Apache Arrow - Evolution of the Big Data ecosystem
 Ayman Patel
Ayman Patel
We had the Hadoop boom in 2010s; which lead to the explosion of a lot of Big data technologies such as HDFS, Kafka, Spark, Sqoop, Hive, Pig, Parquet etc. But as the hype vained and scale started to show the limitations of Hadoop; there has been a constant need to migrate from the Hadoop ecosystem. Apache Arrow came into the scene to make an interoperable system that worked well will all type of big data/analytical ecosystem. It was created by Wes McKinney (who also created pandas)
There are many projects under Apache Arrow, but these are the most prevalent and important projects in the Apache Arrow ecosystem
Apache Arrow
Apache Arrow Flight
Apache Arrow Flight SQL
Apache Arrow ADBC
Apache Datafusion
This is what the ideal scenario seems to be for Apache Arrow where each database is able to hook into the Apache Arrow ecosystem by using the Arrow memory format, Arrow RPC using Flight, Arrow ADBC for JDBC-like interfaces for column-oritented datbase and Apache Datafusion for decoupled query engine.
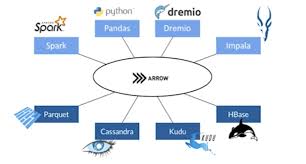
Who uses Arrow?
InfluxDB in their v3 have gone all-in on the Apache Arrow ecosystem by leveraging the FDAP stack(Flight, Datafusion, Arrow and Parquet)
Hugging Face dataset uses Apache Arrow for efficient loading of dataset models
1. Apache Arrow
Apache Arrow is the core of all things in the ecosystem. It is an in-memory column oriented format that hooks into almost of the languages (C, C++, C#, Java, Python, R, Ruby etc).
Apache Arrow does zero-copy read to eliminate unnecessary data copy calls which removes the serialization overhead in traditional database memory storage systems.
Memory format
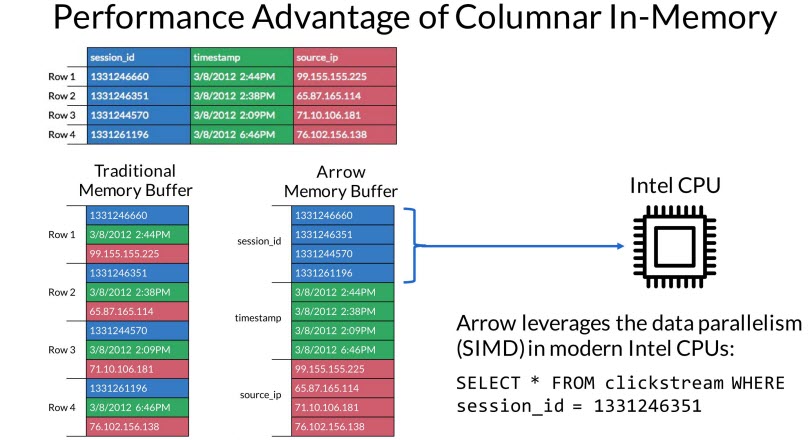
As a thumb of rule, for OLTP databases, having row-based querying and storage makes sense; as most of the queries are based on an ID such a product_id, employee_id. But in analytical databases, most of the queries are aggregates, GROUP BY etc. which are more inclined towards columns that the rows. Due to this fact, Apache Arrow tries to store the data in the memory buffer as a sequence of columns instead of rows. This has major performance gains for big data workloads.
As we will see, this ecosystem slowly eats up in all parts of the stack to make Apache Arrow the true interface for Big Data!
2. Apache Arrow Flight
Apache Arrow Flight is a RPC protocol which is used to send Arrow columnar formatted data over the network. Initially, Apache Flight was based on gRPC; it is not the only supported format.
Why Apache Flight?
