Monolith → Microservices
 Maulik Sompura
Maulik Sompura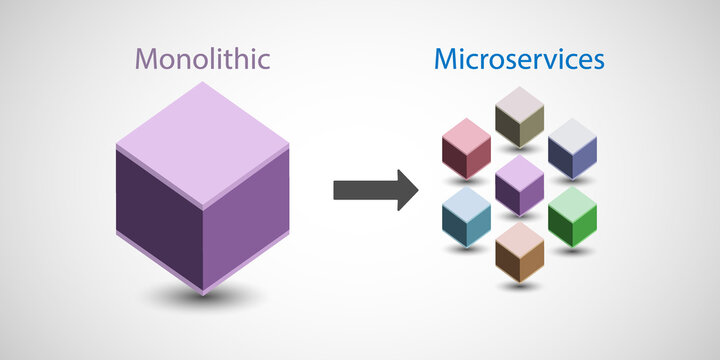
In the realm of software development, monolithic applications have long reigned supreme. Imagine a towering castle - all functionalities reside within a single codebase. But as kingdoms grow, so do their needs. Monoliths, while initially convenient, can become cumbersome to manage and scale.
The Monolithic Struggle
If you've ever worked on a monolithic backend system, you know the struggle. You've done your best to optimize the code and database, but it feels like there's only so much you can do before you hit a wall. You'd like to scale, but it's either too expensive to add more servers or too complex to rework the architecture. Various factors compound the issue, including the selection of databases, servers, and even aspects of the coding language.
We've encountered such scenarios where despite exhaustive optimisation efforts on both code and database fronts, the APIs continued to under-perform due to a colossal monolith handling all requests. With a deluge of concurrent requests, the system descended into chaos. Even with vertical or horizontal scaling and automated mechanisms in place, performance lagged as the request pool swelled. So, how do we resolve this predicament? The solution lies in decomposing the monolith into modular microservices, reassessing database choices, and leveraging distributed systems.
Microservices to the rescue
However, while the solution may seem straightforward—migrating code from a monolith to modular microservices or transitioning data from one database to another - it comes with its set of challenges.
For context, our backend stack comprised Node.js and Apollo GraphQL, with ArangoDB as the primary database and Redis serving as the in-memory cache. Early on, we adopted a serverless architecture with ECS, offering a semblance of relief. Notably, our APIs were consumed by a mobile application—an important consideration given the need to accommodate users who might not update the app or be part of staged rollouts.
At that juncture, we catered to around 15,000 users with approximately 1,000 Daily Active Users (DAU). Hence, any major downtime during the operation was simply not an option.
Challenges and Solutions
Let's delve into the challenges encountered and the solutions implemented, categorising them into two main points: database migration and code migration.
Database Migration
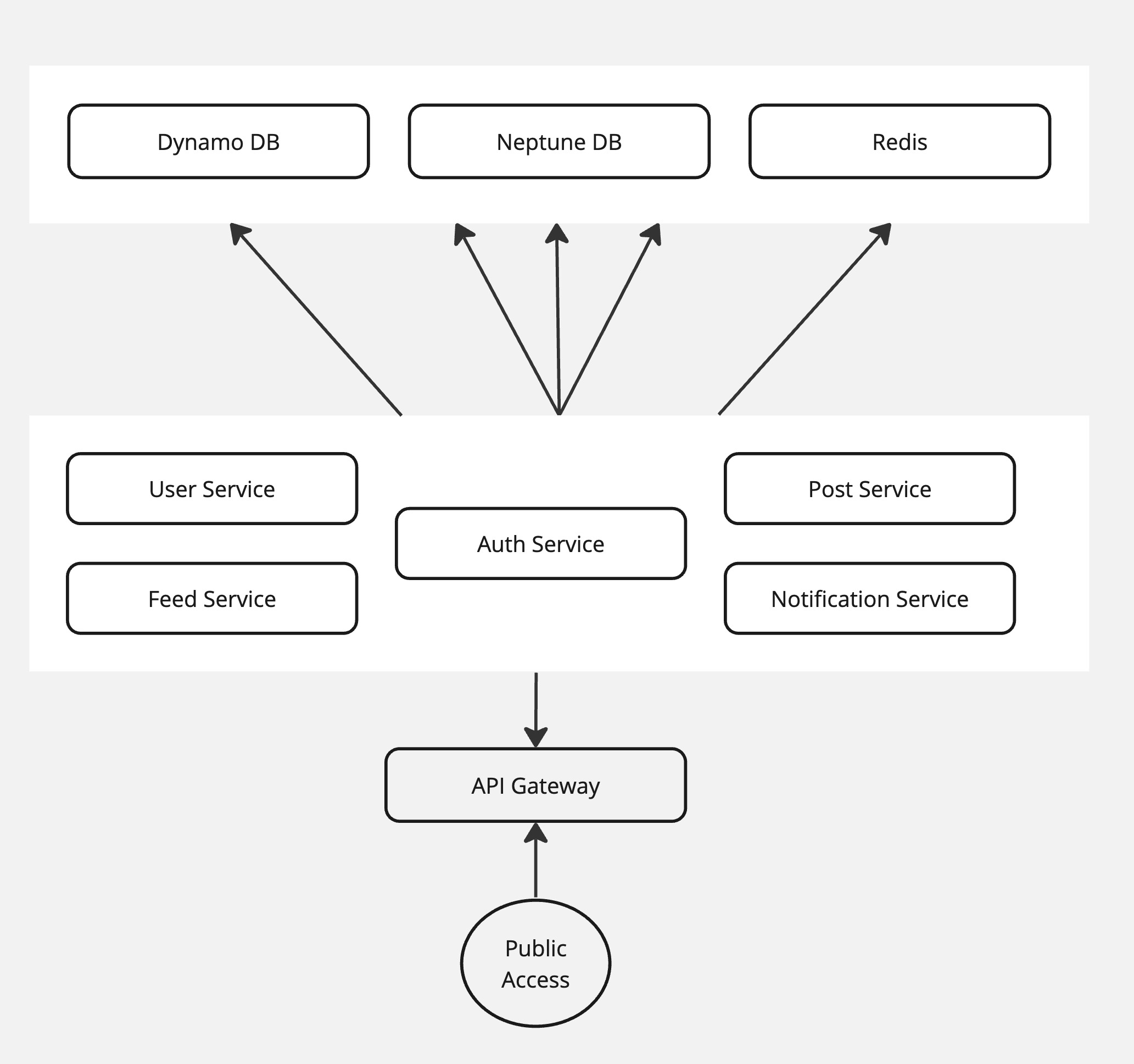
ArangoDB, our chosen database, primarily operates as a NoSQL graph database, excelling in object relations using graphs rather than merely functioning as a document database. However, the managed version which is better in performance, proved substantially pricier compared to alternatives like MongoDB and DynamoDB. Given our need for a cost-effective database with millisecond latency, we opted for DynamoDB as the primary database. We turned to AWS Neptune for graph database requirements while retaining Redis for in-memory caching.
Seeking to minimise downtime, we embarked on a strategy of behind-the-scenes changes to avoid disrupting active users. We began by creating tables/collections in the new database (DynamoDB) and developed an API-less service using Google Pub/Sub. This service triggered the copying of relevant data from the existing database to the new one, with triggers activated upon API calls. This ensured seamless data migration without downtime. It's worth noting that we still needed to switch to the new database; the data copying process was underway.
Subsequently, new user data would be stored in DynamoDB/NeptuneDB, while existing user data necessitated updating monolithic APIs to point to the new database. If data was absent in the new DB, it would be fetched from the old one, with an event triggered to clone the data into the new DB. Concurrently, the migration journey for new users would transition to microservices.
