Graceful Shutdown: Why It Matters and How to Implement It
 jorzel
jorzel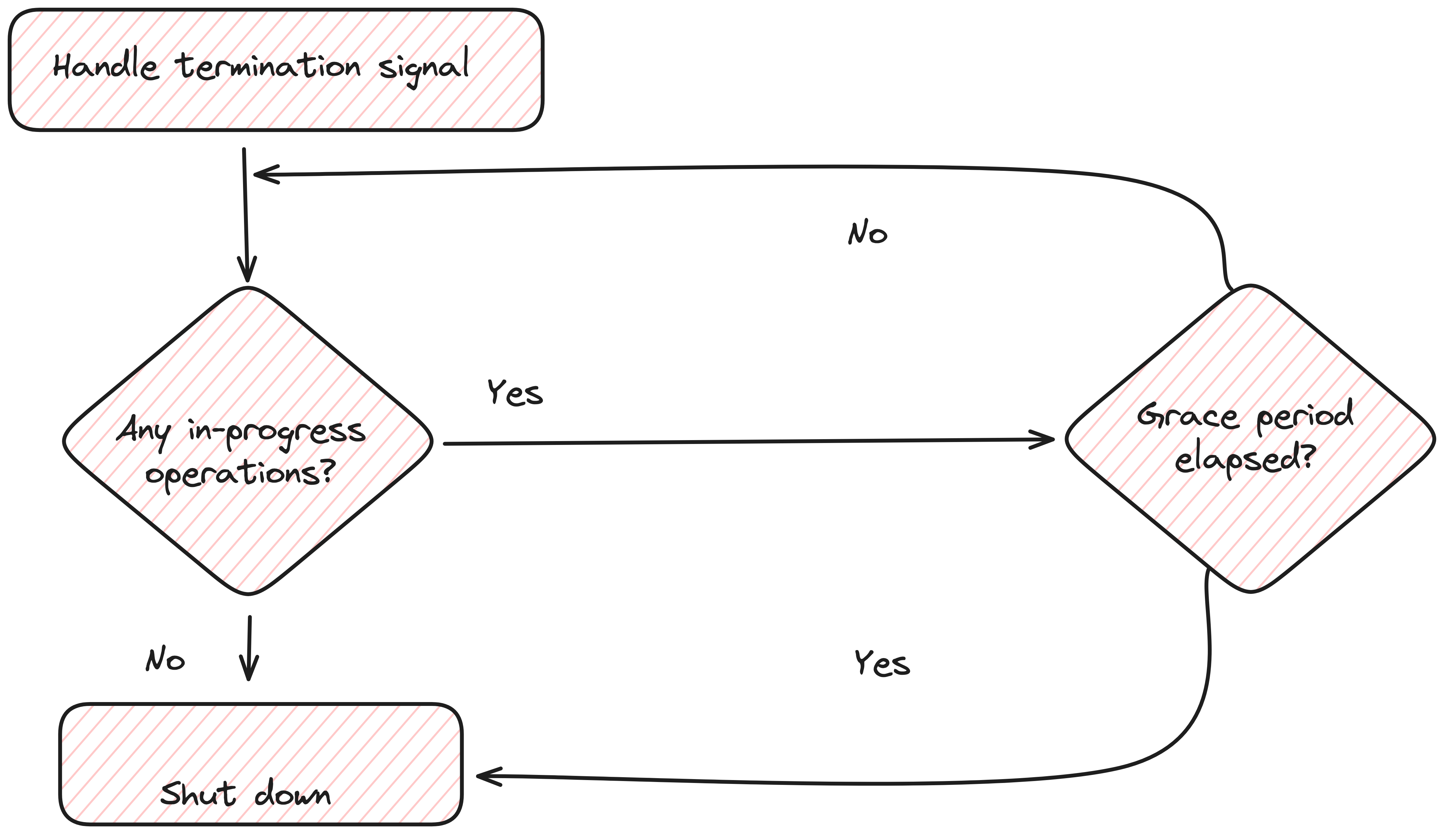
Introduction
Have you ever wondered what happens to ongoing requests when you deploy a new version of a service and it gets restarted? Do these operations finish correctly, or are they abruptly terminated with an exception? If you're unsure, it's likely the latter. To ensure that your ongoing operations are complete before the service terminates, you need to design your system for graceful shutdown. This means giving the system some time to finish ongoing operations before it shuts down. In this post, I will explain why graceful shutdown is important in modern software development and how to implement it for a Filesystem Listener Service written in Go.
