Version control in database: EdgeDB's Pioneering Branching System
 Md Sabbir Rahman
Md Sabbir RahmanTable of contents

Hello everyone 😎. Hope everyone is fine. This is the second blog of my EdgeDB series. In this blog I will try to discuss about a new, exclusive and exciting feature of EdgeDB which will allow you to use branching in the database as you use in you codebase. This blog mainly divided into two sections. In the first part I will try to discuss how database branching can helps us and in the last part about a real world implementation
I think you already know about version controlling system. You surely know how maintaining different branch in our code helps us a lot and become the life saver for software developer. It gives us the freedom and courage to play with our code and also collaborate efficiently between our teams.
But Imagine a world you have the power to use branching system in your database like you use in code . This will make a life lot easier for you and you will feel like to have superpower in hand.
Till some days ago that was very tough to achieve. But not anymore, with the launching of EdgeDB 5.0 it introduces branching system in Database. This is the start of a new era in the terms of database. In this blog I will try to give you some basic idea about EdgeDB branching .
But first things first let’s discuss something about why on earth you need branching in database.
Why Database Branching can be important
There are basically two things you need to keep in your mind
Firstly, schema change and migration. When we are building a software we may need to redesign the database schema, adding or changing fields, constraints, relation etc. We may need to test it separately with isolation. This can be solved with multiple instances of database.
Managing and maintaining multiple instances is not so easy. Sometimes it needs to be setup from zero again and again. More instances means more resources and more cost.
Secondly, the data it self. The more the number of instances grow the more it will be tough to handle data associated with. Different instances may contain different data. Repopulating existing data for new instances is also troublesome.
There are so many examples, where you can find that code is working fine on your local machine but not when live. You may not able to find the problem or even may able to reproduce the bug. The main cause of this thing may be related to data .
I personally experienced this kind of issues multiple times in my work experience.
Also there are some circumstances, where you may have permission boundary with production data. Then you may need to prepare and maintain data close to it to ensure that your solution will also work for production data.
Most of the times we need to handle separate data for production, staging, qa and dev server. Even sometimes feature may have the need to test with separate and different kinds of data.
Maintain branching in database can be light of hope for both schema and data related difficulties. It has high potential of saving both time and money
Ok we already may have some basic idea of why branching in database is very interesting. Now let’s see some demonstration. This will work for EdgeDB version 5.0 or later and you need to have installed both EdgeDB and EdgeDB cli on your machine
I will show the demo mainly for EdgeDB local but you can work with EdgeDB cloud also
Realworld database branching example with EdgeDB
Initialize an EdgeDB project
To continue from this you want to download EdgeDB create an EdgeDB project first. To download EdgeDB you can visit this link . Next you need to install EdgeDB cli to continue working with branching. You can install EdgeDB cli from this .
