Boost Sitecore Search with Advanced Web Crawling and JavaScript Extraction
 Amit Kumar
Amit Kumar
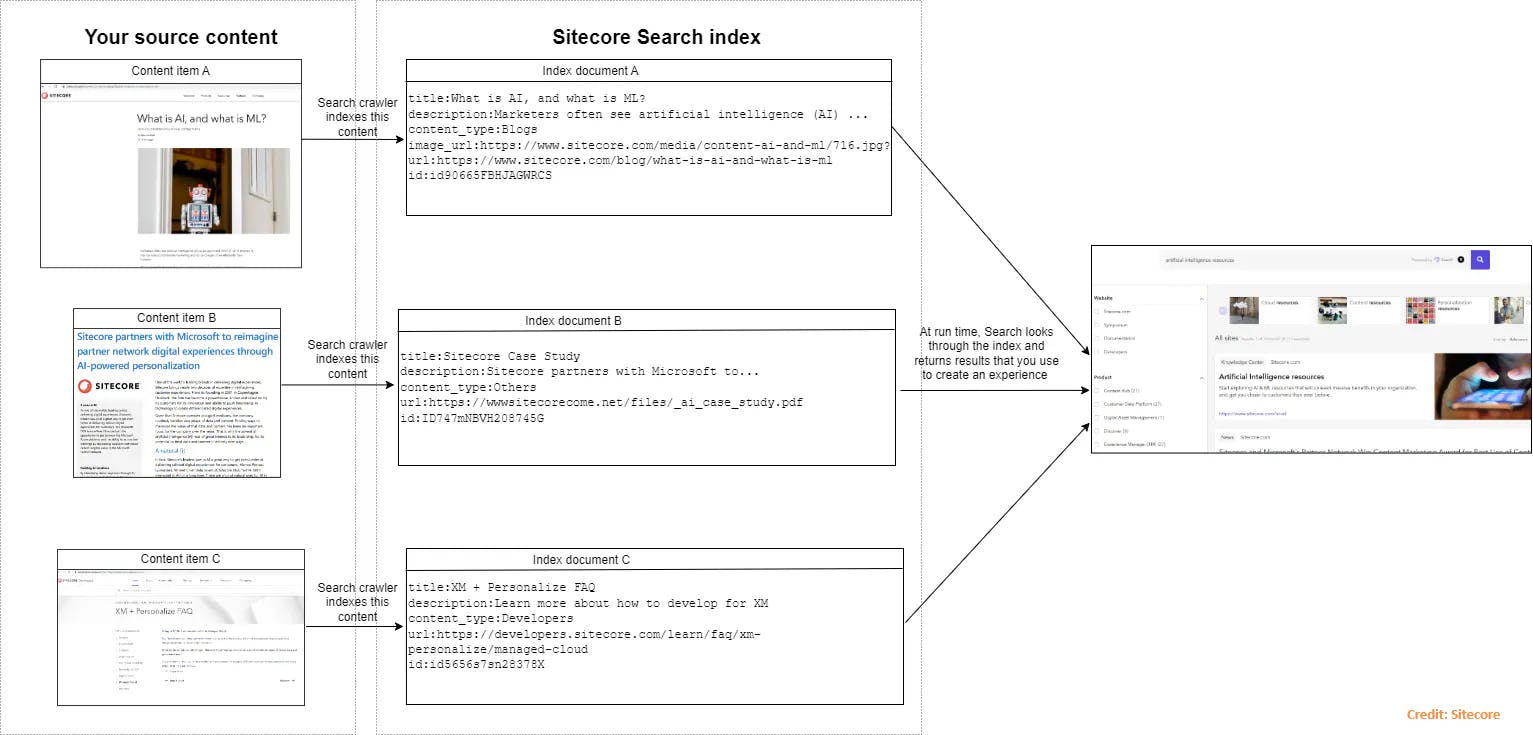
In today's digital landscape, delivering accurate and fast search results is crucial for an exceptional user experience. Sitecore, a leading digital experience platform, offers powerful search capabilities. By configuring the Sitecore Search with an advanced web crawler (that allows you to crawl and index content from various sources) and JavaScript document extractor, you can significantly enhance your search functionality. In this article, we’ll focus on configuring an advanced web crawler with a JavaScript document extractor. Let’s dive in!
You can find more details about Sitecore Search on my blog.
🤯Understanding the Advanced Web Crawler
The Sitecore Search's advanced web crawler is designed to traverse the web, indexing content efficiently. It can handle complex websites, including those with dynamic content generated by JavaScript. This ensures that all relevant information is captured and made searchable.
