Case study : Github outage
 Rahul Poonia
Rahul Poonia
Github, the most popular software development collaborative tool and hosting service, had an outage of about couple of hours back in September, 2012. Github has had quite a few outages since then. But this incident in particular caught my attention considering the reasons for such an outage. We will try to dissect this incident, understand basics associated with it and what are the lessons for future!
What transpired?
The official website of github reports that github had undergone maintenance that replaced "aging pair of DRBD-backed MySQL servers with a 3-node cluster". These nodes were assigned roles viz either "Active" or "Standby". The active role denotes that replica will be used for write and read operations making it a master/leader replica while standby role will be used just for read operations making it a slave/follower replica. So they were essentially following leader-follower replication model. Further they had a system called "Percona Replication Manager" in place that would assign "active" or "standby" role to these nodes based on some healthcheck parameters. Implying they had failover mechanisms in place as well.
Now, about a month later, they undertook some migration task that put heavy load on their database nodes, something not seen before. So much so, it caused Percona Replication Manager’s health checks to fail on the master node and triggering failover. As a result it assigned the active role to the other node and stopping the previous master node. However, this new master node did not perform efficiently in the heavy load scenario as it had cold InnoDB buffer pool and thus poor caching mechanism in place. As a result this PR Manager's healh check failed on this node as well, triggering failover again and declaring the previous node as master again!
The team had to manually intervene to make some confiuration changes. Eventually, a node was elected to be a master that was not upto date and had replication lag! It took 7 minutes for the team to realise that the latest master node does not have data in sync. Ultimately they brought the whole production database down leading to outage.
So, there is a lot to unpack here. What is replication? What is replication lag? Why do we keep doing a failover? Lets understand these terms first before going further with the incident.
What is replication ?
Database replication simply means duplicating the database across multiple nodes which may be present in different datacenter. The idea is to keep more than one copy of the database all the time. Each node that contains a copy of the database is called Replica. The rationale is to have a fallback mechanism in case of database crashes and faster read queries from multiple distributed instances. There are different models of replication, the one used here is leader-follower. In this model of replication there are two types of replicas.
Leader(Master) : All writes happen on this replica. Just one in number.
Follower(Slave) : Only reads are allowed on these replicas from client application.
So to make database consistent we need to ensure that leader replica itself handles writes to rest of the replicas.
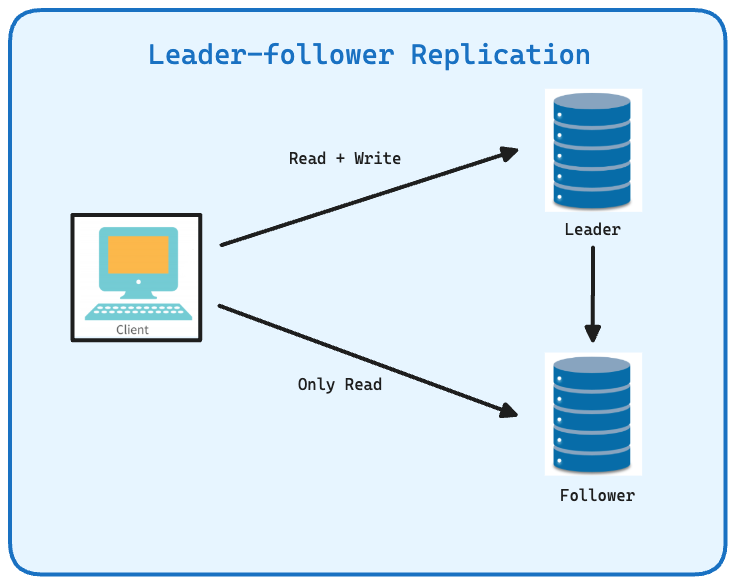
To read about all the different types of replication models see this.
Now lets understand the term 'replication lag'.
What is Replication Lag?
Replication lag is the delay between when a change is made on a primary replica(leader or master) and when that change is reflected on a secondary replica (follower or slave) database. In other words, it's the time difference between the occurrence of a transaction on the primary server and the point at which that transaction is applied on the replica server.