Then if edgedb and EdgeDB CLI is installed successfully you can easily create an EdgeDB project by writing edgedb project init on the root of your folder where you want to work with EdgeDB. This may look like this
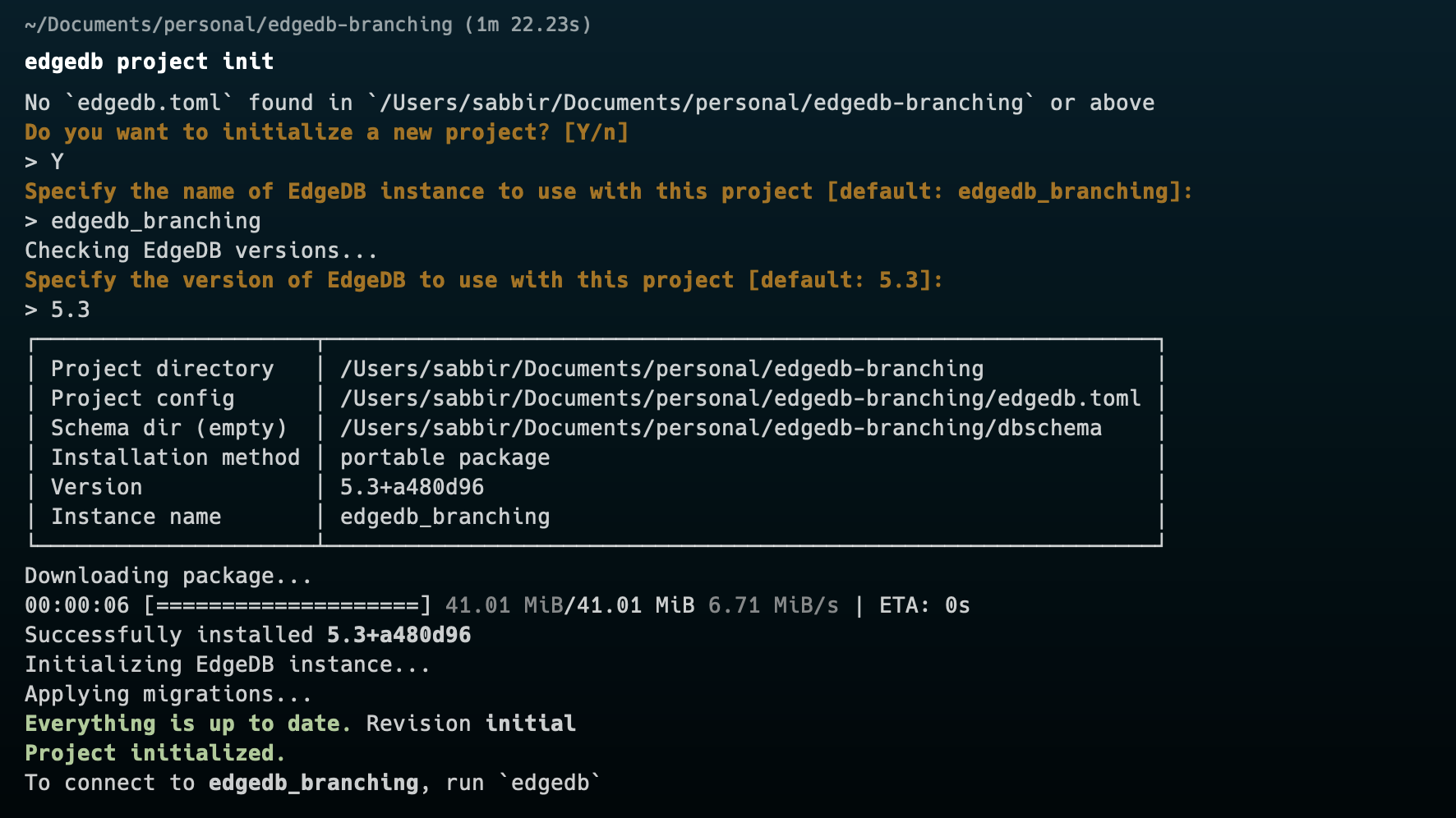
Our project is initialized. Now it is time to get introduce with EdgeDB branching. By default EdgeDB will create a main branch on the project
Introduce with EdgeDB branching
First lets know about our weapon in the arsenal. Let's know the available commands till now for EdgeDB branching. To get idea about the available commands of EdgeDB you can just write edgedb branch --help . It will show the all available commands
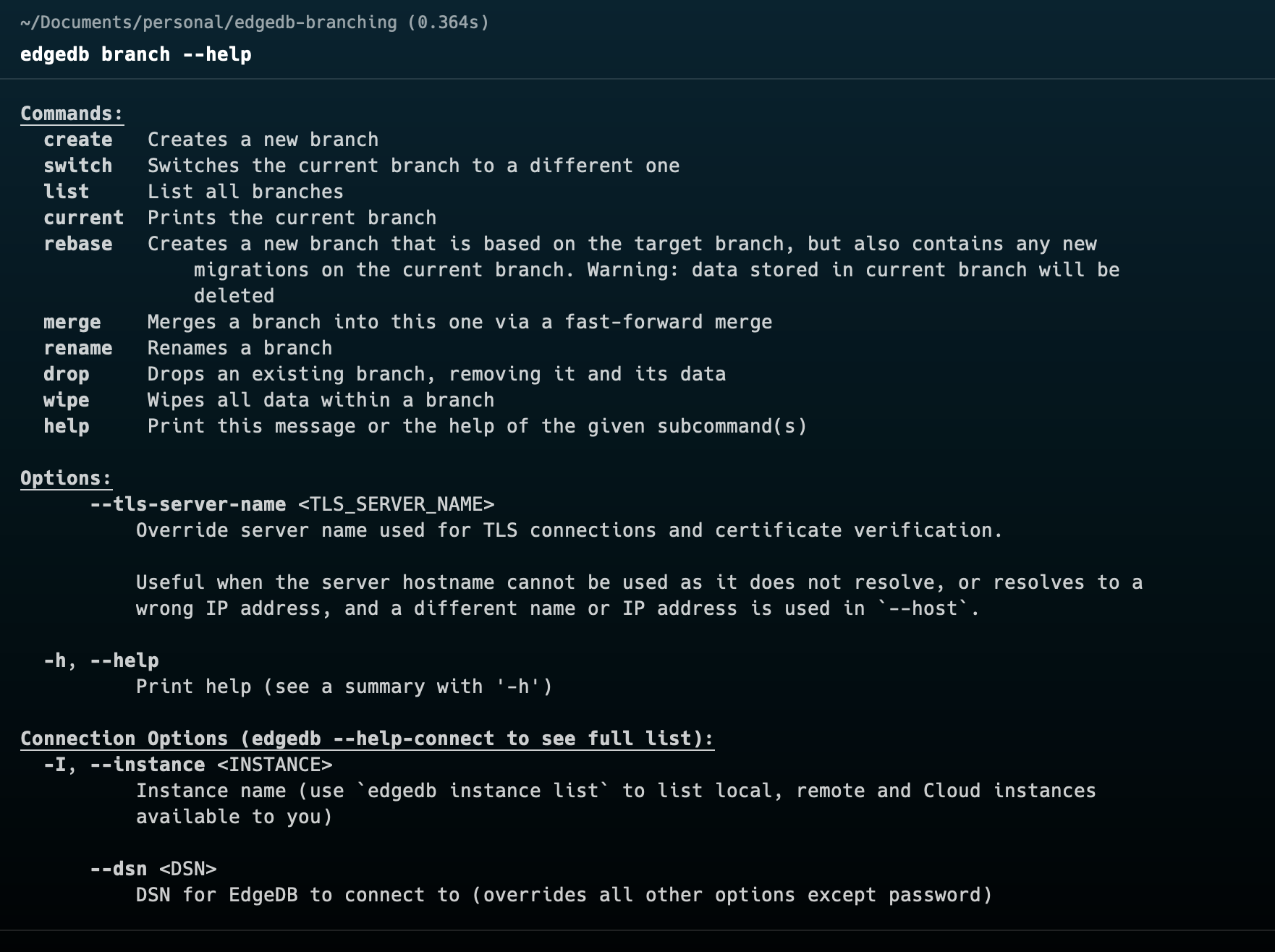
Now we know about the available commands. Now let's start implementing a real world example. We will think about a simple e-commerce based example
Initialize the Schema
Let's think about a simple product order system. There are many product and User will simply Order products. EdgeDB manage their schema with Schema Definition Language which has the .esdl extension. Then EdgeDB can generate migration file from this with feature of manual modification. For initial phase the schema may look like this
module default {
type User {
required property name -> str;
required property email -> str {
constraint exclusive;
constraint max_len_value(100);
}
multi link orders -> Order;
}
type Product {
required property name -> str;
required property price -> float64;
multi link orders -> Order;
}
type Order {
required property quantity -> int64;
required link user -> User;
required link product -> Product;
property total -> float64 {
using (SELECT .product.price * .quantity);
}
}
}
We can create it in the existing default.esdl file or can create an .esdl file of our own. After creating we must create and apply migration with edgedb migration create and edgedb migration apply .
