The Data Lineage Advantage
 Priti Biyani
Priti Biyani
In a data world as heavy as banking platforms, there is always an origin, data transformation with a set of rules flooded across multiple services and data is stored for using it further by downstream. To be a true data product, it should be addressable and discoverable. Data Lineage exactly helps to do that.
and there is always a story..
The data products I worked Looked like follows:
There is a batch which runs every day, which ingest the data to our product say instruments, transactions, portfolios, different current exchange rates
There are a bunch of rules applied to this data before storing data in format that our system demands which includes so many calculations and transformations. Transactions processing also end up creating positions. A position is result of series of transactions.
This data gets stored against time T by replacing existing positions if any.
There are few API which serve this data as is, where as some API also calculates some data runtime depending on the date range user selects.
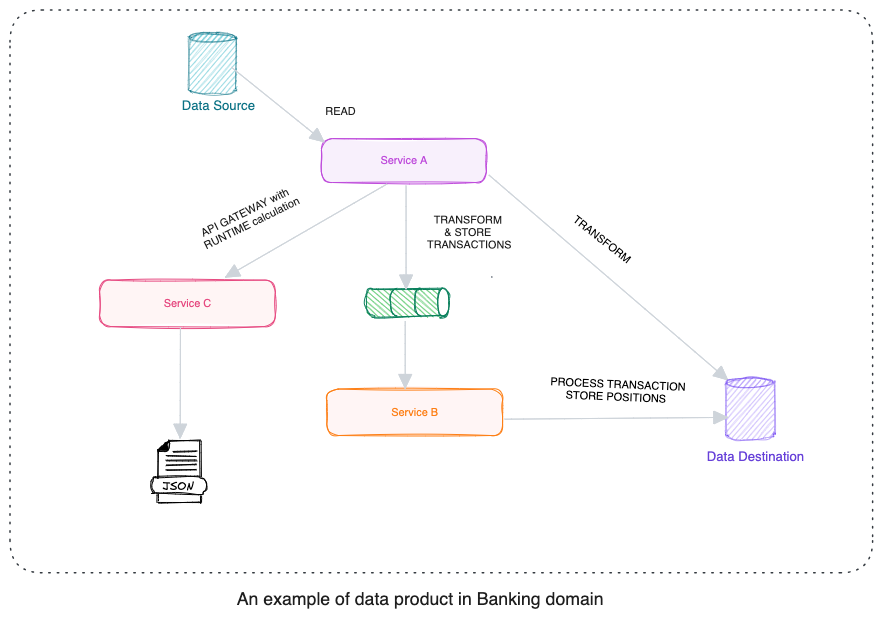
This is similar to any ETL(Extract-Transform-Load) system and imagine following scenario:
You get an urgent call at midnight about an important portfolio and there are some mismatches in the transaction calculation.
A possible debugging solution for this one could be to just go to the database, follow the trail of the data and understand where it has gone wrong!
But wait, it's not simple. Data is dynamic in nature (eg. Currency Exchange rates), so to understand how that is derived, we need all the inputs for time T at which these calculations took place.
And if there is any backdated transaction, all the best in debugging that!
Given this is scenario, we know how it is important in data products that they should be addressable (refer to data at time T) and discoverable (how particular data is derived)
This can only happen if some metadata was captured during the calculation. Lineage helped us to tackle this complexity.
Understanding Data Lineage
It is the process of understanding, recording, and visualizing data as it flows from data sources to consumption. This includes all transformations the data underwent along the way—how the data was transformed, what changed, and why.
