Support Vector Machines (SVM) - Supervised Learning Classification
 Retzam Tarle
Retzam Tarle
print("Support Vector Machines (SVM)")
Support Vector Machines(SVM) is a supervised learning classification model used in classification tasks. This uses support vectors and a hyperplane which is simply a line to differentiate classes.
The support vectors are the closest vectors(features) to the line separating features with separate data labels.
Consider the 2D plane below.
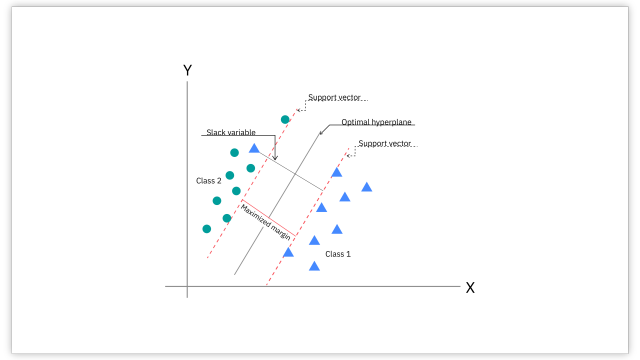
You can see that the support vector lines are drawn across the closest vectors, as we can see with the round and triangle shape class features. The hyperplane is then drawn in the middle which is an optimal line separating the two classes.
Well, that works fine, right? So items to the left of the hyperplane can be classified as a circle while items on the right are triangles. But then in real-life scenarios, most classes are not distinctive as shown above, the classes might be mixed a bit more. In such scenarios we use the kernel trick, to get the hyperplane.
The kernel trick looks like so:
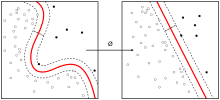
We can see that the hyperplane the kernel draws is not a straight line right? Well, this is important for solving real-life classification tasks.
Let's try to explain this using an illustration.
Consider officiating a team playing a game of throwing balls. Team A and Team B are standing in different parts of the room.
You notice that Team A players tend to throw the balls with a lot of force, while Team B players throw them more gently. Now, you're given the task of figuring out which team a new player belongs to, based on how hard they throw the ball.
Support Vector Machines (SVM) can help with this. It's like drawing an imaginary line between where Team A is standing and where Team B is standing. This line is drawn in such a way that it creates the biggest gap between the two teams.
Now, if a new player comes along and throws the ball, you can see which side of the line they fall on. If they're on the same side as Team A, they're likely part of Team A, and if they're on the same side as Team B, they're likely part of Team B.
The goal of SVM is to find this imaginary line (or boundary) that separates the two groups (Team A and Team B) as clearly as possible. This line is called a "hyperplane." By finding the best hyperplane, SVM helps you classify new players into the correct team based on how hard they throw the ball.
To learn SVM in more depth check this article here.
Playground
Time for play play 🤗 retzam-ai.vercel.app. In this chapter, we trained a model to predict if a person would respond to a marketing campaign. We used Support Vector Machines, check it out directly here.
Enter the person's details as shown below.