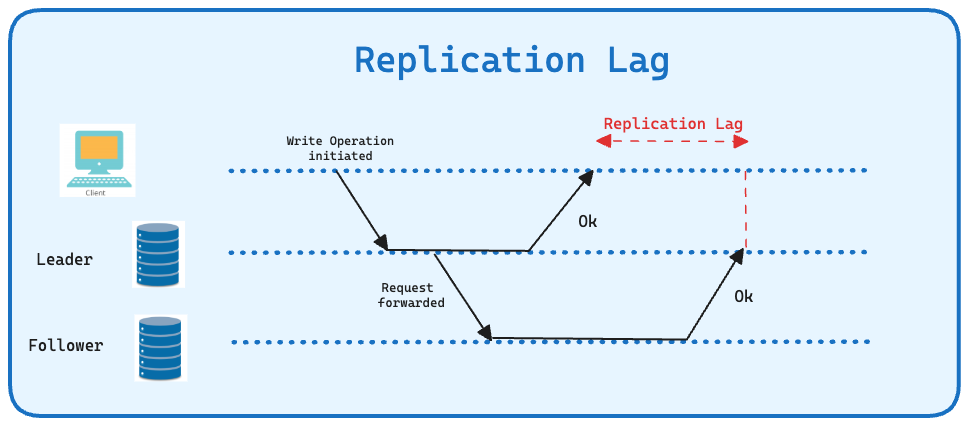
Not only this, there are times when followers can permanently fall behind leader replica. In that scenario follower replica becomes inconsistent with leader replica. And subsequent writes on such a replica may cause conflicts.
This is what happened in case of Github.
What is failover?
In any database system, howsoever reliable it might be, there is always a possibility of database replica crashing. This is exactly the reason why we have multiple replicas in the first place. When the "follower" replica crashes, it is not much of an issue. We can spin-up a new replica or if the previous replica is functional again, we can make it "catchup" with leader replica.
However when the crashed replica is "leader" it is not as easy as it seems. The process of resolving this situation is called failover. It consists of following steps:
One of the followers need to be promoted as leader : Need a way to make that decision
Application needs to be configured to make writes to this new leader replica.
Other followers need to start consuming messages from this new leader.
The failover process is fraught with many issues. Here are the important ones:
How to decide that leader replica is dead? If we do it late, we might lose data. If we do it too early, there may be frequent failovers and performance degradation
Who should be the new leader?
What if the followers are not in sync and have replication lag? Should we just discard that data?
Sometimes two followers might think they are the leaders, leading to a situation called split-brain. It will lead to conflict in database.
You will observe that these are exactly the questions that Github outage posed. Lets get back to the case study to understand consequences of the incident a little better.
What were the consequences?
So, picking up the thread from where we left. For 7 minutes, Github database chose a leader that was reported to face replication lag. So for those seven minutes, new data was written in this newly declared leader replica. Incidentally, the way Github's application was architectured, a Redis instance was cross-referrencing the auto incrementally generated primary id of MySql database. This led to a situation where wrong data was referred to as data was not in sync. As a result 16 private repositories were made available to accounts that did not have access!
Lessons for us!
Analysing the whole incident in the hindsight, gives us a good peek into where Github went wrong and what are the lessons for the future for us!
In this incident failovers of 'active' nodes happened when they should not have. The configuration to determine health of nodes is extremely critical. It should not be too lenient.
Follower to become the new leader in case of failover was not selected properly. One of the ways suggested to deal with this issue is to pick the one that is most upto date with now failed master node.
Replication lag was not handled properly. We need proper monitoring systems in place to identify and alert when there is substantial lag. We need to run background jobs to keep database in sync, in case followers have fallen behind. Most databases use asynchronous way of replication. However semi-synchronous where a single follower is always updated synchronously should be explored if the there is no significant performance degradation.
InnoDB buffer pool was cold. Keeping the followers's databases buffer pool warmed for better caching performance is another key takeaway.
Conclusion
This September, 2012 Github outage issue is a classic example of what can go wrong even with the best of intentions. Replicating database and keeping an automated system of failover are all designed with the objectives of ensuring high availability in applications. But challenge comes in executing them in production running real world applications.
Nevertheless, together, database replication and failover mechanisms significantly improve system availability by providing redundancy and enabling quick recovery from failures. Any unfavourable incident or hiccup should be seen as a stepping stone for a more informed and educated future!
If you liked this blog, don't forget to give it a like. Also, follow my blog and subscribe to my newsletter. I share content related to software development and scalable application systems regularly on Twitter as well.
Do reach out to me!!
Subscribe to my newsletter
Read articles from Rahul Poonia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by