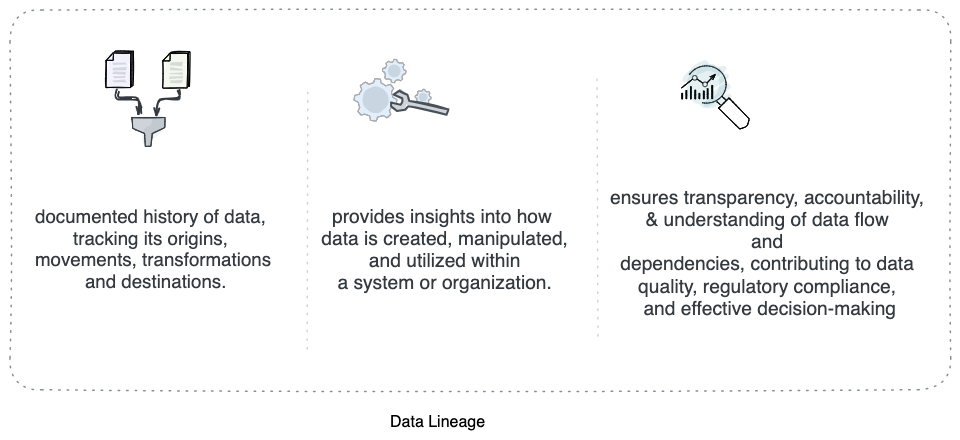
Define intent of Lineage:
We conducted multiple quick proof-of-concepts (POCs) to refine the requirements through discussions with domain experts and individuals who have experienced support query issues with the existing system. Through this process, we were able to identify some high-level requirements for our data product in terms of -ilities, along with example use cases.
| -lities | Use Case | feasible to implement within the existing platform? |
| Traceability | Understand how a specific transactional position was derived for the given as-of date, including the direct inputs, derived inputs, and the formula used. | NO |
| Addressability | Access the data at time T. Certain data, such as instruments and portfolios, remains fixed, while others, like fxRates, are dynamic. Additionally, derived data, such as positions, should also be accessible at time T. | NO |
| Usability | The lineage data should be accessible via API using a unique identifier, such as lineageID for internal purposes and apiLineageId for API access. | NO |
The other abilities, such as maintainability and extensibility, are implicit and inherent to the overall design.
How we implemented Lineage
Since we realized that adding lineage to our current platform wouldn't work, we decided to make some changes to our platform to make it ready for above -lities.
Step 1: Immutable database
As we needed the ability to access data at a specific time (time T), we realized that our current database setup wasn't suitable. The database used to get replace if there's a new backdated transaction or an update to the same instrument.
To ensure accurate data referencing in the lineage, allowing us to access data at time T and refer to the correct inputs, we decided to implement a bitemporal database. This involved capturing both time T and a unique identifier apart from entity_ID. Previously, each entity was identified using (entity_ID + Locale), and we expanded this to include (entity_ID + Locale + unique_identifier). This setup allowed us to access data for a provided as_of_date as each document had time element captured.