Once the DAU and MAU numbers aligned with the user count in the new database, we scripted the cloning of remaining data, primarily for inactive users during the migration phase. This involved careful consideration of script execution and database connection timeouts, batch insertion limits, and ensuring data integrity. Post-script execution and microservices changes were finalised.
Code Migration

Simultaneously with database migration, we initiated code migration from monolith to microservices, adopting a module-by-module approach. Our code was segmented into services such as authentication, user management, post management, notifications, feed management and media management. Beginning with the authentication service, we transitioned pertinent APIs and integrated them into our app. Additionally, AWS API Gateway facilitated service navigation and traffic handling.
Continuous Delivery and Language Flexibility
Throughout this process, we implemented a version-checking mechanism within the app, ensuring users received the latest updates seamlessly. Furthermore, our architecture embraced polyglot programming – different services, like media management, utilized languages best suited for their tasks.
This architecture is built in a way that some of the services, such as media management, were implemented in GO lang for its minimal latency and high CPU power. This design allows for flexibility in using different languages for various use cases and services.
Scaling for Success: Horizontal Scaling and Global Reach
Imagine a global marketing campaign. With microservices, you can anticipate increased usage by horizontally scaling specific services (distributing servers across locations). This ensures a smooth user experience regardless of location.
Takeaway
In summary, transitioning from a monolithic to a microservices architecture, alongside database migration, posed multifaceted challenges. However, by meticulously strategizing and implementing solutions, we successfully navigated these hurdles, culminating in a more scalable and resilient backend infrastructure with close to zero downtime for the active users.

Bonus Fact
The social media giant Twitter (now X) originally began as a single monolithic codebase. However, as the user base exploded, Twitter faced scalability challenges. To tackle this, they famously implemented a "hashtag architecture" – a precursor to microservices – where different parts of the application, like feed management and search, became independent services. This shift in architecture allowed Twitter to keep up with its massive user growth!
Credits
This post wouldn't be possible without the guidance and mentorship of @thestartupdev at the time of the challenges.
Subscribe to my newsletter
Read articles from Maulik Sompura directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Maulik Sompura
Maulik Sompura
Hello, I’m Maulik Sompura, a fullstack Javascript developer. I have a passion for building web applications using Node JS, React, Vue, and various databases and APIs. I can implement business logic, RESTful services, and responsive UIs from Figma designs. I am proficient in GraphQL and Express along with Infrastructure management. I have had the opportunity to work with a variety of technologies including Node JS, React JS, Vue JS, Typescript, Firebase, AWS (various services), Stripe, Cloudinary, PHP, Angular JS, ElectronJS, and ElasticSearch. I am passionate about learning new things and sharing my knowledge with others. I write about Javascript, web development, and other topics on my blog. You can also find me on Linkedin, Github, and Skype. Feel free to reach out to me if you have any questions or feedback. Thanks for reading!