Exploring Read Replicas in Database Systems
 Cloud Tuned
Cloud Tuned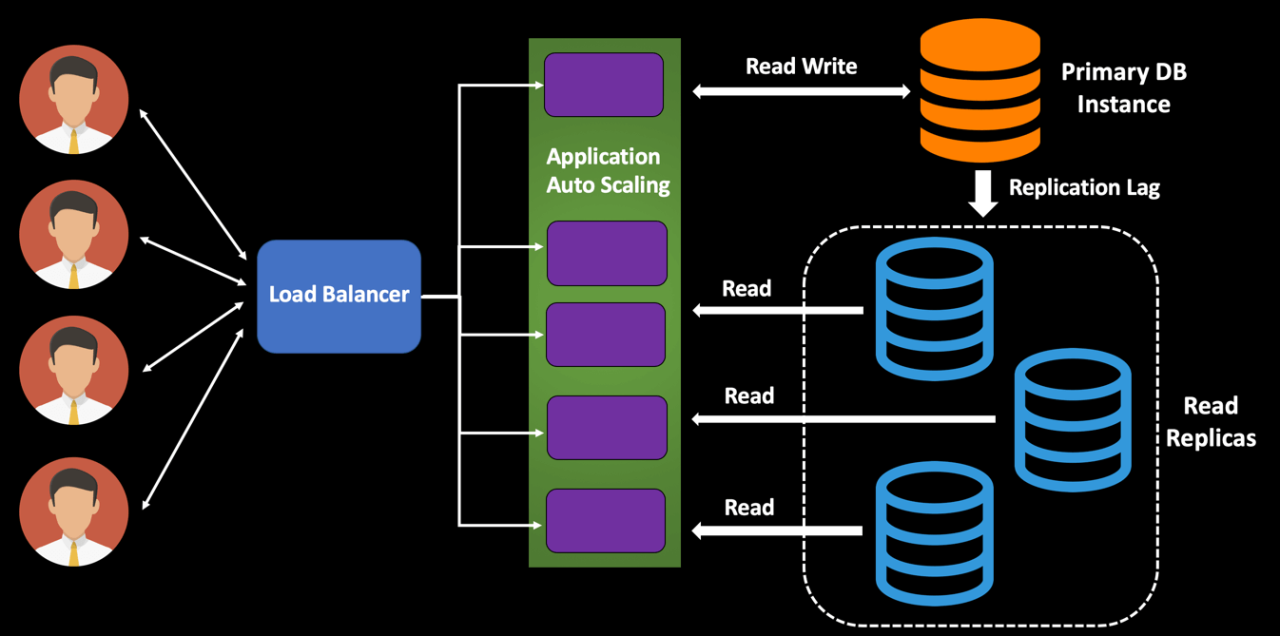
Exploring Read Replicas in Database Systems
Read replicas are a key component of database scaling strategies, allowing for improved read performance and redundancy in distributed systems. In this article, we'll delve into the world of read replicas, understanding their purpose, implementation, and benefits in database architectures.
Understanding Read Replicas
Read replicas are copies of a primary database instance that are synchronized asynchronously to handle read-only queries. They serve as additional endpoints for querying data, alleviating the load on the primary database and improving overall read performance. While read replicas contain the same data as the primary database, they do not handle write operations and are typically used for read-heavy workloads.
Implementation of Read Replicas
Read replicas can be implemented in various ways, depending on the database system and architecture:
- Database Replication: Most database systems support native replication mechanisms for creating read replicas. These mechanisms involve copying data from the primary database to one or more replica instances, either synchronously or asynchronously.
- Load Balancing: Read replicas can be deployed behind a load balancer that distributes read queries across multiple replica instances. This ensures optimal utilization of resources and improves scalability and fault tolerance.
- Topology: Read replicas can be deployed in different topologies, such as master-slave replication, multi-level replication, or chained replication, depending on the requirements of the application and the desired level of redundancy.
Benefits of Read Replicas
Read replicas offer several benefits in database architectures, including:
- Improved Read Performance: By distributing read queries across multiple replica instances, read replicas reduce the load on the primary database and improve read performance for users.
- High Availability: Read replicas enhance fault tolerance and availability by providing additional endpoints for querying data. In the event of a primary database failure, read replicas can serve as standby instances to prevent downtime and data loss.
- Scalability: Read replicas support horizontal scaling by allowing applications to scale out read capacity independently of the primary database. This enables applications to handle increasing read workloads without affecting write performance.
Conclusion
Read replicas play a crucial role in database scaling strategies, providing improved read performance, fault tolerance, and scalability in distributed systems. By distributing read queries across multiple replica instances, read replicas help optimize resource utilization and enhance the overall performance and availability of database systems.
Are you interested in learning more about read replicas and their applications? Share your thoughts and questions in the comments below! Don't forget to subscribe to our blog newsletter for more insightful content on database management, scalability, and performance optimization.
Unlock the power of read replicas and enhance the performance and availability of your database systems today! 🛠️🔍
Subscribe to my newsletter
Read articles from Cloud Tuned directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by