While one teammate focused on creating the bitemporal database, I worked on converting the mutable database structure to an immutable one within the code. Since we weren't live yet, we didn't have to worry about database migration and other complicated use cases.
We tackled each entity individually to implement the changes mentioned above. Once the modifications were completed, we simply reran the data ingestion process. Subsequent runs resulted in the creation of a new document each time.Think of this as a time series of updates to the same entity. With the entity being immutable, any change made to it resulted in a corresponding record in the database. This essentially captures the snapshot of the system state against time T.
This implementation enhanced our platform with addressability, ensuring we could refer to the correct inputs at any given time.
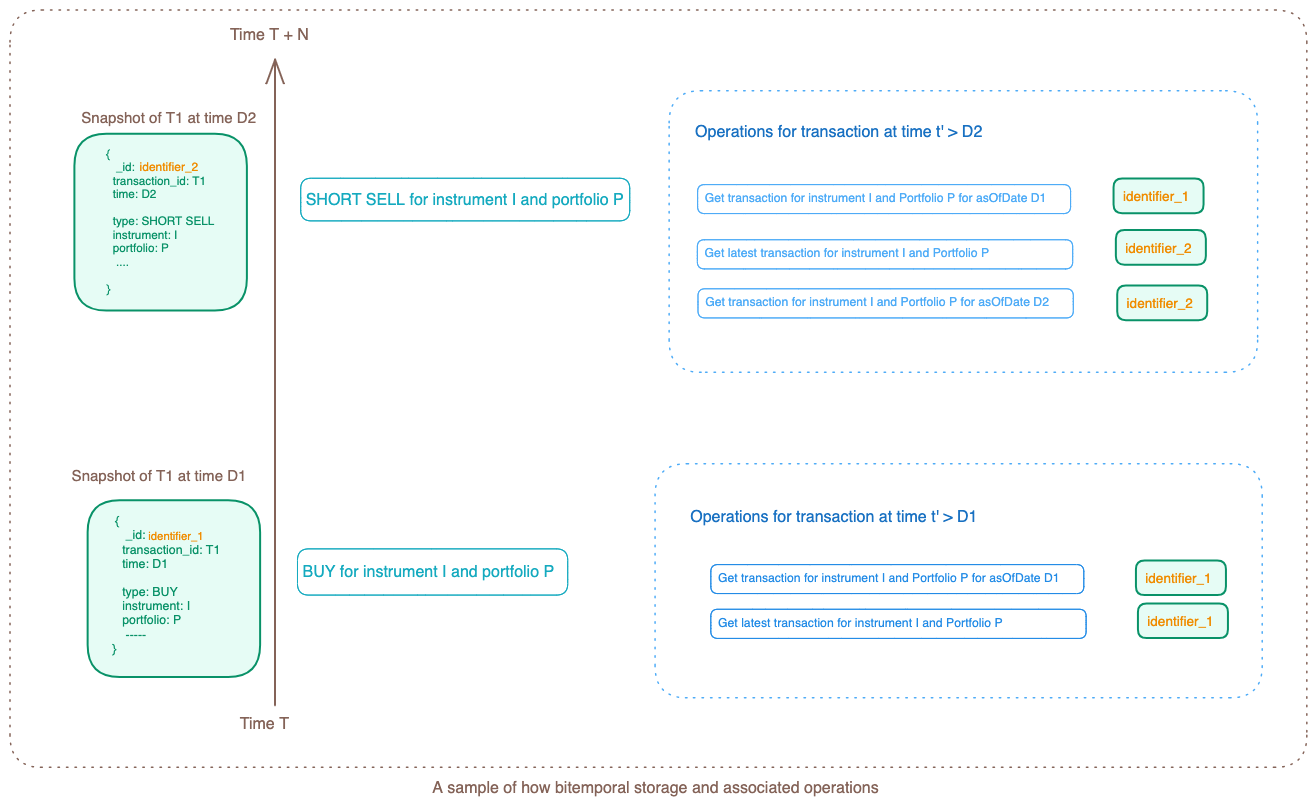
Step 2: Correlation ID
To ensure accurate tracking of origins at any given time, we implemented a system within the product where each API is assigned a unique correlation ID. Consequently, the batch system, which runs daily and calls these APIs, generates unique correlation IDs, potentially associated with multiple lineages.
This initiative significantly enhanced the platform's usability, ensuring that we have correct origin captured for every data ingestion.
Step 3: Build Lineage
We considered two approaches for implementing lineage.
Initially, we thought of playing the same set of events whenever lineage was requested, as we already had all the data. This approach would save storage and overhead since we wouldn't need to store all identified data. However, we discarded this idea because the code might change over time, potentially compromising true traceability if formulas or inputs change.
Instead, we decided to store all the metadata used along the way. While some data could be referenced as each entity was discoverable, we opted to copy and store other data, even though it wasn't huge.
As we used mongoDb for our other storage needs, we defined schema for the lineage and let it evolve over time. To be discoverable and easy to access, one document was one lineage and each with its own lineageId and type.
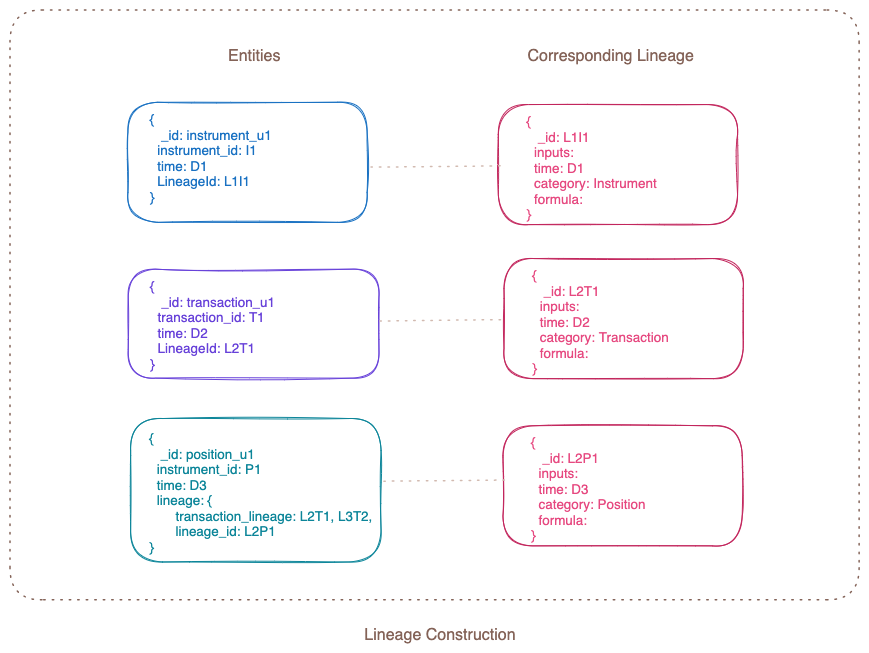
This approach significantly enhanced the platform's traceability.
