Solving a Leetcode problem daily — Day 12 | 347. Top K frequent elements
 Subhradeep Saha
Subhradeep Saha
Here is the Leetcode problem link —347. Top K frequent elements
Problem Statement
Given an integer array nums and an integer k, return thekmost frequent elements. You may return the answer in any order.
Example 1:
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]
Example 2:
Input: nums = [1], k = 1
Output: [1]
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^4kis in the range[1, the number of unique elements in the array].It is guaranteed that the answer is unique.
High Level Approach
The goal is to determine the frequency of each element in the input array and return the top k elements with the highest frequencies.
First, we store the frequency of each element in a map. Next, we use a min-heap to store the {frequency, element} pairs from the map. We then iterate over each entry in the map:
If the heap size is less than k, we create a
{frequency, element}pair and push it to the heap.If the heap size is ≥ k, and the frequency of the element at the top of the heap is less than the current element’s frequency, we remove the lower frequency element and insert the higher frequency element into the heap.
The top of the min-heap will always contain the element with the lowest frequency among those in the heap, making it safe to remove when a higher frequency element is encountered. This ensures that, in the end, the heap contains the top k elements with the highest frequencies, which can then be returned as the answer.
Code Implementation in C++
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> count;
for(int& x: nums) {
count[x]++;
}
priority_queue<pair<int, int>, vector<pair<int, int>>,
greater<pair<int, int>> > pq;
for(auto& it: count) {
if(pq.size() < k) {
pq.push({it.second, it.first});
}
else {
if(pq.top().first < it.second) {
pq.pop();
pq.push({it.second, it.first});
}
}
}
vector<int> ans;
while(!pq.empty()) {
ans.push_back(pq.top().second);
pq.pop();
}
return ans;
}
};
Detailed Code Breakdown:
Frequency Counting:
We create an unordered_map named
count. This map will store each element in the arraynumsas the key and its frequency (the number of times it appears) as the value.We iterate through the
numsarray using a range-based for loop, incrementing the corresponding element's count in thecountmap.
Priority Queue with Custom Comparison:
We declare a
priority_queuenamedpq. This queue will hold pairs of(frequency, element)values.The
greater<pair<int, int>>comparison function ensures the priority queue prioritizes elements with lower frequencies which is being stored as the first element of the pair (lower frequency value will be at the top of the queue).
Populating the Priority Queue:
We iterate through the
countmap using a range-based for loop.If the
pqsize is less thank(we haven't reached the desired number of elements yet), we directly add the(frequency, element)pair to the queue.If the
pqis already full and the current element's frequency is higher than the lowest frequency element in the queue:
\=> We remove the element with the lowest frequency using pq.pop().
\=> We add the current element with its higher frequency to the queue using pq.push().
Extracting Frequent Elements:
We create a vector named
ansto store the final result (thekmost frequent elements).We iterate through the
pqwhile it's not empty. For each iteration:
\=> We extract the element (the second value in the pair) from the priority queue using pq.top().second and add it to the ans vector.
\=> We remove the top from the queue using pq.pop().
Returning the Result:
The function returns the ans vector, which contains the k most frequent elements in the array.
Code Dry Run with Test Case:
Let’s consider the test case nums = [1,1,1,2,2,3], k = 2:
Frequency Counting:
The counter map is built as: count = {1: 3, 2: 2, 3: 1}
Priority Queue Population:
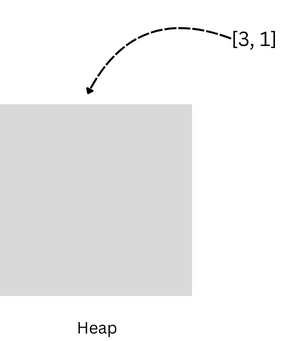
Iteration 1: Adding (3, 1)

Element: 1 (frequency: 3)
Since the heap is initially empty (
pq.size() = 0 < kis true where k = 2), we directly add the(frequency, element)pair, which is(3, 1), to the priority queue.
Iteration 2: Adding (2, 2)

Element: 2 (frequency: 2)
The queue now has one element, and we need to consider two elements (
pq.size() < kis still true).The new element (2) has a frequency of 2, which is higher than the current lowest frequency (3) in the queue. This means element 2 appears less frequently than element 1.
Since the priority queue prioritizes lower frequencies, the new element (2, 2) is added directly to the heap.
Heap State: The heap now becomes
[(2, 2), (3, 1)]. The element (2, 2) remains at the root because it has the lowest frequency(2)
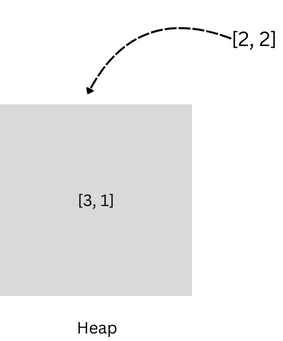
Iteration 3: Adding (1, 3)

