other folks at Sun microsystems.
The fallacies are:
| Fallacy | Examples |
| The network is reliable | Router, Database, Downstream/Upstream APIs can go down. Fiber optic cable is cut. |
| Latency is zero | Speed of light is non-zero and there are many hops at network level. |
| Bandwidth is infinite | JSON consumes non-zero bytes. Binary protocols like protobuf can optimize this. |
| The network is secure | Every router, client, server is a security attack vector due to plethora of different OS, CPU ISAs and libraries used. |
| Topology doesn't change | Topology always changes. Could be for server rack upgrades, disaster recovery exercises, firewall rules changes etc. |
| There is one administrator | Admins for Firewall, Reverse proxy/load balancer, CDN admins, Database administrators, different application owners. |
| Transport cost is zero | There are some non-zero costs of transport such as cost of marshalling from Layer 7 of OSI stack (Application layer) to Layer 4 (Transport Layer) or infrastructure costs such as running the data center. |
| Network is homogeneous | Different Operating Systems, instruction-set architectures (x86, ARM, RISC etc). |
Murphy's Law
"Anything that can go wrong will go wrong."

So Murphy's law is quite a generic saying which is quite real in modern software systems. Whatever your opinion is if Murphy law is a cop-out or based out of bad luck, the fact of the matter is that if you add more nodes, then it is statistically probable to fail. Period.
So having the mindset of reliable software is key for you application to be healthy and not have cascading degradation when things go out of control.
Anti-fragility
If Murphy's law was a gloom mindset, Nassim Taleb's Anti-fragility might be the right balance. For the uninitiated, Nassim Taleb came with the concept of Anti-fragility which comes something like this:
"Antifragility is a property of systems in which they increase in capability to thrive as a result of stressors, shocks, volatility, noise, mistakes, faults, attacks, or failures."

If you think about what to do when something does go wrong (which it will), you might be able to find good architectural patterns to make your system more resilient. Just like a rubber band is loose in its natural form and when you stretch it and it is able to withstand it. Resilient systems can also similarly can operate effectively when stretched by switching to redundant backend system, allocating higher resources, making smart decisions in case of failures. This mindset is what SREs strive for!
Architectural Patterns
Implementation is done in Java using Resilience4j Library
Implementation libraries
Resilience4J is the evolution of the Hystrix library by Netflix.
Hystrix was created in 2011 to build resilient systems at Netflix who were creating Microservices. Hystrix took latency spikes and faults into consideration. Its main principles were:
Fail fast and Recover Rapidly
Prevent cascading failures
Degrade gracefully
Add Observability (monitoring and alerting of services)
You can read more on how it works here
Resilience4J was inspired by Hystrix and provided a functional interface for configuration. This allowed for extending different fault tolerant methods such as Retries, Rate Limiter, Bulkhead to the Circuit Breaker interface(function decorator).
Note that Resilience4J requires Java 17.
Resilience4J has packages available in Spring Boot 2&3, Spring Cloud, Micronaut, RxJava
In order to get started with Resilience4J in Spring Boot, you need to import the Resilience4J library:
Importing Resilience4J library in Gradle (Kotlin):
// Other config
val resilience4jVersion = "2.0.2" // if you are using 1.7.x, use 1.7.0 and later versions might have some issues wrt version locking
repositories {
jCenter()
}
dependencies {
compile "io.github.resilience4j:resilience4j-spring-boot2:${resilience4jVersion}"
compile('org.springframework.boot:spring-boot-starter-actuator')
compile('org.springframework.boot:spring-boot-starter-aop')
}
The configurations can be done via YAML configurations as well custom Beans in Spring.