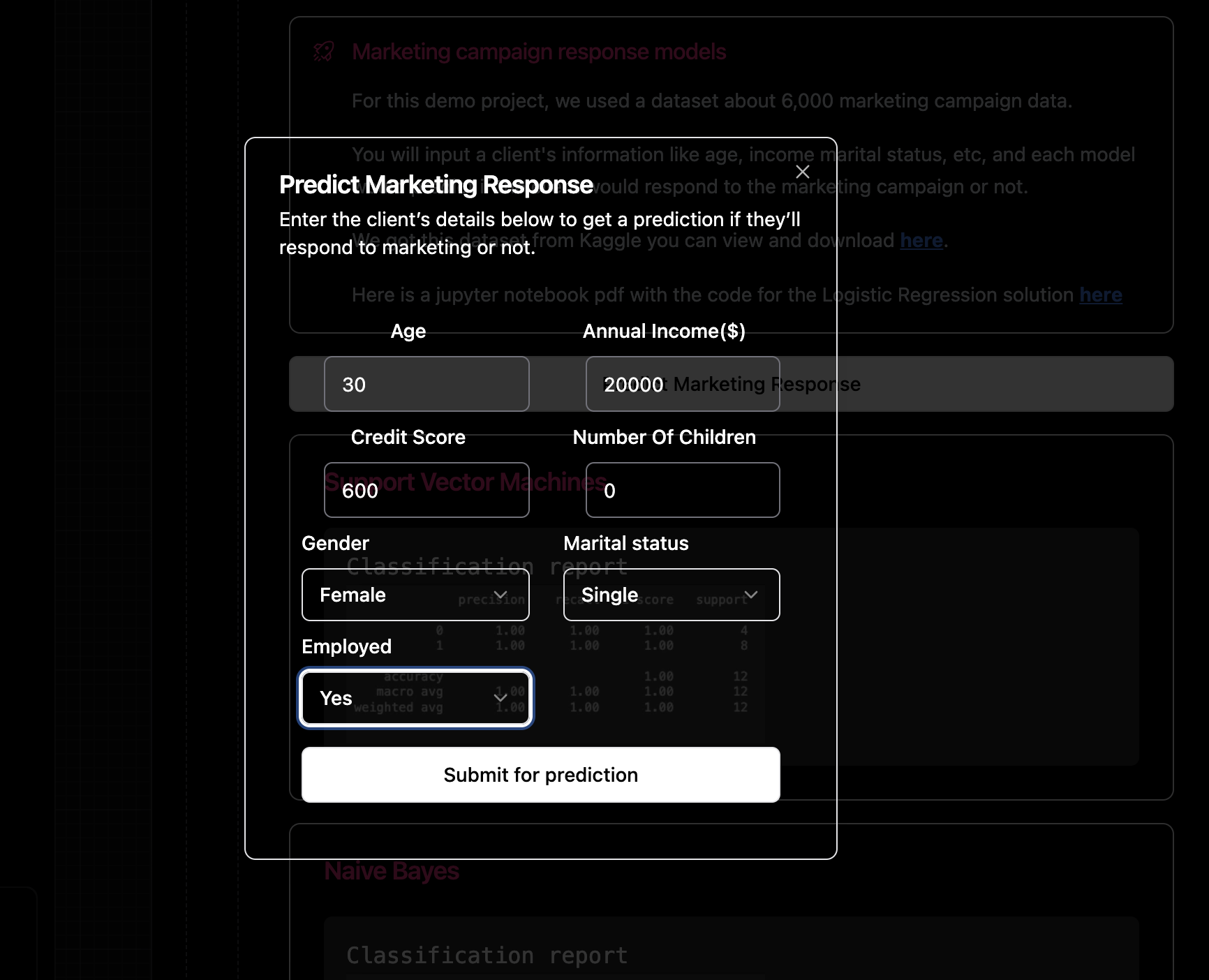
The model would then proceed to predict if the person would respond to the marketing campaign or not.
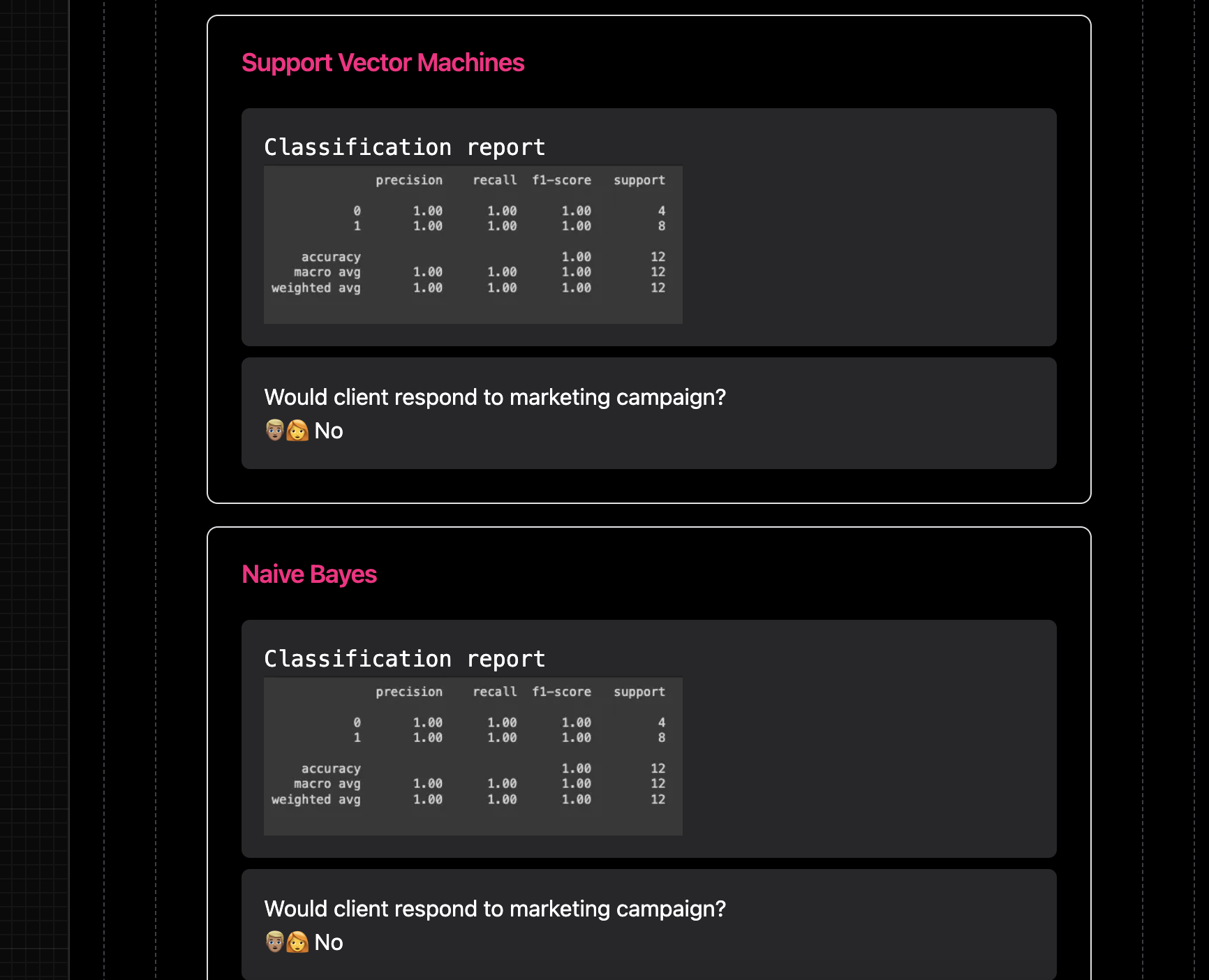
Keep in mind there are other models that make the predictions as well apart from SVM so compare their performance report and their predictions.
The image below shows the predictions for the model and the performance report.
Hands-On
We'll use Python for the hands-on section, so you'll need to have a little bit of Python programming experience. If you are not too familiar with Python, still try, the comments are very explicit and detailed.
We'll use Google Co-laboratory as our code editor, it is easy to use and requires zero setup.Here isan article to get started.
Here is a link to our organization on GitHub, github.com/retzam-ai, you can find the code for all the models and projects we work on. We are excited to see you contribute to our project repositories 🤗.
For this demo project, we used a dataset of about 6,000 marketing campaign data from Kaggle here. We'll train a model that would predict if a person would respond to a marketing campaign or not.
For the complete code for this tutorial check this pdf here.
Data Preprocessing
Create a new Colab notebook.
Go to Kaggle here, to download the players' injury dataset.