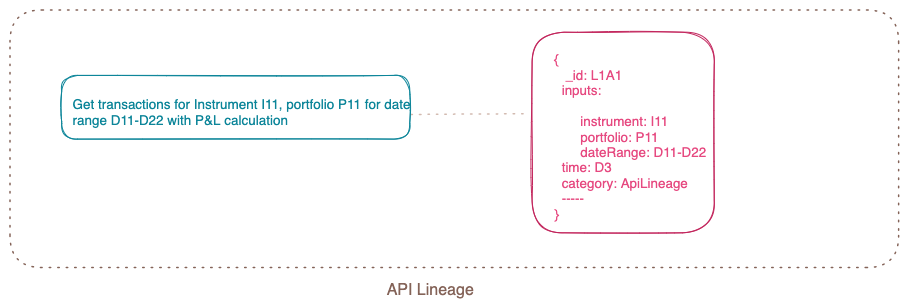
Step 4: API Lineage
When any downstream system called our API to consume data for further API layer building, we began generating lineage IDs for all these API requests, including all the details of the request attributes.
This enabled us to trace the trail of the data in case we needed to debug any support queries.
Implementing API lineage IDs not only enhanced the platform's usability but also added support for debugging.
Step 5: Add dashboard and APIs for lineage
API: We developed specialized APIs to access lineage data using lineage IDs and correlation IDs. The API outcome was CSV, so that its easier to import and viewing of results in Excel.
Dashboard: Although our system was primarily backend-focused, we quickly built a user interface dashboard using templating engines to dynamically generate HTML from templates. This made it much easier to navigate through the lineage and view the data. My teammate spearheaded this effort, and when we saw the result, we were impressed by how it simplified access, viewing, and navigation of all the data.
Lessons Learned
Lineage should ideally be established before the system goes live. This ensures that data origins can be traced in case of issues or data loss. Much like preparing for performance improvements before launch, building lineage should be integrated into the final stages of system development.
There are tools available to build the lineage, but building it by ourself gave us room to customize the code, build some additional use cases.
Challenges in building lineage
The challenges of building lineage depend on the application's state. In our experience, implementing lineage before going live posed certain challenges:
Data is distributed across services.
Some services may require refactoring to accommodate data tracking.
The platform might not be ready to begin building lineage right away.
Designing perfect lineage is an iterative process that requires continuous refinement.
Dedicated time and resources are necessary for this endeavor.
Business-as-usual (BAU) APIs should not be impacted by the addition of lineage, and performance for lineage is crucial.
We encountered performance issues, prompting consideration for separating the lineage database due to the creation of large indexes with extensive datasets.
Implementing lineage on existing live services can be challenging, especially if the system isn't prepared to track the correct and necessary data. Although there are tools available in the market for capturing lineage, we have decided to build our own solution. This approach is tailored to our custom needs and allows for future enhancements.
Thank you, Natalie, for reviewing this blog. It was a pleasure working with you on our data lineage journey. You kept the momentum going on by creating user-friendly dashboard.
Subscribe to my newsletter
Read articles from Priti Biyani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Priti Biyani
Priti Biyani
Ten-year ThoughtWorks veteran, based in Singapore. Skilled in full-stack development and infrastructure setup, now focusing on backend work. Passionate about TDD, clean code, refactoring, DDD and seamless deployment. I thrive on the entire software delivery spectrum, relishing the journey from conceptualisation to deployment Enjoys painting and dancing outside of work.