YAML Configuration:
resilience4j.<architecural_pattern>: # circuitbreaker, retry, ratelimiter, bulkhead
configs:
default:
# Default configurations applied to all services
someShared:
# Configuration for sharing subset configs.
instances:
backendA: # Configuration for backendA only
baseConfig: default
# banckendA config
backendB:
baseConfig: someShared
Every method (retry, circuit breaker) provides a registry which can be extended to configure the properties in @Bean annotation
Pattern 1: Retry
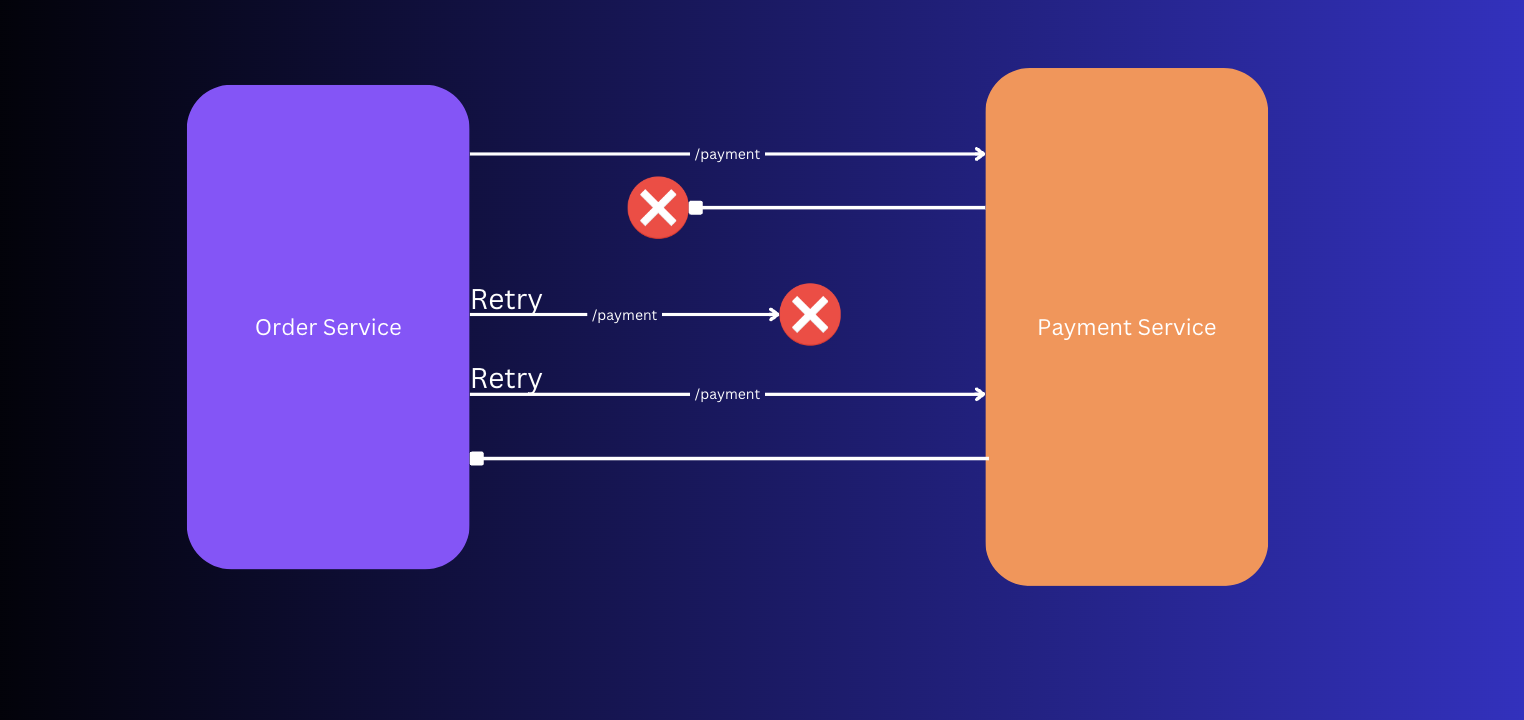
This pattern is useful for transient failures. In other words, the failures that are intermittent and can be fixed by simply retrying.