The idea of a graceful shutdown
A graceful shutdown is the process of shutting down a system, application, or service in a manner that allows it to complete its current tasks, release resources properly, and save its state, thereby minimizing disruption and data loss.
Imagine a service that does not care about graceful shutdown.
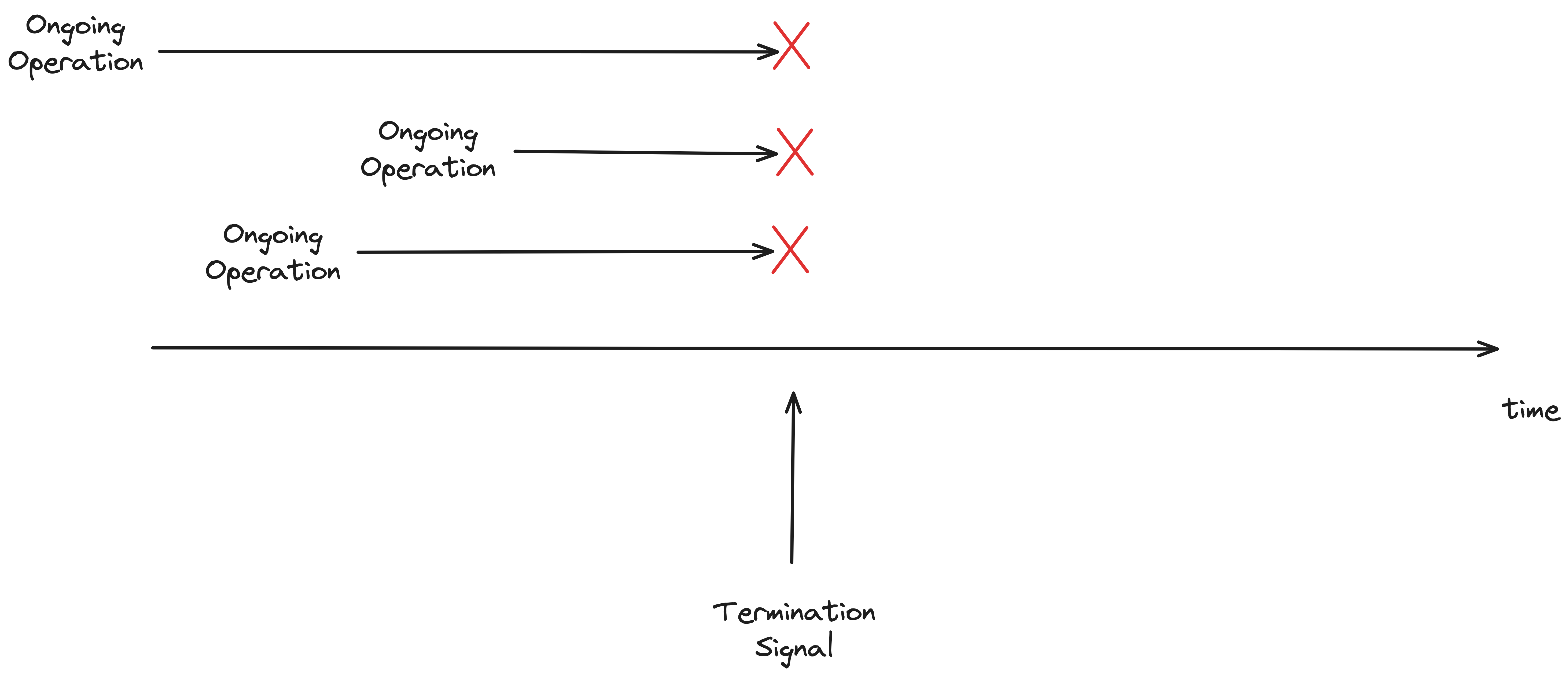
In the above diagram, we can see, that the termination signal (e.g., SIGTERM, SIGINT) interrupts all ongoing operations, and the information about them is lost.