Import the dataset to the project folder
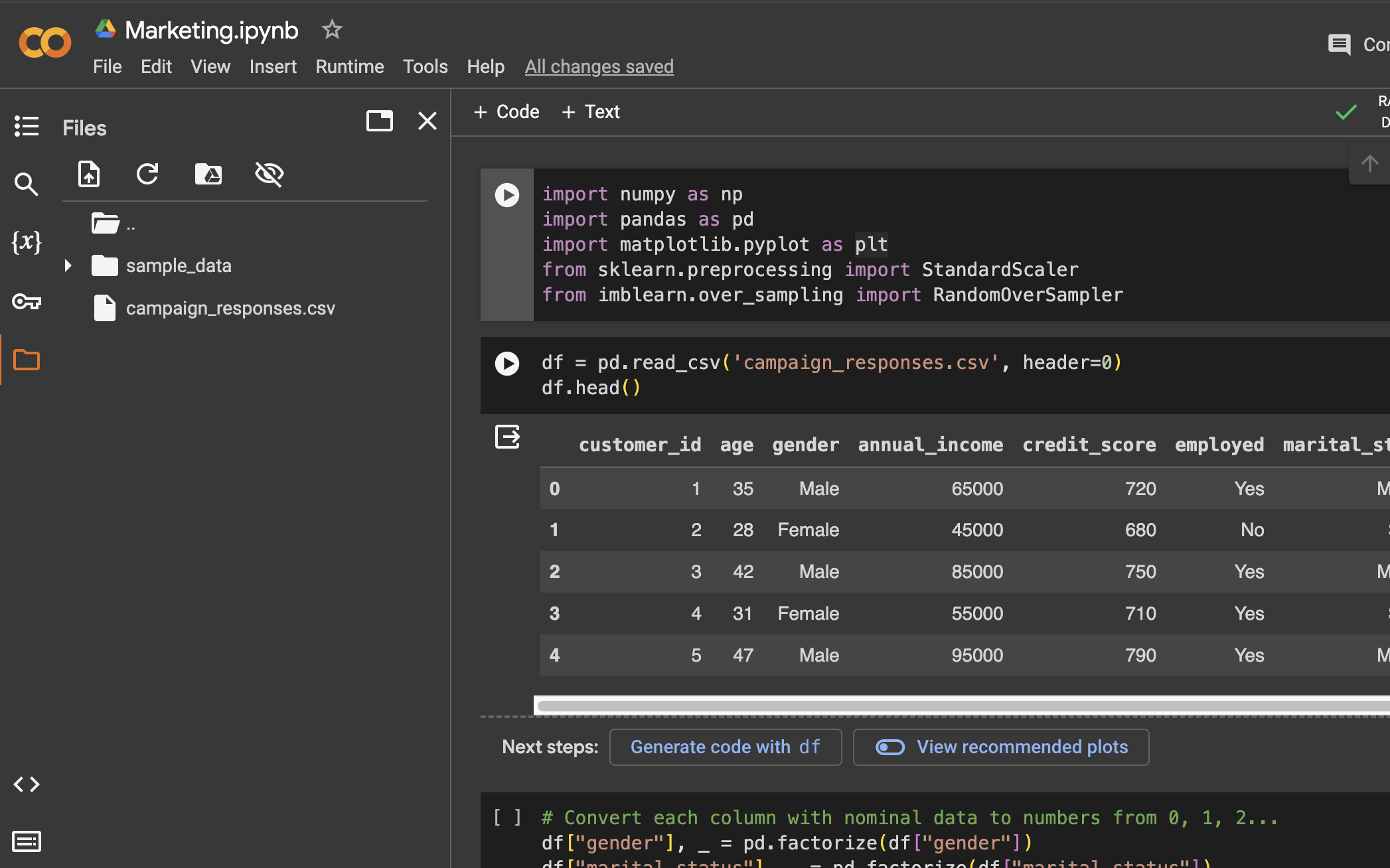
Import the dataset using pandas
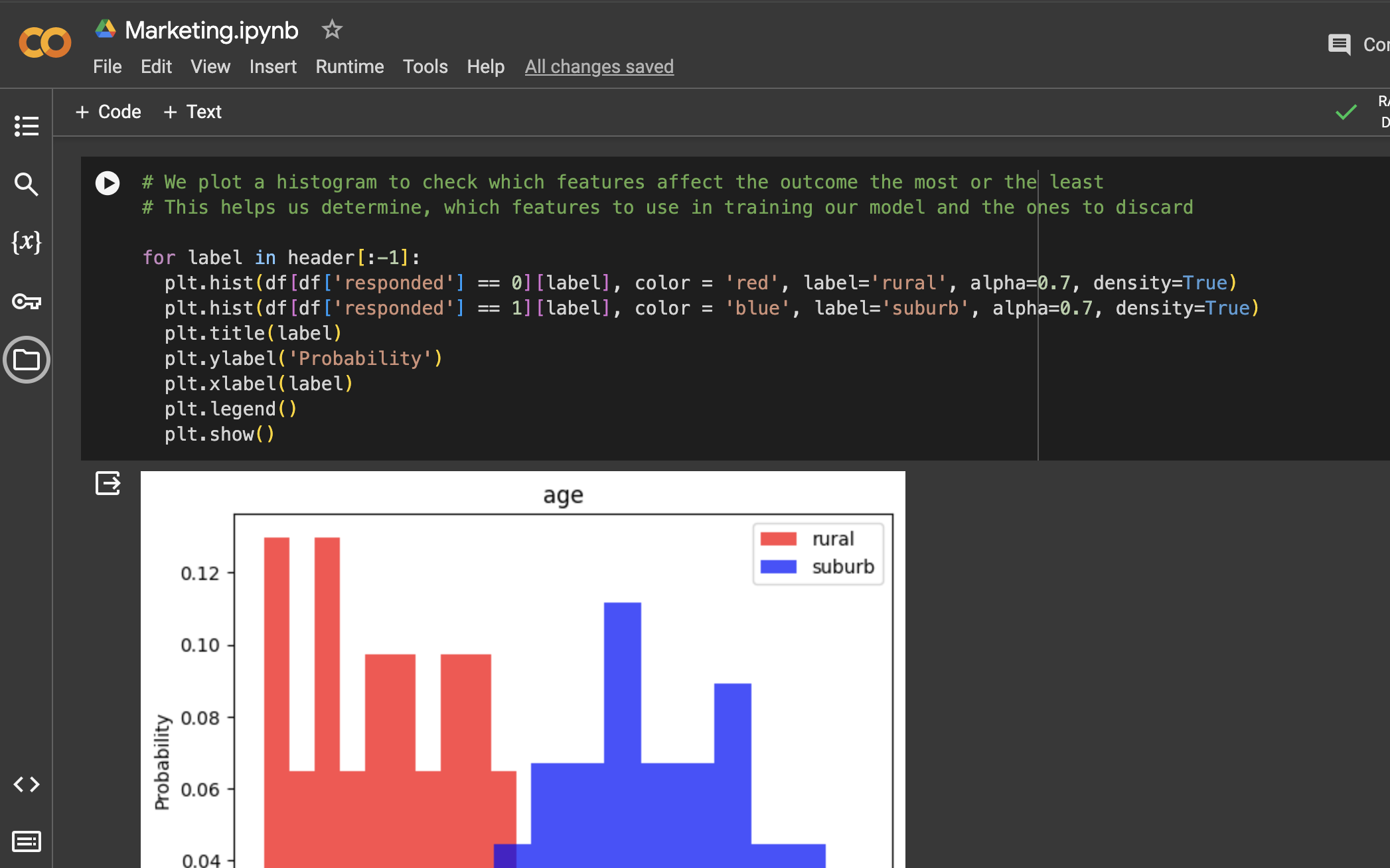
We plot a histogram to check which features affect the outcome the most or the least. This helps us determine, which features to use in training our model and the ones to discard.
We then split our dataset into training and test sets in an 80%-20% format.
We then scale the dataset. X_train is the feature vectors, and y_train is the output or outcome. The scale_dataset function over samples and scales the dataset. The pdf document has detailed comments on each line.
Performance Review
First, we'll need to make predictions with our newly trained model using our test dataset.
Then we'll use the prediction to compare with the actual output/target on the test dataset to measure the performance of our model.