You can configure application properties for retry like this:
resilience4j.retry:
instances:
backendA:
maxAttempts: 3
waitDuration: 10s
enableExponentialBackoff: true
exponentialBackoffMultiplier: 2
retryOnResultPredicate: com.acme.myapp.Config.RetryResultPredicate
retryExceptionPredicate: com.acme.myapp.Config.RetryExceptionPredicate
retryExceptions:
- org.springframework.web.client.HttpServerErrorException
- java.io.IOException
ignoreExceptions:
- io.github.robwin.exception.BusinessException
And for Java Bean config
RetryConfig config = RetryConfig<HttpResponse>.custom()
.maxAttempts(2)
.waitDuration(Duration.ofMillis(100))
.retryOnResult(response -> response.getStatus() == 500)
.retryOnException(e -> e instanceof WebServiceException)
.retryExceptions(IOException.class, TimeoutException.class)
.ignoreExceptions(BusinessException.class, OtherBusinessException.class)
.build();
// Create a RetryRegistry with a custom global configuration
RetryRegistry registry = RetryRegistry.of(config);
To configure the method you want to retry can be configured for Retry like this:
@GetMapping("/paymentService")
@Retry(name = "paymentService", fallbackMethod = "fallbackPaymentAfterRetry")
@Sl4j
public String paymentApi() {
log.info("calling payment");
return paymentService.doPayment();
}
public String fallbackPaymentAfterRetry(Exception ex) { return ResponseEntity<>(HttpStatus.INTERNAL_SERVER_ERROR) }
Here, the payment service will be called 3 times if the call is never returned due to some transient issue such as payment service is down, network issues etc.
Pattern 2: Circuit Breaker
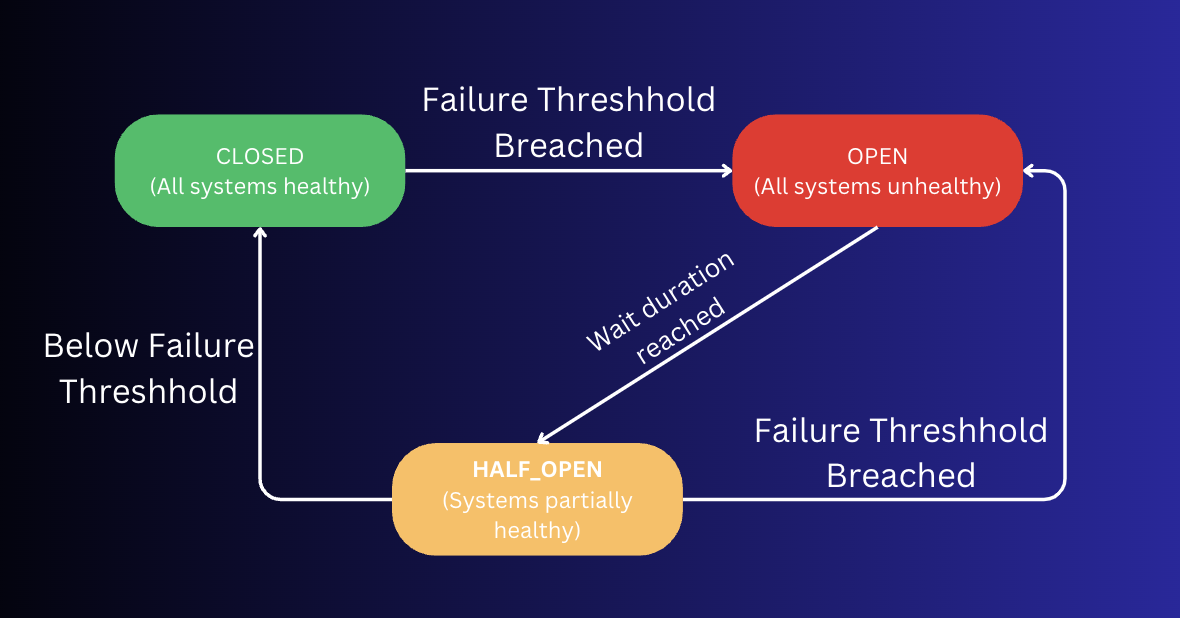
Similar to a circuit breaker, you find at home. When the current gets too high, the circuit is snapped/tripped and the circuit is open in order to break the circuit. The difference when compared to Software servers when compared to electricity circuit breakers relies on how switch is fixed. In electricity, the circuit breaker is fixed by manually resetting the switch after fixing the root cause, whilst in servers, there are heuristics to determine the health of downstream system. These heuristics might be time-based (like checking health of system every 5 seconds) or count-based (retrying it 5 times). When these heuristics confirm that downstream is health, the switch is turned back on, and the application is deemed healthy as a whole.