Populating initial data
Now we have schema to work on. So we can put some initial data to work with. You can put data from UI manually or with EdgeDB editor. You can open EdgeDB editor by just writing edgedb or by opening ui by edgedb ui
# -- Sample 1
INSERT User {
name := 'John Doe',
email := 'john.doe@example.com'
};
INSERT Product {
name := 'Product 1',
price := 99.99
};
WITH U := (SELECT User FILTER .email = 'john.doe@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 1'))
INSERT Order {
quantity := 2,
user := U,
product := P
};
# -- Sample 2
INSERT User {
name := 'Jane Smith',
email := 'jane.smith@example.com'
};
INSERT Product {
name := 'Product 2',
price := 49.99
};
WITH U := (SELECT User FILTER .email = 'jane.smith@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 2'))
INSERT Order {
quantity := 1,
user := U,
product := P
};
# -- Sample 3
INSERT User {
name := 'Alice Johnson',
email := 'alice.johnson@example.com'
};
INSERT Product {
name := 'Product 3',
price := 19.99
};
WITH U := (SELECT User FILTER .email = 'alice.johnson@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 3'))
INSERT Order {
quantity := 3,
user := U,
product := P
};
# -- Sample 4
WITH U := (SELECT User FILTER .email = 'john.doe@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 3'))
INSERT Order {
quantity := 1,
user := U,
product := P
};
# -- Sample 5
WITH U := (SELECT User FILTER .email = 'alice.johnson@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 1'))
INSERT Order {
quantity := 2,
user := U,
product := P
};
You may not understand the details of edgeql but don't worry you can just copy paste the above section for now
Create a new branch