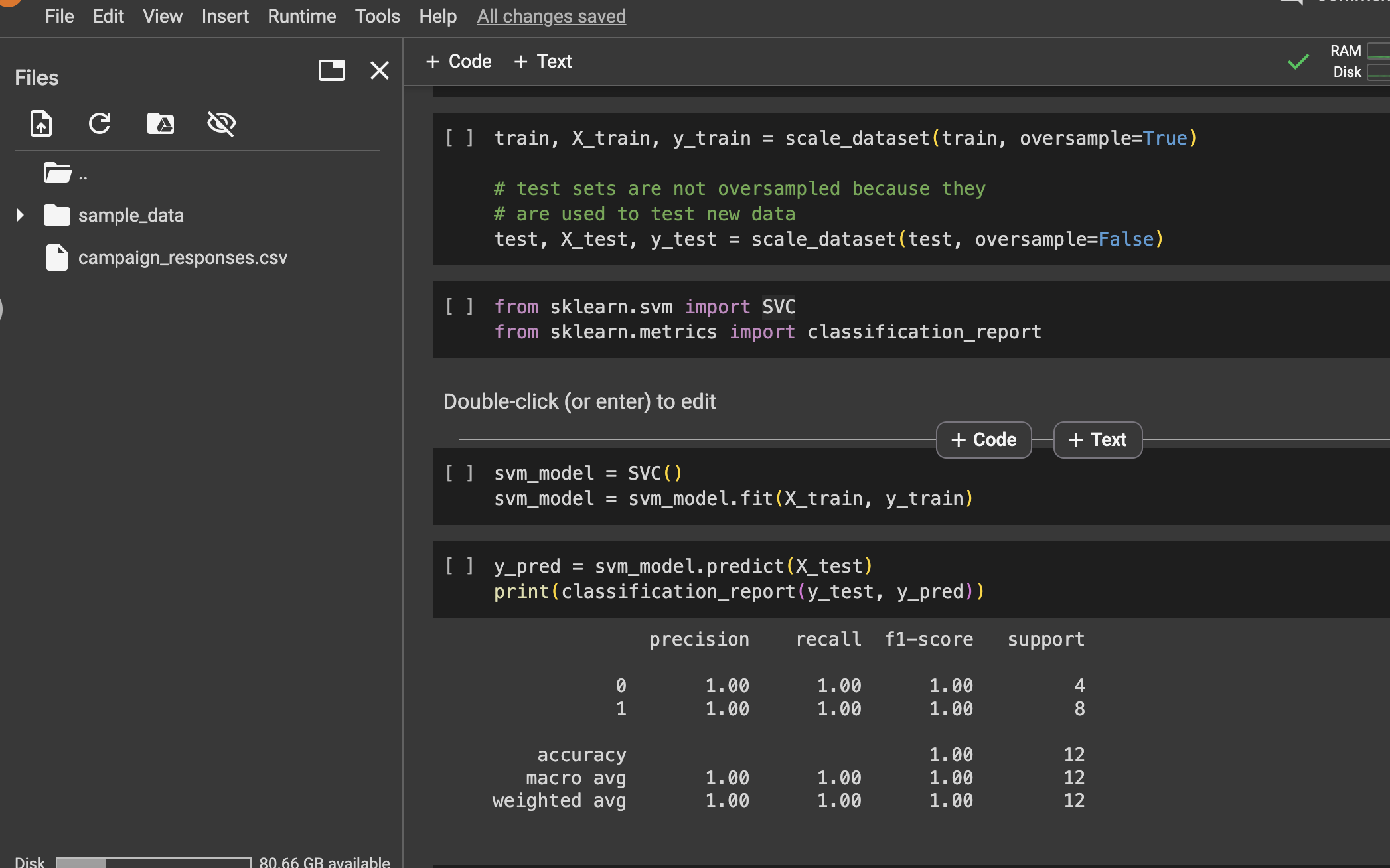
From the image above we can see the classification report.
This is as good as our last model with 100% accuracy 👽.
Don't forget to play 🛝 in the playground and compare the model's classification reports and predictions.
End of hands-on
Whew!👽 I have been growing and learning, hope you have as well.
We've been hands-on for weeks now 🦾 and practically creating AI models! There is still much to cover, but one at a time, one step after another.
In our next chapter, we'll talk about the last model in this series supervised learning classification: Random Forest 🌳🌲🌴.
See ya! 🤗
Subscribe to my newsletter
Read articles from Retzam Tarle directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Retzam Tarle
Retzam Tarle
I am a software engineer.