There are 3 States in the Circuit breaker pattern
OPEN: Circuit is open and system is unhealthyHALF_OPEN: Some time or count has reached to check the system health again. If it is good, then move toCLOSED. If not, move toOPENCLOSED: All systems good and healthy.
And the transition between each happens based on thresholds that are configured.

You can configure application properties for circuit breaker like this:
resilience4j.circuitbreaker:
instances:
backendA:
registerHealthIndicator: true
slidingWindowSize: 10
permittedNumberOfCallsInHalfOpenState: 3
slidingWindowType: TIME_BASED
minimumNumberOfCalls: 20
waitDurationInOpenState: 50s
failureRateThreshold: 50
eventConsumerBufferSize: 10
| Config Property | Description |
| failureRateThreshold | Configures the failure rate threshold in percentage. |
| slowCallRateThreshold | Configures a threshold in percentage. The CircuitBreaker considers a call as slow when the call duration is greater than slowCallDurationThreshold |
| slowCallDurationThreshold | Configures the duration threshold above which calls are considered as slow and increase the rate of slow calls. |
| permittedNumberOfCalls | |
| InHalfOpenState | Configures the number of permitted calls when the CircuitBreaker is half open. |
| maxWaitDurationInHalfOpenState | Configures a maximum wait duration which controls the longest amount of time a CircuitBreaker could stay in Half Open state, before it switches to open. |
| slidingWindowType | COUNT_BASED or TIME_BASED |
| slidingWindowSize | Configures the size of the sliding window which is used to record the outcome of calls when the CircuitBreaker is closed. |
| minimumNumberOfCalls | Configures the minimum number of calls which are required (per sliding window period) before the CircuitBreaker calculates error rate or slow call rate. |
| waitDurationInOpenState | Time that the CircuitBreaker should wait before transitioning from open to half-open. |
| automaticTransition | |
| FromOpenToHalfOpenEnabled | Boolean flag that transitons automatically from OPEN to HALF_OPEN |
| recordExceptions | List of exceptions that are recorded as a failure and thus increase the failure rate. |
| ignoreExceptions | List of exceptions that are ignored and neither count as a failure nor success. |
| recordFailurePredicate | Custom Predicate which returns if an exception should be considered as failure |
| ignoreExceptionPredicate | Custom Predicate which returns if an exception should be ignored and also not count as success/failure |
| Source of config is official docs |
Pattern 3: Rate Limiter
This is useful for for handling unexpected spikes in the API requests due to your app going viral or someone executing a DDOS attack.
If you have a legitimate user, you want to enqueue the requests, but if you have a bad actor doing DDOS attack you might want to discard those requests.