How can we improve it?
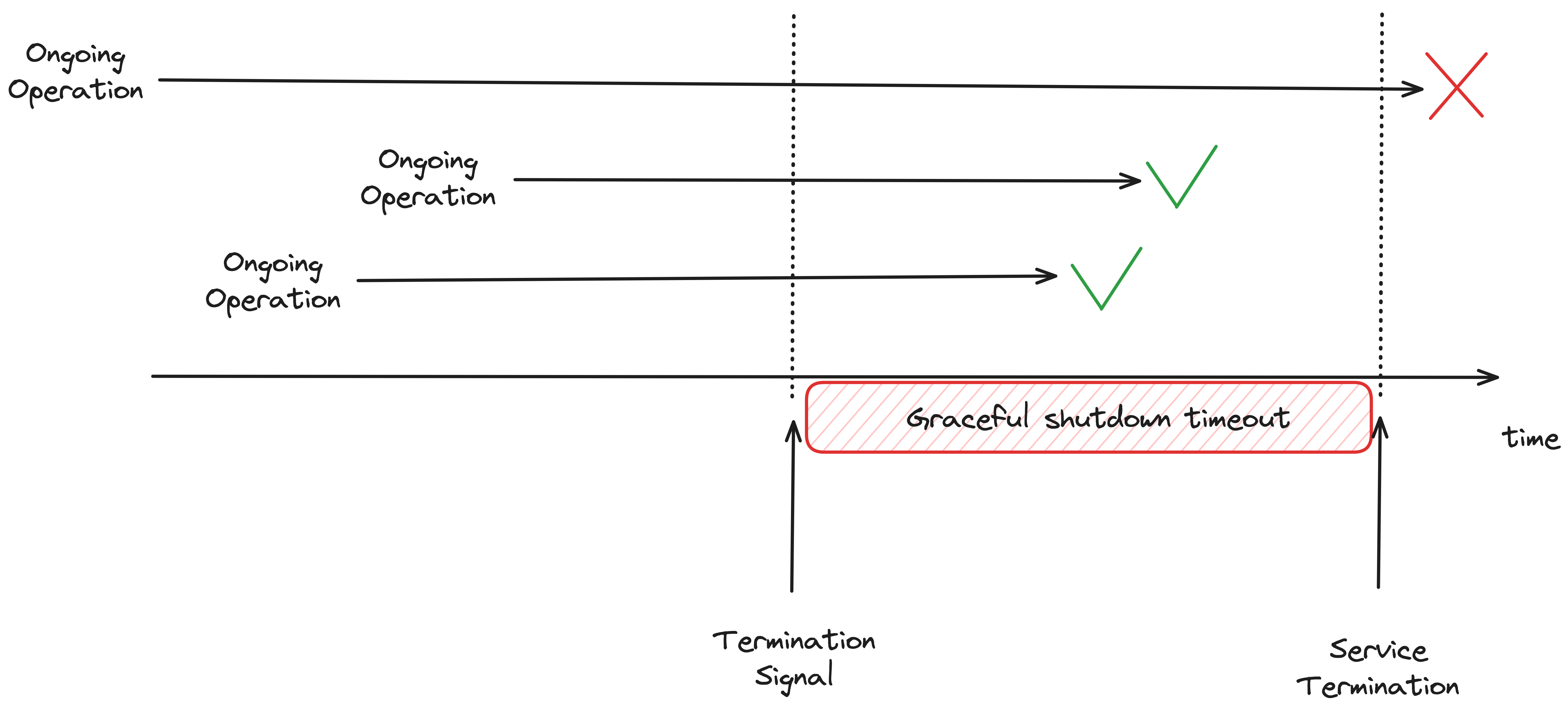
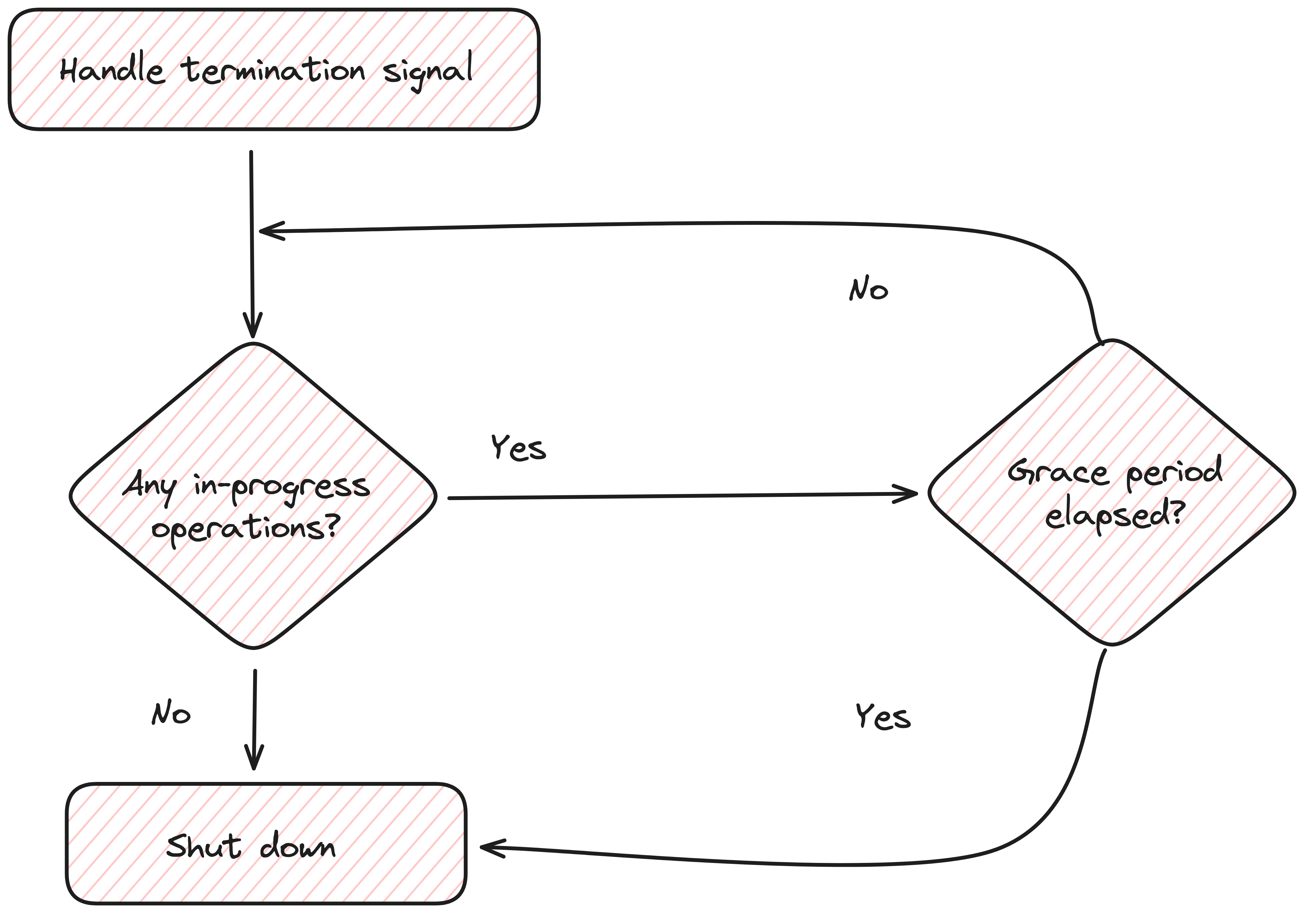
As soon as the termination signal is received, we give in-progress operations some time to complete (we also have to stop accepting new tasks). And after that grace period, we close the system. However, preparing a service for graceful shutdown does require a shift in design thinking:
Tracking Ongoing Operations: You need a mechanism to track and monitor ongoing operations. This might involve using counters, flags, or other indicators that can be checked to determine if any processes are still running.