For example, there is a new requirement in the software. We need to keep salesman details also.Now we will start to use the real feature of EdgeDB branching. We will now create a feature branch. First create a feature for your codebase. Then create branch for EdgeDB. To create branch in EdgeDB
edgedb branch create [options] name
By default it will create a database branch with the existing schema but we can create an empty branch or a branch with both existing schema and data. You can check more details from here
In our example we want to create a new branch with existing data and checkout to the branch. So we just write below commands in the root of the project.
NB: -> sign means the output line
edgedb branch create feature-salesman --copy-data
-> Creating branch 'feature-salesman'...
-> OK: CREATE BRANCH
edgedb branch switch feature-salesman
-> Switching from 'main' to 'feature-salesman'
edgedb branch current
-> The current branch is 'feature-salesman'
Now we create a new branch names feature-salesman . Now lets change our schema . Now schema may look like this
module default {
type User {
required property name -> str;
required property email -> str {
constraint exclusive;
constraint max_len_value(100);
}
multi link orders -> Order;
}
type Product {
required property name -> str;
required property price -> float64;
multi link orders -> Order;
}
type Salesman {
required property name -> str;
multi link orders -> Order;
}
type Order {
required property quantity -> int64;
required link user -> User;
required link product -> Product;
optional link salesman -> Salesman;
property total -> float64 {
using (SELECT .product.price * .quantity);