You can configure application properties for rate limiter like this:
resilience4j.ratelimiter:
instances:
backendA:
limitForPeriod: 10
limitRefreshPeriod: 1s
timeoutDuration: 0
registerHealthIndicator: true
eventConsumerBufferSize: 100
backendB:
limitForPeriod: 6
limitRefreshPeriod: 500ms
timeoutDuration: 3s
You can configure Rate Limiter via RateLimiterConfig as a Bean here:
RateLimiterConfig config = RateLimiterConfig.custom()
.limitRefreshPeriod(Duration.ofMillis(1))
.limitForPeriod(10)
.timeoutDuration(Duration.ofMillis(25))
.build();
// Create registry
RateLimiterRegistry rateLimiterRegistry = RateLimiterRegistry.of(config);
// Use registry
RateLimiter rateLimiterWithDefaultConfig = rateLimiterRegistry
.rateLimiter("backendA");
RateLimiter rateLimiterWithCustomConfig = rateLimiterRegistry
.rateLimiter("backendB", config);
| Config Property | Description |
| timeoutDuration | The default wait time a thread waits for a permission |
| limitRefreshPeriod | The period of a limit refresh. After each period the rate limiter sets its permissions count back to the limitForPeriod value |
| limitPeriod | The number of permissions available during one limit refresh period |
| Source of config is official docs |
Pattern 4: Bulkhead Pattern
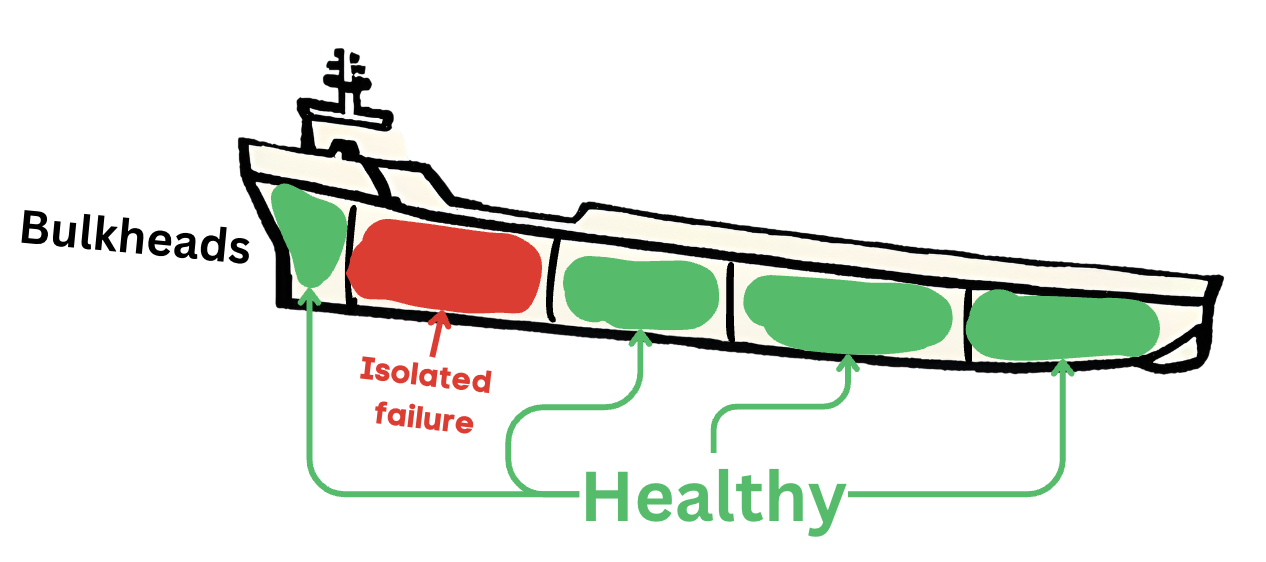
For high-availability and data governance, multi-site applications are deployed so that there is not single point of failure if one data-center goes down. Bulkhead pattern is inspired by ships with bulkheads where the issue in 1 bulkhead is isolated to that area only. Similarly, Bulkhead pattern in software systems ensures that the issues such as resource exhaustion of a client, data-center failure are isolated issues and do not take down the enitre system.
Separate Thread Pools and redundant API instances in different VMs/Data-centers are created to ensure that failure in one part of system does not bring the entire system down.
