DAG in Apache Spark in 10 points
 Prakhar Srivastava
Prakhar Srivastava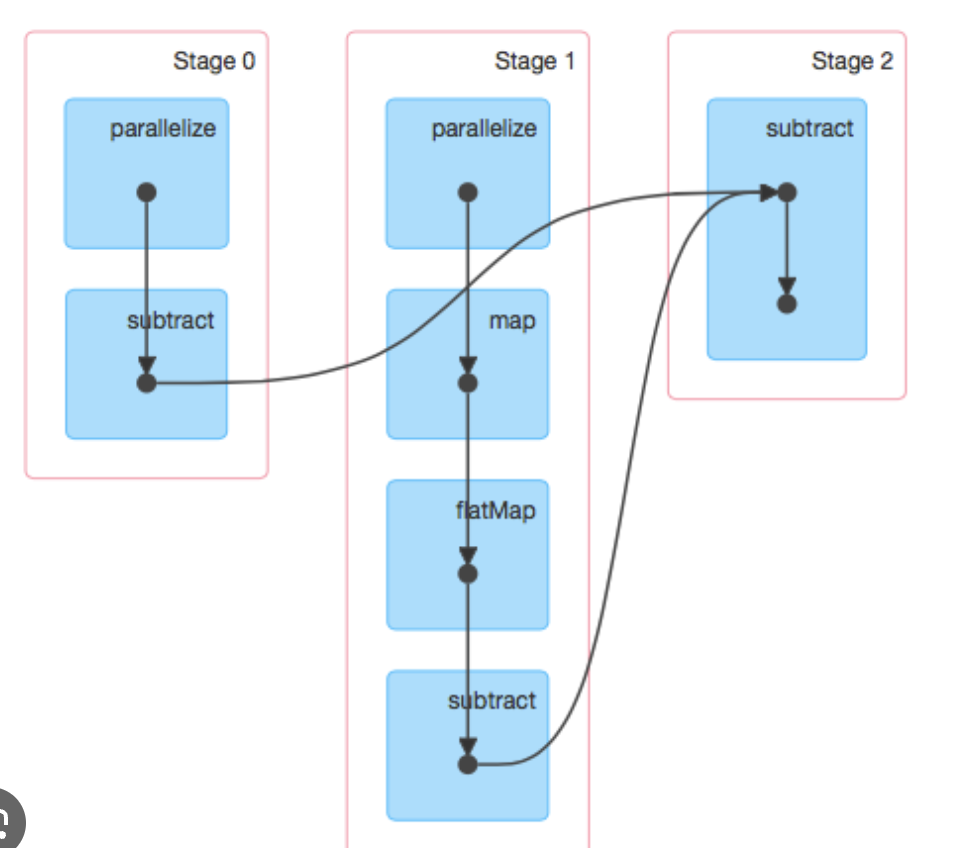
🍀Directed Acyclic Graph (DAG): In Apache Spark, the execution plan is represented as a DAG, a directed acyclic graph. It visually outlines the sequence of stages and tasks required to compute the final result.
🍀Logical and Physical Execution Plans: The DAG has both logical and physical representations. The logical plan describes the high-level transformations, while the physical plan details how these transformations are executed on the cluster.
🍀Stages: The DAG is divided into stages, where each stage consists of tasks that can be executed in parallel. Stages are determined by the presence of shuffle operations, like groupBy or join, which require data to be rearranged.
🍀Transformations: Transformations on RDDs (Resilient Distributed Datasets) trigger the creation of new stages in the DAG. Examples include map, filter, and reduce operations.
🍀Lineage: Spark uses lineage information to recover lost data due to node failures. Each RDD in the DAG keeps track of its parent RDDs, forming a resilient lineage.
🍀 Narrow and Wide Dependencies: Stages are composed of tasks with narrow or wide dependencies. Narrow dependencies allow for parallel execution, while wide dependencies require data shuffling and introduce stages boundaries.
🍀 Caching and Persistence: DAGs help in optimizing the computation by allowing users to cache intermediate results. This reduces redundant computations and improves overall performance.
🍀 Lazy Evaluation: Spark uses lazy evaluation, postponing the execution of transformations until an action is triggered. The DAG is constructed during this process.
🍀 Task Scheduling: Once the DAG is constructed, Spark's scheduler determines the order of task execution across the cluster nodes, optimizing for data locality and resource availability.
🍀 Optimizations: Spark performs various optimizations on the DAG, like pipelining narrow transformations, to minimize data movement and improve the overall efficiency of the computation.
Subscribe to my newsletter
Read articles from Prakhar Srivastava directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Prakhar Srivastava
Prakhar Srivastava
I am a Data Engineer with extensive experience in building Data systems to provide a. Analytics Platform. With expertise in conceptualizing and implementing data pipelines, I am responsible for converting data into informational insights thus helping the organization to make data-driven decisions.Have helped majority of banking, finance&telecom clients to take different data driven decisions.