}
}
}
Now creating and applying the migration with edgedb migration create and edgedb-migration-apply . After that, we will input some data for ease of testing
# -- Sample 1
INSERT Salesman {
name := 'Salesman 1'
};
WITH U := (SELECT User FILTER .email = 'john.doe@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 1')),
S := assert_single((SELECT Salesman FILTER .name = 'Salesman 1'))
INSERT Order {
quantity := 2,
user := U,
product := P,
salesman := S
};
# -- Sample 2
INSERT Salesman {
name := 'Salesman 2'
};
WITH U := (SELECT User FILTER .email = 'jane.smith@example.com'),
P := assert_single((SELECT Product FILTER .name = 'Product 2')),
S := assert_single((SELECT Salesman FILTER .name = 'Salesman 2'))
INSERT Order {
quantity := 1,
user := U,
product := P,
salesman := S
};
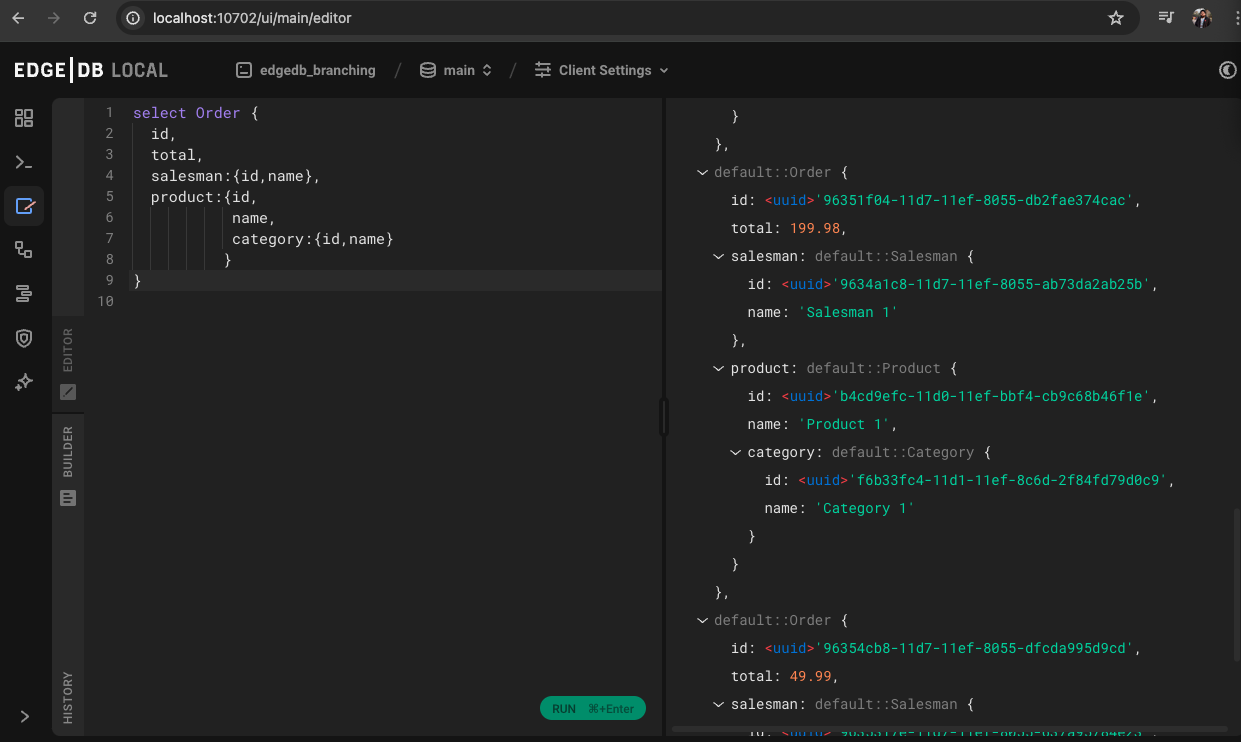
Now lets see if new data is added and if the existing data from branch main is present or not. Just writing a simple query to check . You can do it either with EdgeDB editor or from UI
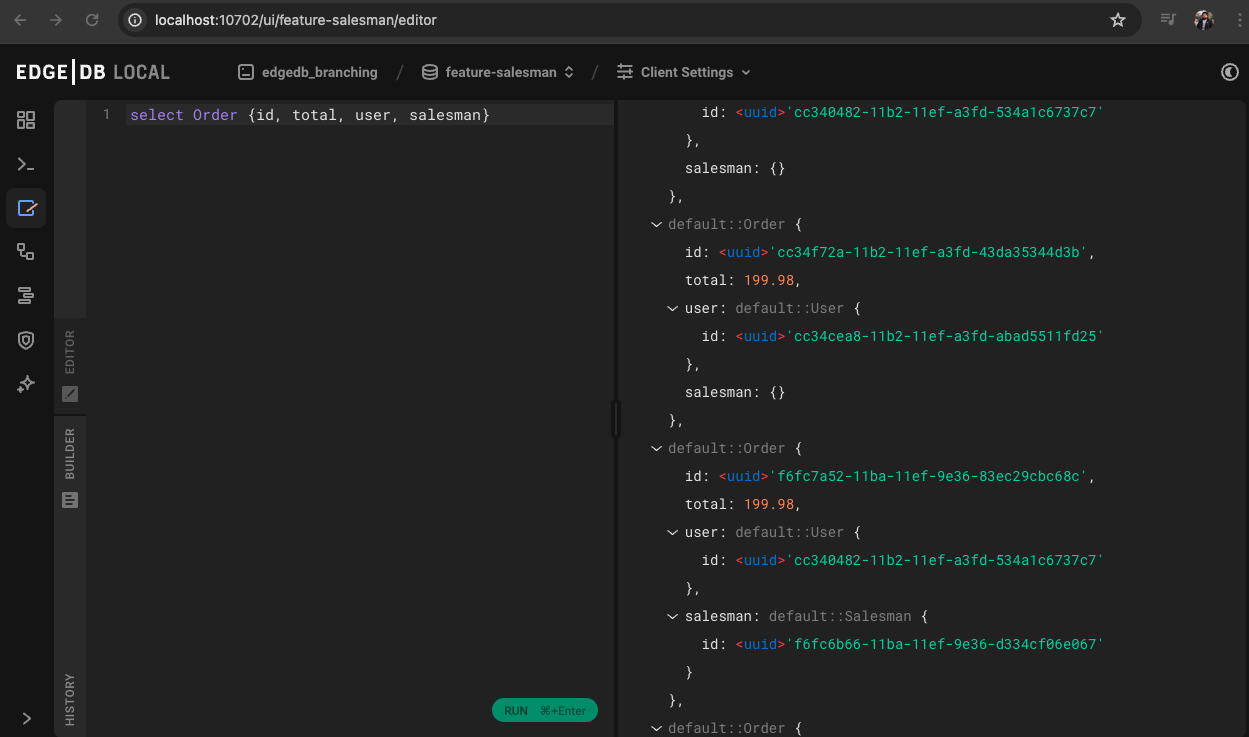
We can see all the data are present
You are an awesome developer you successfully added the salesman feature. But meanwhile other developer already added a new feature which is added product category to the system. The product category feature is already in the main branch. For example if you visit the main branch of database Product 1 has the Category 1 now and Order data of Product 1 looks like this
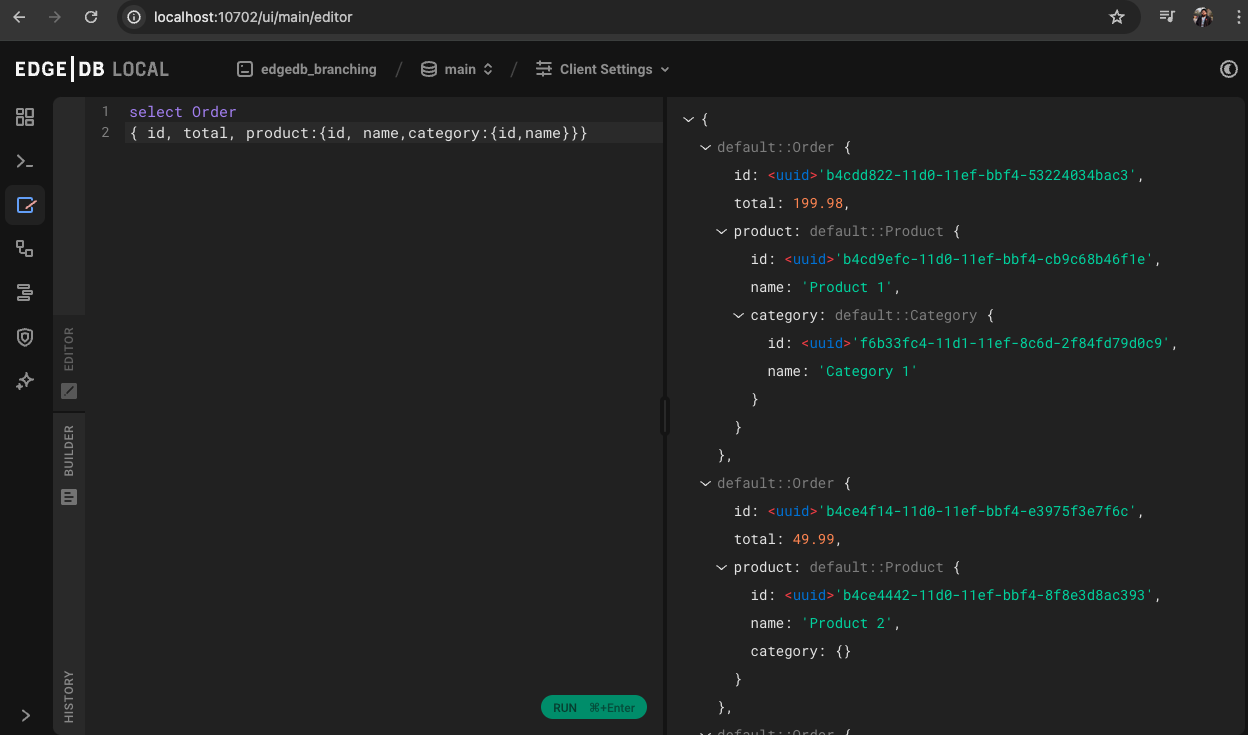
You can see Product 1 has the Category 1 now. You know your task now you need to merge your salesman data to this