You can configure application properties for bulk head like this:
resilience4j.bulkhead:
instances:
backendA:
maxConcurrentCalls: 10
backendB:
maxWaitDuration: 10ms
maxConcurrentCalls: 20
resilience4j.thread-pool-bulkhead:
instances:
backendC:
maxThreadPoolSize: 1
coreThreadPoolSize: 1
queueCapacity: 1
| Config property | Description |
| maxConcurrentCalls | Max amount of parallel executions allowed by the bulkhead |
| maxWaitDuration | Max amount of time a thread should be blocked for when attempting to enter a saturated bulkhead. |
| maxThreadPoolSize | Max Thread pool sizex |
| coreThreadPoolSize | Core Thread Pool Size |
| queueCapacity | Capacity of queue |
| keepAliveDuration | When the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating. |
| Source of config is official docs |
Usually this pattern is in place at the API gateway level. We will go into this pattern again in Proxies section
Sidecar Pattern and Service Mesh
Sidecar Pattern
Applications are not just business logic code. You have a lot of components which are common across all microservices such as:
Logging
Monitoring agents such as Dynatrace, NewRelic for Telemetry data
Network Proxy to other Services
Secrets management such as Vault, KMS etc
And more...
So the solution is put these common overlapping components as an adjacent component which can be inserted as an agent in the VM.
Examples sidecars available of the above common components discussed earlier:
| Sidecar component | Description | Example |
| Logging | Usually it is part of code, but STDOUT can be used in a sidecar | Kubernetes Sidecar Logging |
| Monitoring | Agents used for observability. | Dynatrace OneAgent, Datadog Agent |
| Secrets management | Secrets managed by a sidecar | Hashicorp Vault Agent injector |