In the boom of big data and Hadoop explosion; the data was stores in filesystems such as HDFS/S3; and these were serialized and deserialized for storing and querying data. The cost of serialization/deserialization was massive burden and overhead during the transport phase. Apache Arrow solved this by storing the data in the columnar format at the memory-level and reducing the over-the-wire derserialization costs.
Apache Flight provided a TCP-like frameworks for sending data streams. Similar to TCP where there is a 3-way handshake process before sending initial data packets, Apache Flight has methods to do the same with data streams.
The methods are:
| Metohd | Description |
| Handshake | Handshake between client and server |
| ListFlights | Possible data streams based on a criteria |
| GetFlightInfo | Get information how the flight data stream is to be consumed. |
| GetSchema | Get schema for Flight Data Stream |
| DoGet | Retrieve single stream |
| DoPut | Upload stream of data |
| DoExchange | Bidrectional data exchnage |
| DoAction | An arbitary action done by flight client against the flight service |
| ListActions | Available action for flight consumers to understand features of flight service |
3. Apache Arrow Flight SQL
This is experimental feature that might change or might be deprecated in future
Traditionally JDBC and ODBC were used for interacting with databases. These were and are still great for row-oriented databases, but for column-oriented database, JDBC/ODBC require to convert/transpose data from row <-> columnar data. FlightSQL aims to solve this