Beyond the Basics: Demystifying Facebook's Approach to Scaling Memcached (Part 1)
 Aditya Gupta
Aditya Gupta
I spent hours reading the paper "Scaling Memcache at Facebook", and trust me, it's filled with a lot of information! Technical papers can be quite dense and that's why wrote this blog to break down the key ideas clearly and concisely. So, whether you're new to Memcached or just want a refresher, this series will give you a solid understanding of how Facebook scales this powerful caching tool.
After I started reading the paper, the depth of the material became clear - one blog simply wouldn't do it justice. Therefore, I'll be tackling this paper in a series of easy-to-follow posts. Each post will focus on key concepts, and I'll include plenty of references for further exploration. Additionally, if a specific concept warrants a deeper dive, I'll dedicate a separate post to it and link back here for a smooth reading experience.
So what is Memcached?
Memcached is an open-source, in-memory caching solution. It acts as a key-value store, caching small chunks of data from database calls, API calls, or page rendering. In essence, it speeds up applications by caching frequently accessed data. The paper, "Scaling Memcache at Facebook" explains in-depth how Facebook leverages Memcached as a building block to construct and scale a distributed key-value store that supports the world's largest social network. According to the paper, this system handles billions of requests per second and holds trillions of items to deliver a rich experience for over a billion users around the world.
Introduction
Social Networking sites are data-intensive, i.e. they impose huge computational, network, and I/O demands. In a gist, the infrastructure needs to
Allow near real-time communication
Aggregate content from multiple sources
be able to access and update shared content
process millions of requests per second
To satisfy these demands, Facebook utilizes Memcached. However, they don't rely on the standard open-source version. Instead, they've heavily modified it to handle the millions of requests per second that Facebook experiences.
This enables Facebook to serve data-intensive pages. Imagine a page that triggers hundreds of database requests, it'll never make it to production because it's slow and expensive. However, with Memcached in the picture, many of these requests can be served directly from the cache, significantly speeding up page delivery and reducing the burden on the database.
For example, let's say a user tries to access an ecommerce site and one of the things the website needs to show is a list of trending products. Since this information is the same for many users, it doesn't make sense to constantly query the database. Instead, we can store this data in Memcached. This way, the website can retrieve the trending product list quickly from Memcached instead of hitting the database every time.
Overview
First, People tend to consume content more than create it. This results in the application making more and more GET calls than POST. According to a study by Vidmob, young social users consume much more than they create:
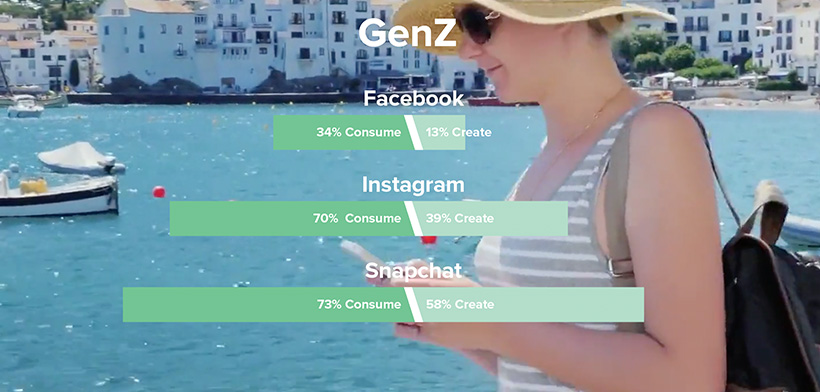
Because we are making more GET calls, having a cache mechanism can have a massive advantage. Second, large-scale applications collect data from many places, like databases, file systems, and internal services. Since this data comes from different sources, we need a caching system that can handle it all.
Did you notice the paper's title features "Memcache" while the open-source caching system is referred to as "Memcached"?
Memcached (the open-source version) offers a basic set of functions: storing, retrieving, and deleting data. This simplicity makes it a perfect building block for large systems. Facebook capitalized on this advantage by improving Memcached's efficiency and creating a high-performance distributed key-value store that can handle billions of requests per second. So, Memcached refers to the source code, or the basic building block itself, while Memcache refers to a distributed system built using multiple Memcached components.
So next, Facebook uses caching in 2 ways:
Query Cache
Generic Cache
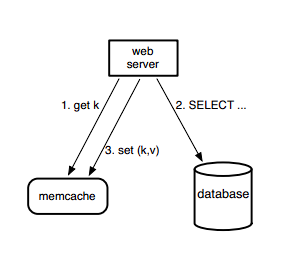
Query Cache: Let's first look at what happens when an application sends a GET request. Facebook uses Memcached as a demand-filled look-aside cache.
Web servers look for data in the cache first. If it's not there, they fetch it from the database or another source and store a copy in the cache for future use.
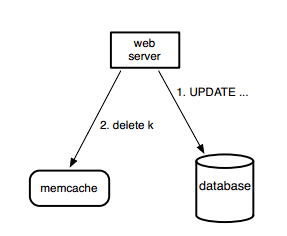
For all the write requests, the web server sends the request directly to the database and then sends the delete request to the cache. They choose to delete the value in the cache rather than update because deletes are idempotent.
Generic Cache: Memcache goes beyond just caching web data. It acts as a flexible storage system for various types of information. For instance, engineers use it to store pre-calculated results from complex machine learning algorithms. This allows other applications to easily access this data without needing separate servers or complex setups. They simply plug into the existing memcache infrastructure, saving them time and resources.
Memcached, as an elemental block, doesn't work together with other memcached servers automatically. It's like a super fast dictionary stored in memory on just one machine. In the upcoming posts, we'll discuss how Facebook scaled this basic building block into a distributed system. The paper mainly focuses on how facebook handles the massive workload.
Here are some of the major concerns:
Read-heavy workload: as discussed earlier, users consume more data than create, i.e. there are more read requests
Wide fan-out: In computer science, "fan-out" refers to how many destinations a single piece of information needs to be sent to. In this case, "wide" indicates a large number of destinations. So, a "wide fan-out" means a single piece of data (like a frequently accessed Facebook post) needs to be copied and stored on many different Memcached servers.
Data replication: More servers, more challenges: As we add clusters to handle increased traffic, keeping data consistent across them becomes a key issue.
This blog post has provided a high-level overview of the paper on scaling memcached at Facebook. We've explored the different scales Facebook considers and the challenges they address at each stage. But the journey doesn't end here!
In the next blog post, we'll dive deeper into the technical details. We'll focus on the critical topic of "In a cluster: latency and load." This will unpack how Facebook optimizes performance within a single cluster of Memcached servers, ensuring fast data access for a massive user base.
A like to the blog would make me happy happy. Stay Tuned. Peace
Subscribe to my newsletter
Read articles from Aditya Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Gupta
Aditya Gupta
Hey there, I’m Aditya, a Software Developer at Fidelity Investments. I’m really into all things tech and love geeking out about it. My memory isn’t the greatest, so I use this blog to keep track of everything I learn. Think of it as my personal journal—if you enjoy it, hit that follow button to keep me inspired to write more!