But before merging the database branches you have to keep an important thing in mind you need to do Rebasing Before Merging
Rebasing Before Merging
When we are merging a plain code feature into the main code base, our github will handle code changes and merge conflict. But, databases are different— schema changes and migration order greatly influence the final state. To ensure the consistency of our schema changes we require rebasing the feature branch on top of the main branch before merging, aligning all migrations in the correct order.
We have to be in the feature branch for both code and database. Then firstly we need to rebase the code with git rebase main . Then we need to rebase the database by edgedb branch rebase main . The output may look like this
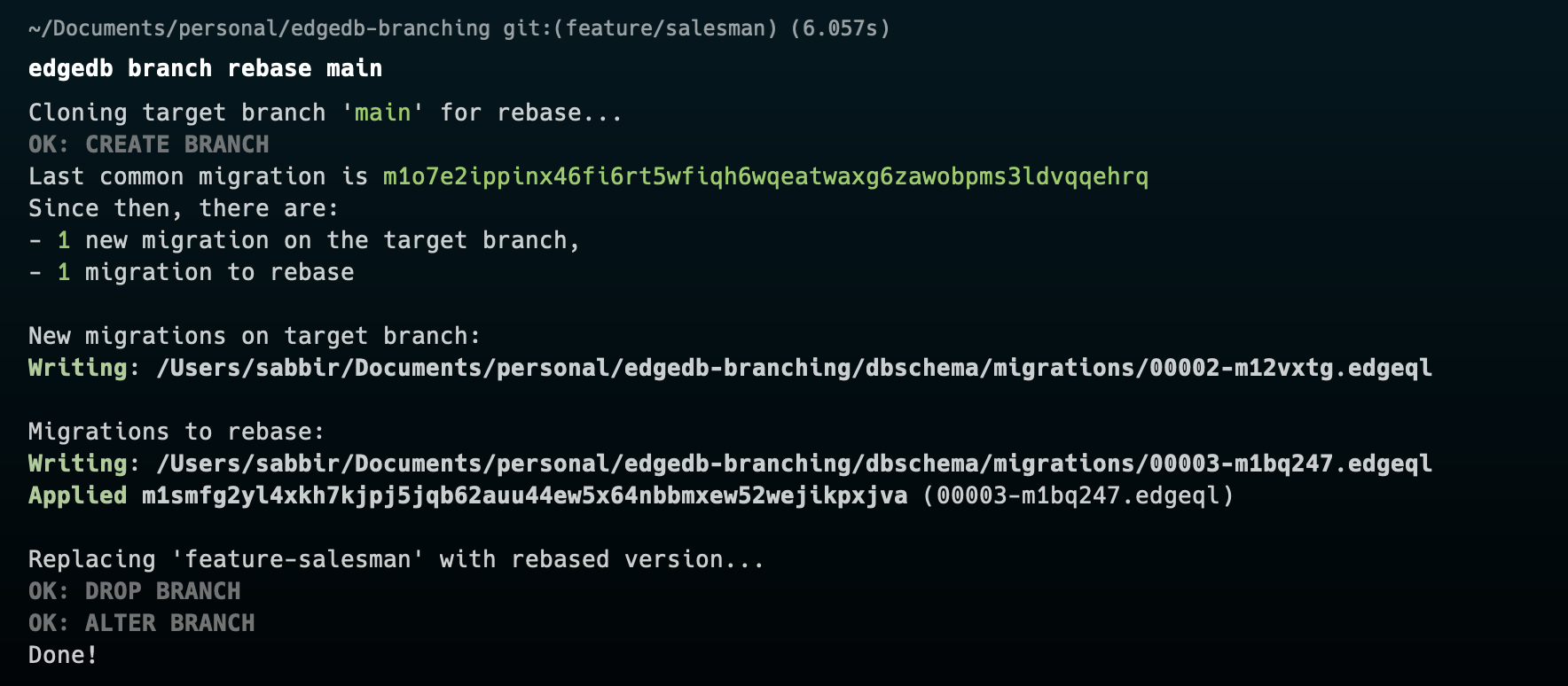
The final step the merging
Now this the final step . We need to ensure that we are on the main branch for both code and database branch. Then we need to first to merge the feature code to main by git merge feature_branch_name . Delete the old migration file that is created duplicately as the new migration. You can also check it by finding having same parent as migration. So delete the duplicate migration file and then we need to merge the database branch by edgedb branch merge feature_branch_name . Your database branch is merged. For test it you can add the data in main database branch as you add to feature branch before to test. You may have the result look like this
Branching in EdgeDB cloud