by providing an interface at the database level to allow sending data Apache Arrow (and other columnar data) from the start at the database level. Since it is based on Apache Flight RPC ,it uses Protobuf messages for sharing information.
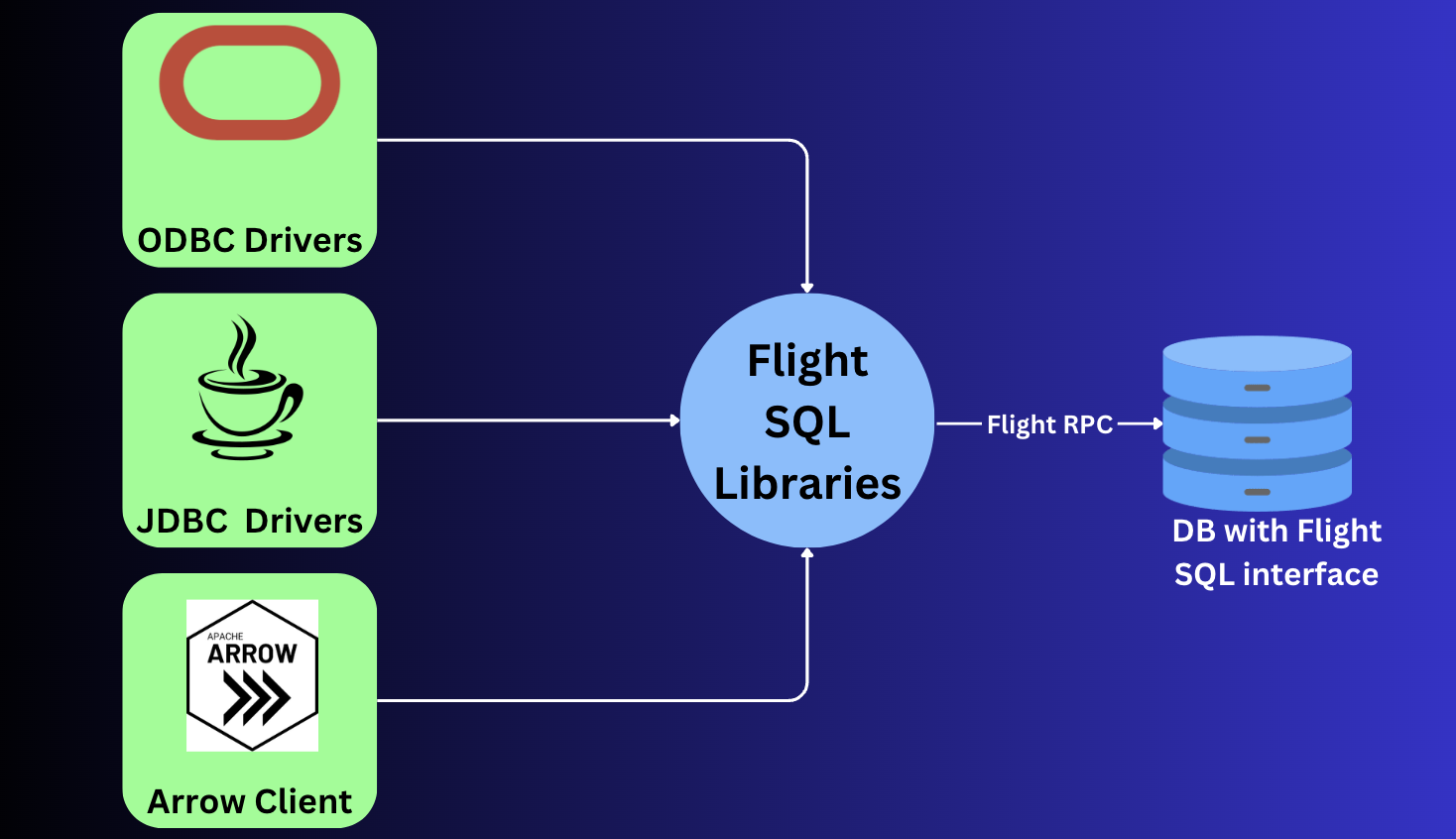
4. Apache Arrow ADBC
JDBC/ODBC are great for providing a connection abstraction for clients. But these are well-suited for row-based databases. For column-oriented databases, Apache Arrow ADBC was created to solve for OLAP/Analystical/Coulmn-based databases.
It is a database-neutral API for interacting with database that use the Arrow memory format.
The steps include for using the ADBC end-to-end are:
Client application submits SQL via ADBC API
SQL Query is passed to ADBC Driver (similar to JDBC/ODBC for row-based RDBMS)
Driver converts SQL query to database-specific protocol and sends to database
Database executes query and sends result in Arrow format
Client application receives data in Arrow format.
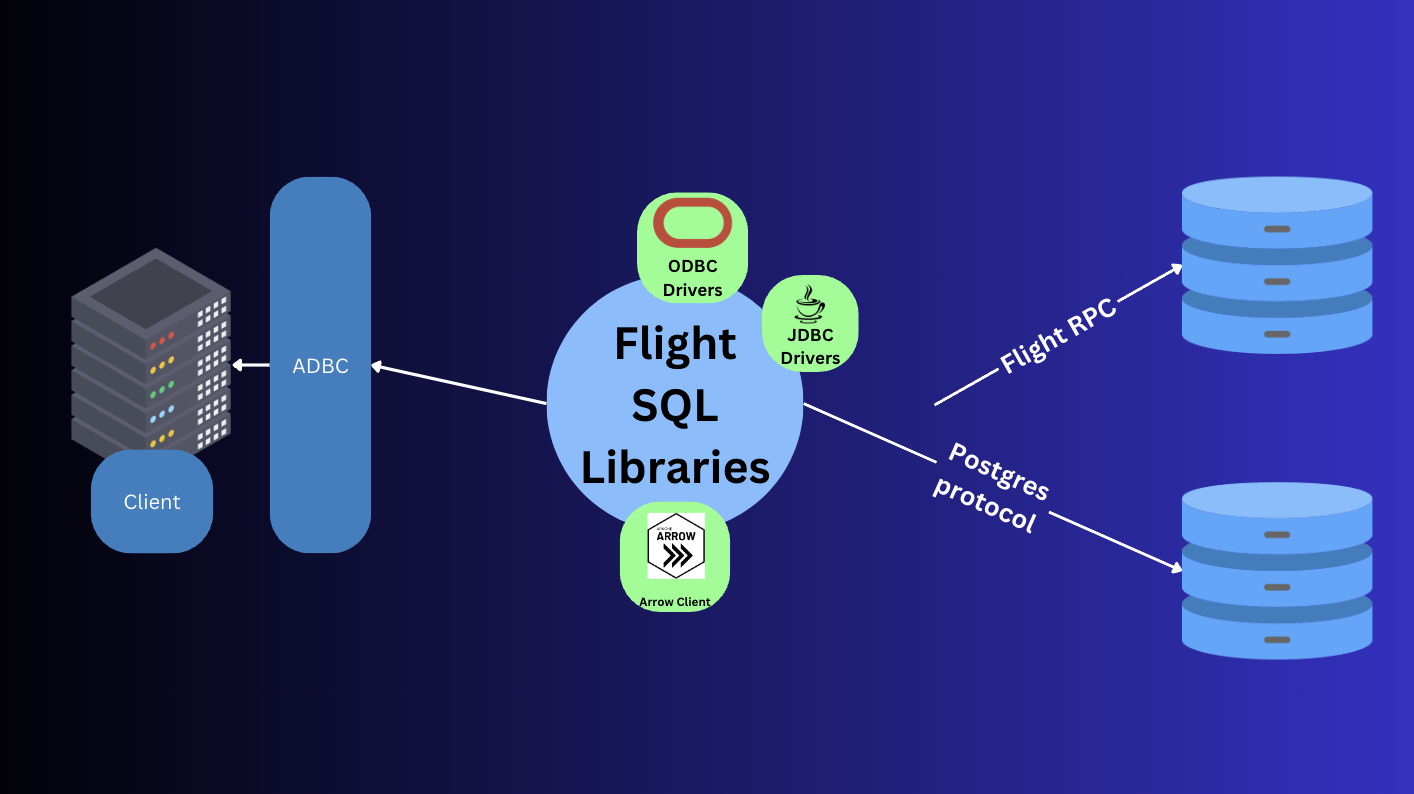
Difference between ADBC and Flight SQL
ADBC is more client-focused API to make clients work with different databases, whilst Arrow Flight SQL is database focused wire-protocol that database can implement.
| Type | Database Neutral/Agnostic | Database Specific |
| Arrow-native aka Column Based | ADBC | Arrow Flight SQL |
| OLTP aka Row-based | JDBC, ODBC | Postgres, TDS, SQL, libpq protocol |
5. Apache Datafusion
Apache Datafusion is a query engine written in Rust that works with the Apache Arrow ecosystem, has python bindings, works with most popular data formats such as JSON, CSV, Parquet, Avro.