| Service discovery | Service discovery and Health endpoint as a sidecar instead of application logic | Dapr sidecar (daprd) |
| Network proxy | Traffic management | Envoy, HAProxy,Nginx Sidecar proxy |
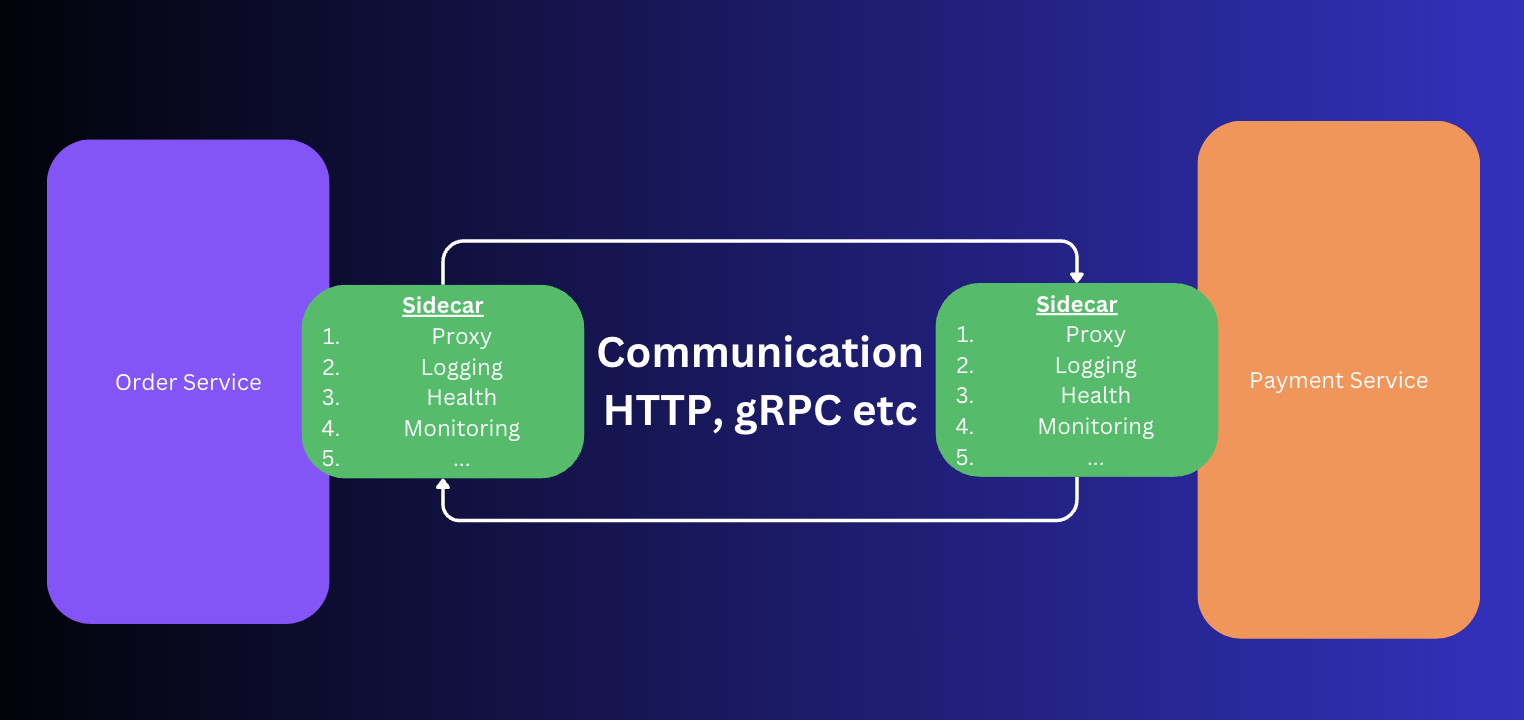
If you see the above diagram of Sidecar, you can see that it as a Choreographed architecture where each Service was responsible for the sidecar. If you want to add a touch of Orchestration on top of Sidecar, you get Service Mesh.
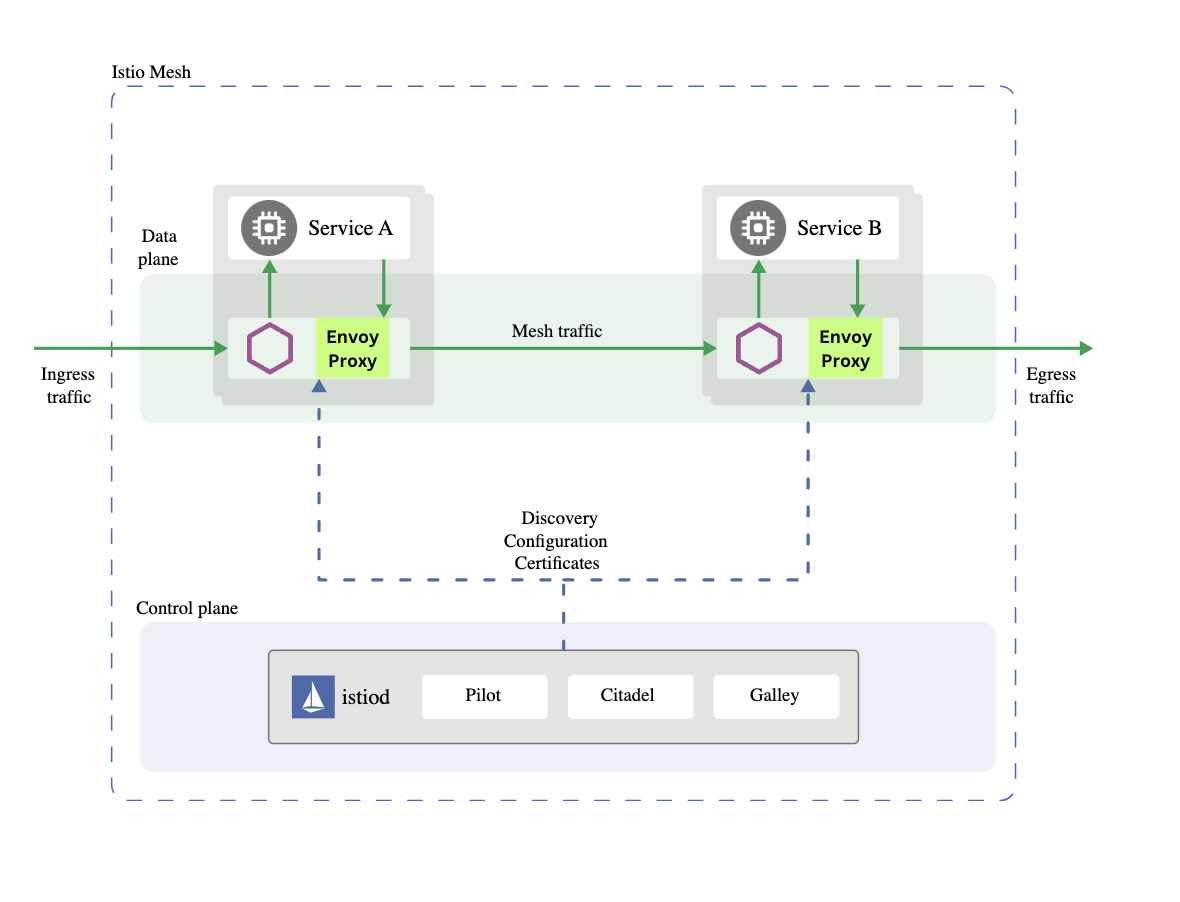
Service Mesh
Main features and problems solved by Service Mesh include:
Traffic management
Service Discovery
Load balancing
Security by enforcing mutual-TLS (mTLS)
Service mesh has 2 components: Data Plane and Control Plane
Data Plane(Choreography): This is handled by Proxies. These are network proxy sidecars discussed above. Its ownership include:
Service Discovery
Load balancing
Traffic management including canary deployments
HTTP/2, gRPC, GraphQL proxies
Resiliency using retries, circuit breaker
- Low-level metrics of the container
Health checks
Control Plane(Orchestrator): Its feature includes(some overlap with data plane):
Service Registration
Adding of new services and removing inactive services
Resiliency using retries, circuit breaker
Collection and aggregation of observability data such as metrics, logs and telemetry.
A typical well known example is Istio and Envoy.
Istio is the control plane and Envoy is the data plane
Proxies
This section will be just a listicle of proxy tools. Managing them and gaining insights is a full-time SRE job which I am not at this moment.