We can follow the same process as we have here for the local EdgeDB. Moreover With the EdgeDB + Vercel integration, a new database branch is automatically created in your EdgeDB Cloud instance when you created a new branch in Github, allowing you to test new features in isolation without affecting the main database schema. For more you can look here
Summary
We did many things till now let’s summarize this . Firstly we will follow the same version control technique as we follow for our codebase. We have to keep in mind that branching for code and branching for database will be operated separately. Then to start working we can create a separate database branch with the existing data, schema or both. After that we will make our database changes and apply migrations. Then we will ensure that we have the latest change of the branch to whom we need to merge out new feature branch. In our case it is main. Then we need to rebase main from our feature branch. Rebase is necessary here because database migration changes history is different than codebase. Migration changes history heavily affect the final migration state. After rebasing we will merge the feature branch from main and the magic happens. You can check out all the code from this GitHub repo .
That’s all for this blog. Thank for reading till this if you do so 😊. EdgeDB is comparatively new in the market. It has many fascinating feature like branching. I will try to continue writing on this more. You can write your comments or doubts here I will love to discuss it together. Go with the Reference if you need to go more deep. Till next blog. Have a good day, Bye.
References:
Subscribe to my newsletter
Read articles from Md Sabbir Rahman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Md Sabbir Rahman
Md Sabbir Rahman
Coding means freedom