So what is a query engine?
In database, data is stored durably somewhere in HDD, SSD as S3 buckets, filesystems. This data needs to be queried from the data to the client. The query could be the traditional SQL; but their are other querying paradigms such as PromQL(Prometheus), InfluxQL(InfluxDB), GraphQL etc. Query engine helps to bridge this gap between the storage and the client. Most database systems have their own query engines. So in short, query engine is a subset of DBMS that is primarily used to query data from storage to the client.
So where does Apache Datafusion comes into the picture? Instead of reimplementing the query engine for every database system such as Postgres, Spark, Duckdb, Snowflake, Prometheus; Datafusion can help abstract it in such a way; so that these database can agree to a single interface and also make improvements in other part of the stack such as storage, fault tolerance etc.
You can read more about what exactly is a query engine from the person who created Apache Datafusion; i.e Andy Grove. Book link
Features
The features of Apache Datafusion are:
Performance: Leverage Rust and Arrow to achieve this. Since it is built on Rust, it is not garbage collected.
Connectivity: Have connectivity with Arrow, Flight and Parquet
Extensibility
Popular projects using Apache Datafusion are InfluxDB, ParadeDB(Postgres for Analytics)
Subscribe to my newsletter
Read articles from Ayman Patel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ayman Patel
Ayman Patel
Developer who sees beyond the hype