Batch processing in Mule 4
 Nandinee Ramanathan
Nandinee RamanathanWhat is batch processing?
Batch processing allows for the efficient processing of records in groups or batches.
Batch Processing is done by Batch Job and one or Batch Step
Configuration of Batch Job:
Batch Job instances is created based on the batch block size. For example, if there are 10,000 records and if block size is set to 100 then 1000 batch job instances is created.
The scheduling strategy can be configured as Ordered_Sequential and Round Robin.
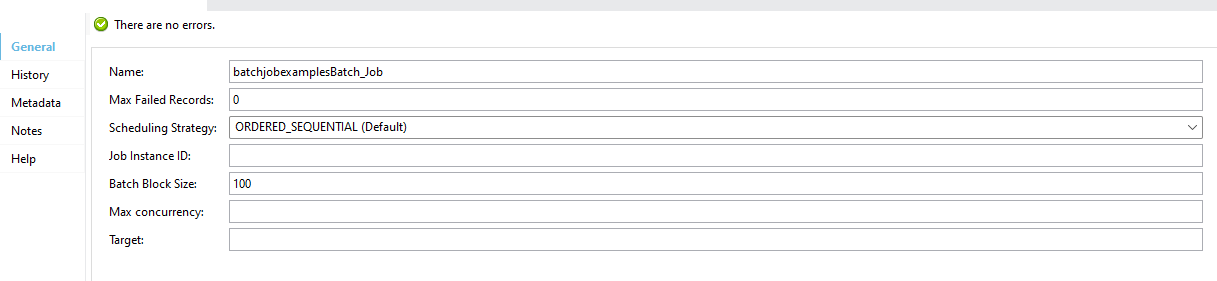
Configuration Parameters:
Name: Denotes the batch job name.
Max Failed Records: Defines the threshold for failed records before halting the batch job. By default, a value of 0 means halting upon a single failure. A value of -1 means the process won’t halt regardless of the number of failed records.
Scheduling Strategy: Determines batch job execution. Choices include:
ORDERED_SEQUENTIAL (default): Job instances run consecutively based on their timestamp.
ROUND_ROBIN: All available batch job instances execute using a round-robin algorithm.
Job Instance ID: Assigned to each batch job for processing.
Batch Block Size: Typically set to 100 by default. Defines the number of records assigned to each execution thread.
Phases of Batch Jobs
Each batch job contains three different phases:
1. Load and Dispatch: This is an implicit phase. It works behind the scenes. In this phase, Mule turns the serialized message payload into collection of records for processing in the batch steps.
2. Process: This is the mandatory phase of the batch. It can have one or more batch steps to asynchronously process the records.
3. On Complete: This is the optional phase of the batch. It provides the summary of the records processed and helps the developer to get an insight which record was successful and which one failed so that you can address the issue properly.
failedRecords, loadedRecords, processedRecords, successfulRecords, totalRecords
Batch Step
Each batch steps can contain related processor to work on individual records for any type of processing like enrichment, transformation or routing. This will help in segregating the processing logic
We can see two options
Accept Expression – expression which hold true for the processing records e.g. #[payload.age > 27]
Accept Policy – can hold only below predefined values
NO_FAILURES (Default) – Batch step processes only those records that succeeded to process in all preceding steps.
ONLY_FAILURES – Batch step processes only those records that failed to process in a preceding batch step.
ALL – Batch step processes all records, regardless of whether they failed to process in a preceding batch step.

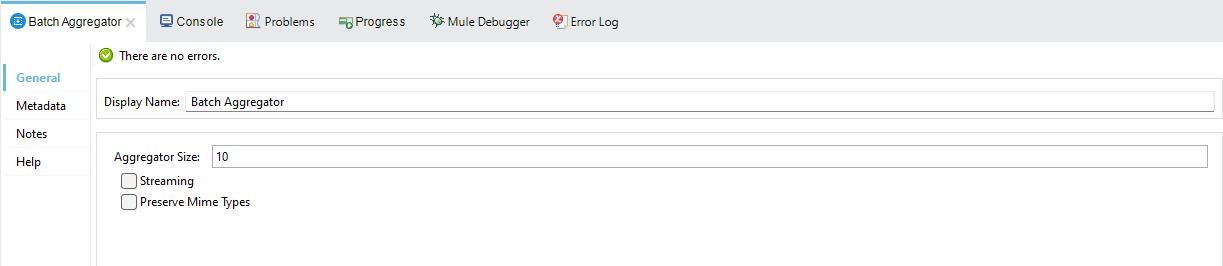
Batch Aggregator
As the name suggest can execute related processor on bulk records to increase the performance. In today’s time most of the target system e.g. Salesforce, Database, REST call accept collection of records for processing and sending individual records to target system can become a performance bottleneck so Batch Aggregator help by send bulk data to target system.
Size for Batch aggregator can be defined as below (both are mutually exclusive)
Aggregator size – Processing a fixed amount of records e.g. 10 records
Subscribe to my newsletter
Read articles from Nandinee Ramanathan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by