Element: 3 (frequency: 1)
The queue now has two elements, and
kis still 2.The new element (3) has a frequency of 1, which is not greater than the frequency(2) of the heap’s top element(2).
So we don't modify the queue and continue, ending the iteration over the counter map.
Heap State: The heap remains unchanged:
[(2, 2), (3, 1)]. The element (3, 1) stays at the root as it maintains the lowest frequency.
Extracting Frequent Elements:
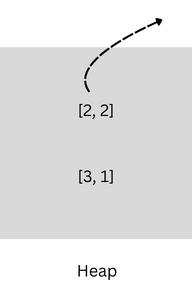
Heap state:
[(2, 2), (3, 1)]— so we first push 2 to the ans vectorpop (
2, 2)from the heap
3. get the heap’s top element which is 1 and push it to the ans vector.
4. pop the top element from the heap
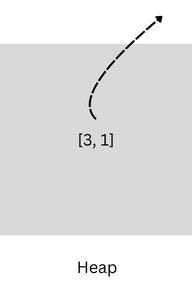
5. since the heap is empty now:
the while loop is terminated and ans = {2, 1} is returned as the final output.
Note: the order of elements in the output doesn’t matter as mentioned in the problem.
Time and Space Complexity Analysis
The time and space complexity of the provided solution for finding the k most frequent elements can be analyzed as follows:
Time Complexity:
O(n log k): This is the dominant factor in the overall time complexity.
Iterating through the array: We iterate through the input array nums using a for loop. In the worst case, this loop iterates n times (where n is the number of elements in the array).
Priority Queue Operations:
Adding elements to the priority queue (
pq.push()): The time complexity of adding an element to a min-heap is typically logarithmic, around O(log k) in most implementations. In our case, we potentially add elements up toktimes (depending on the number of unique elements and their frequencies).Removing elements from the priority queue (
pq.pop()): Similar to adding, removing an element from a min-heap is also O(log k). We might perform this operation up toktimes during the population stage.Since the priority queue operations (
pushandpop) involve logarithmic time complexity and are potentially repeated up toktimes, the overall time complexity is dominated by O(n log k).
Space Complexity:
O(n): This is primarily due to the usage of the hash map count.
The hash map
countstores each element in the array as the key and its frequency as the value. In the worst case, the hash map can potentially store all unique elements from the input array, leading to a space complexity of O(n).The priority queue
pqitself stores a maximum ofkelements (thekmost frequent elements). While this contributes to space usage, it's typically considered negligible compared to the potentially largercounthash map, especially whenkis a relatively small value compared ton.
Real-World Applications
Customer Analysis and Recommendation Systems: Online retail stores analyze customer purchase history to identify frequently bought items together. This information helps recommend complementary products, personalize promotions, and optimize product placement for better sales (e.g., suggesting frequently purchased groceries alongside main dishes).
Social Media and Trending Topics: Social media platforms like Twitter utilize algorithms to identify trending topics and hashtags in real-time. By analyzing the frequency of mentions and retweets, they can surface trending conversations and keep users engaged with the latest discussions.
Network Security and Intrusion Detection Systems (IDS): Network security systems monitor network traffic for suspicious activity. Identifying frequently occurring IP addresses attempting to access unauthorized resources or ports can be a red flag for potential attacks. By finding these frequent occurrences, security systems can trigger alerts and take preventive measures.
Conclusion
By employing a hash map for frequency counting and a priority queue with a custom comparison function, we efficiently identified the k most frequent elements in an array. This approach highlights the power of data structures for solving common data analysis problems in C++.
References
https://www.ibm.com/docs/SSNN4U_1.0.0/c_fan_rpt_customer_behavior_db.html
https://www.technologyreview.com/author/mit-technology-review-insights/
https://www.fortinet.com/resources/cyberglossary/intrusion-detection-system
Diagrams are made using Canva
Thank you for reading throughout! If you found this post insightful, please show your appreciation by liking this post and sharing it. Don’t forget to follow me for more engaging content like this. Your feedback is valuable, so please feel free to comment or reach out to me with any thoughts or suggestions.
If you enjoy reading about my solutions to various Leetcode problems and would like to receive them directly in your inbox as soon as I publish them, consider subscribing to my newsletter on Hashnode. Stay updated and dive into the world of problem-solving with me!
Happy reading and happy coding!
Subscribe to my newsletter
Read articles from Subhradeep Saha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by