Signal Handling: Your application should be able to handle termination signals (e.g., SIGTERM, SIGINT) and respond appropriately.
Waiting for Completion: Once a shutdown signal is received, the system needs to allow time for ongoing operations to complete.
Resource Cleanup: Ensure that all resources (e.g., database connections, and file handles) are properly closed and cleaned up during shutdown.
Why it matters
The first reason we should care about graceful shutdown is that we no longer treat our servers as pets, but rather as cattle. This means that servers can be killed or restarted at any time if needed. Traditionally, servers were treated like pets. Each server was unique, carefully maintained, named, and manually configured. If a server had an issue, it was individually tended to and fixed. In contrast, the modern approach treats servers like cattle. Each server is identical and can be quickly replaced if it fails. They are managed as a group rather than individually.
The cattle approach makes autoscaling possible, a popular method in containers' orchestrators (like Kubernetes) where the number of service replicas adjusts based on demand. This approach allows replicas to be easily started or destroyed as needed.
Secondly, we want to deliver new system versions in the DevOps culture organizations quite frequently. Continuous deployment practices aim for zero downtime during updates or scaling operations. Graceful shutdowns are essential to achieving this by allowing services to withdraw gracefully, thus preventing abrupt disconnections and errors.
How to implement it
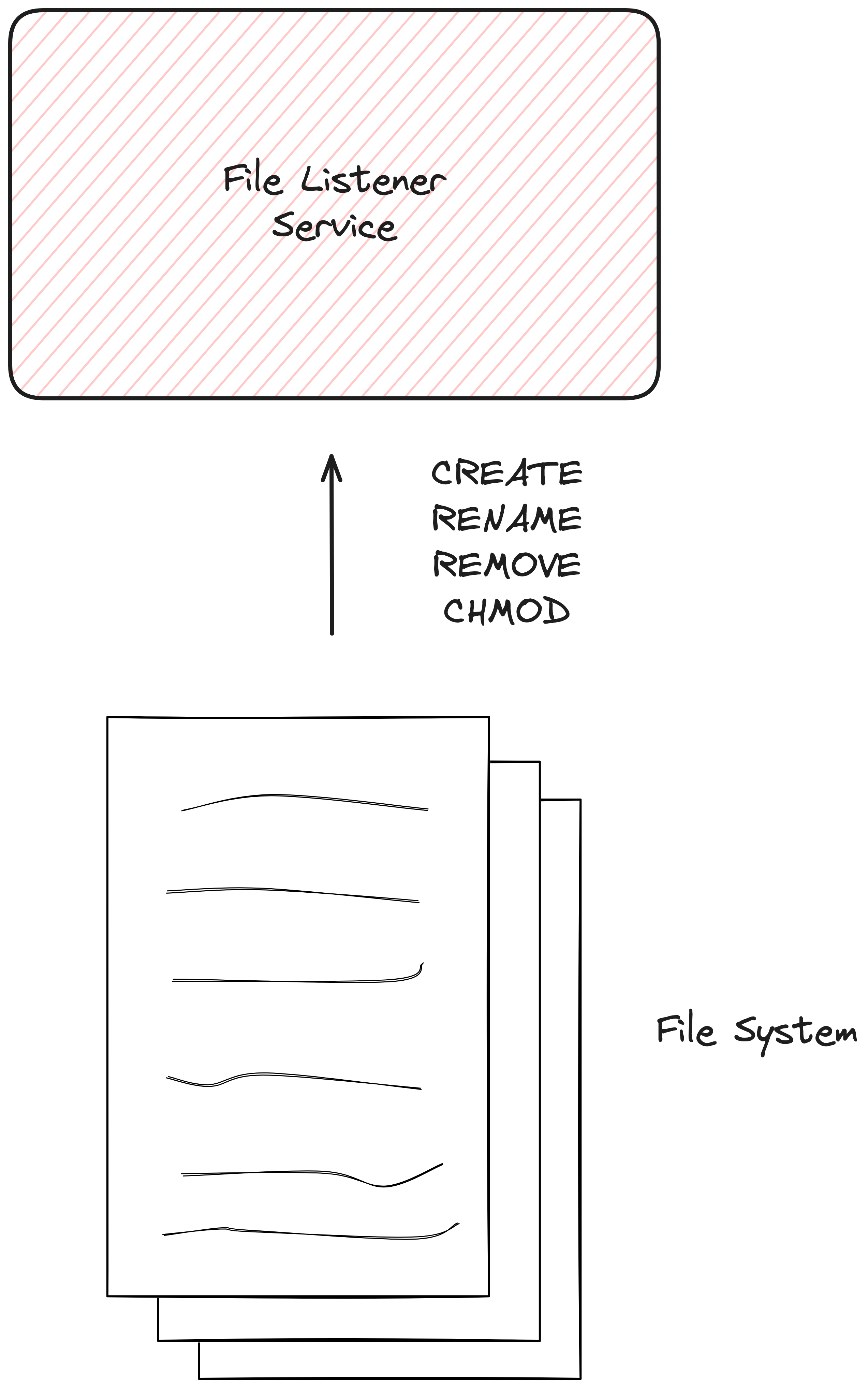
As an example of graceful shutdown implementation, we present a simple File Listener Service written in Golong that watches (we employ fsnotify library) for events from the filesystem. When the file is created, modified, or deleted, an event is handled by the service.
package main
import (
"context"
"fmt"
"os"
"os/signal"
"strings"
"sync"
"syscall"
"time"
"github.com/fsnotify/fsnotify"
"github.com/rs/zerolog"
)
func main() {
logger, err := configureLogger("INFO")
if err != nil {
logger.Fatal().Err(err).Msg("Cannot configure logger")
}
ctx := logger.WithContext(context.Background())