Proxies are a powerful concept for traffic management. A lot of resiliency patterns can be implemented without any business logic, and relying on API gateway and proxies. But it is imperative to have good observability as it might be a blackbox making it harder to debug.
- Nginx
Nginx is one of the most common Load Balancer/Web Server/Reverse proxy out there. Due to this longevity and popularity, a lot of sidecar and proxy patterns are available out-of-the-box.
HTTP Proxy Module of Nginx can be found here
Rate limiting can be achieved by using Nginx Limit Req Module
Load shedding using Nginx Limit Connection Module Nginx can be used as an enhanced service mesh in a Kubernetes cluster using Nginx Service mesh
- HAProxy
One of the most widely used OSS Load Balancer which has a lot of features in the OSS offering itself.
-
- You can observe errors at both Layer7 (HTTP) and Layer4 (Application layer)
- Caddy Written in Go, its main selling point is ease of creating extensions and automatic zero-hassle SSL certification generation.
- Envoy
It wad built at Lyft as a Sidecar proxy that works well with Istio Service Mesh. It is written in C++ and is a L3/L4 proxy which can help with proxies at a lower level (TCP/UDP) and also hook into database internals for Postgres, Mongo, Redis etc
Features include:
Native support for HTTP/2 and gRPC
Retries, Circuit breaking, rate limiting, Load balancing (Zone-wise)
L7 Observability, Distributed tracing and can also look into MongoDB, Postgres, MySQL etc
Quotes for Distributed Systems
Distributed systems: Untangling headphones while riding a rollercoaster (ChatGPT generated)
Hope is not a strategy
Is it a sick cow, is it a sad cow or is it mad cow disease?
Subscribe to my newsletter
Read articles from Ayman Patel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ayman Patel
Ayman Patel
Developer who sees beyond the hype