watcher, err := fsnotify.NewWatcher()
if err != nil {
logger.Fatal().Err(err).Msg("Cannot create filesystem watcher")
}
listener := NewFileListener(watcher, FileHandler{})
go listener.Start(ctx, "./")
<-ctx.Done()
}
type FileHandler struct{}
type FileListener struct {
watcher *fsnotify.Watcher
handler FileHandler
ongoindHandlers sync.WaitGroup
}
func (dfh *FileHandler) Handle(ctx context.Context, event fsnotify.Event) {
// Do something with the event
time.Sleep(15 * time.Second)
}
func NewFileListener(
watcher *fsnotify.Watcher, handler FileHandler,
) *FileListener {
return &FileListener{
watcher: watcher,
handler: handler,
}
}
// Start trigger FilesystemListener to listen on file events within sourcePath directory indefinetely
func (fl *FileListener) Start(ctx context.Context, sourcePath string) error {
logger := zerolog.Ctx(ctx)
logger.Info().Str("sourcePath", sourcePath).Msg("Filesystem listener started ...")
err := fl.watcher.Add(sourcePath)
if err != nil {
return fmt.Errorf("cannot add %s path to filesystem listener: %w", sourcePath, err)
}
go fl.listen(ctx)
return nil
}
func (fl *FileListener) listen(ctx context.Context) {
logger := zerolog.Ctx(ctx)
for {
select {
case event, ok := <-fl.watcher.Events:
if !ok {
logger.Info().Msg("File listener stopped listening")
return
}
go fl.handle(ctx, event)
case err, ok := <-fl.watcher.Errors:
if !ok {
logger.Info().Msg("File listener stopped listening")
return
}
logger.Error().Err(err).Msg("File listener event error")
}
}
}
func (fl *FileListener) handle(ctx context.Context, event fsnotify.Event) {
logger := zerolog.Ctx(ctx)
logger.Info().Str("event", event.String()).Msg("File event received")
fl.ongoindHandlers.Add(1)
defer fl.ongoindHandlers.Done()
fl.handler.Handle(ctx, event)
logger.Info().Str("event", event.String()).Msg("File event handled")
}
We imitate long handling by time.Sleep:
func (dfh *FileHandler) Handle(ctx context.Context, event fsnotify.Event) {
// Do something with the event
time.Sleep(15 * time.Second)
}
The listener is initialized to watch for the directory we executed the service:
go listener.Start(ctx, "./")
What happens when we have some ongoing task (handling created p.txt file), but suddenly stop the service (using ctrl+c).
{"time":"2024-05-19T10:19:59Z","message":"Filesystem listener started ..."}
{"message":"File event received", "event":"CREATE \"p.txt\"","time":"2024-05-19T10:20:03Z",}
^Csignal: interrupt
The service was closed immediately and handling was interrupted.
How can we improve it using a graceful shutdown approach?
// Stop listening on events
func (fl *FileListener) Stop(ctx context.Context) error {
err := fl.watcher.Close()
logger := zerolog.Ctx(ctx)
logger.Info().Msg("Filesystem listener closed")
logger.Info().Msg("Waiting for ongoing handlers to finish ...")
fl.ongoindHandlers.Wait()
logger.Info().Msg("All ongoing handlers finished")
return err
}
func main() {
...
go listener.Start(ctx, "./")
//graceful shutdown
terminateSignal := make(chan os.Signal, 1)
signal.Notify(terminateSignal, os.Interrupt, syscall.SIGTERM, syscall.SIGINT, syscall.SIGHUP)
<-terminateSignal
logger.Info().Msg("Received termination signal. Shutting down ...")
err = listener.Stop(ctx)
if err != nil {
logger.Fatal().Err(err).Msg("Cannot stop listener")
}
}
Termination signals information is passed to the terminatateSignal channel. When we get the message on the channel, we can perform a graceful shutdown using listener.Stop(ctx) method. Within this method, we stop waiting for new operations err := fl.watcher.Close() and also wait till all handlers finish ongoing tasks.
Now, we can check what happens when we interrupt the service while it is handling tasks:
{"time":"2024-05-19T10:37:26Z","message":"Filesystem listener started ..."}
{"time":"2024-05-19T10:37:31Z","message":"File event received", "event":"CREATE \"x.txt\""}
^C
{"time":"2024-05-19T10:37:34Z","message":"Received termination signal. Shutting down ..."}
{"time":"2024-05-19T10:37:34Z","message":"Filesystem listener closed"}
{"time":"2024-05-19T10:37:34Z","message":"Waiting for ongoing handlers to finish ..."}
{"time":"2024-05-19T10:37:34Z","message":"File listener stopped listening"}
{"time":"2024-05-19T10:37:46Z","message":"File event handled", "event":"CREATE \"x.txt\"",}
{"time":"2024-05-19T10:37:46Z","message":"All ongoing handlers finished"}
The termination signal was received but did not force the service to close immediately. We have waited unit all ongoing operations were handled.
As we said before, we should give some time a service to complete the operation but we cannot wait indefinitely. To implement a grace period, we can use context with timeout:
gracePeriod := 15*time.Second
ctx, cancel := context.WithTimeout(ctx, gracePeriod)
defer cancel()
err = listener.Stop(ctx)
Conclusion
Graceful shutdown is a powerful technique that enhances the reliability of your system and ensures that continuous delivery works seamlessly. By properly handling termination signals, tracking ongoing operations, and allowing time for completion, you can maintain service quality even during frequent updates and restarts. Implementing graceful shutdown practices not only prevents data loss and service interruptions but also aligns with modern infrastructure approaches that treat servers as cattle, enabling efficient autoscaling and dynamic resource management.
The codebase covering the Filesystem Listener Service can be found here.
Subscribe to my newsletter
Read articles from jorzel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
jorzel
jorzel
Backend developer with special interest in software design, architecture and system modelling. Trying to stay in a continuous learning mindset. Enjoy refactoring, clean code, DDD philosophy and TDD approach.