🏆Benefits of JavaScript Extraction
JavaScript extraction allows the crawler to read values (HTML attributes) from the page that need to be mapped to Search document attributes. In Sitecore Search's JS Extractor Type, we typically parse and manipulate the HTML of the page using JavaScript functions with custom logic. These functions should follow the Cheerio syntax. 🔝
🪜Step-by-Step Configuration
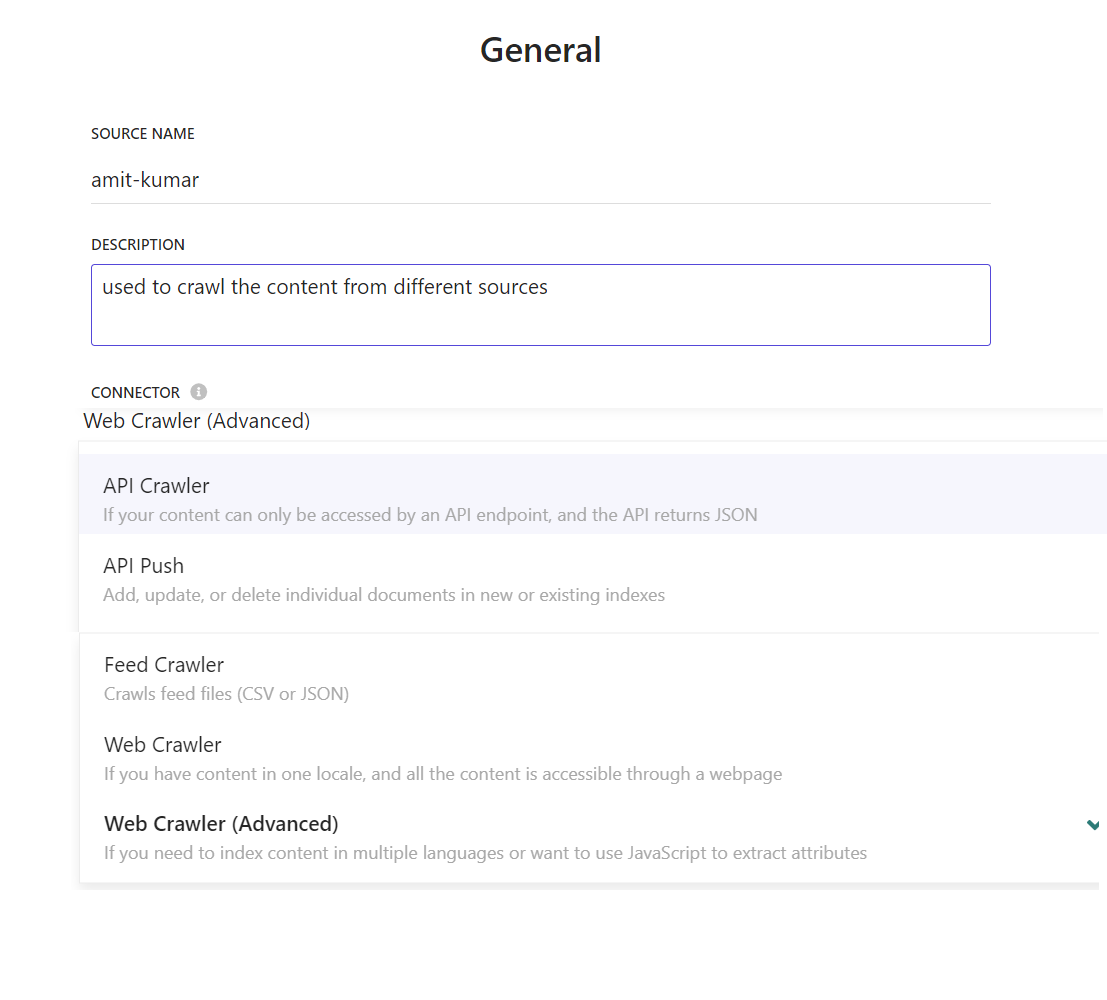
1. Create an Advanced Web Crawler Source
Before configuring the crawler, create a source in the Customer Engagement Console (CEC). Choose the “Web Crawler (Advanced)” connector type. Provide a clear name and description for your source. 🔝
2. Configure Advanced Web Crawler Settings
Access the Sitecore Search control panel i.e. Customer Customer Engagement Console (CEC) and navigate to the search configuration settings. Here, you can set up the Advance web crawler by providing the meaningful name and description:
3. Specify Allowed Domains
Add the domain names from which you need to crawl content. You can gather data from multiple sources or websites into a single Sitecore Search Source.
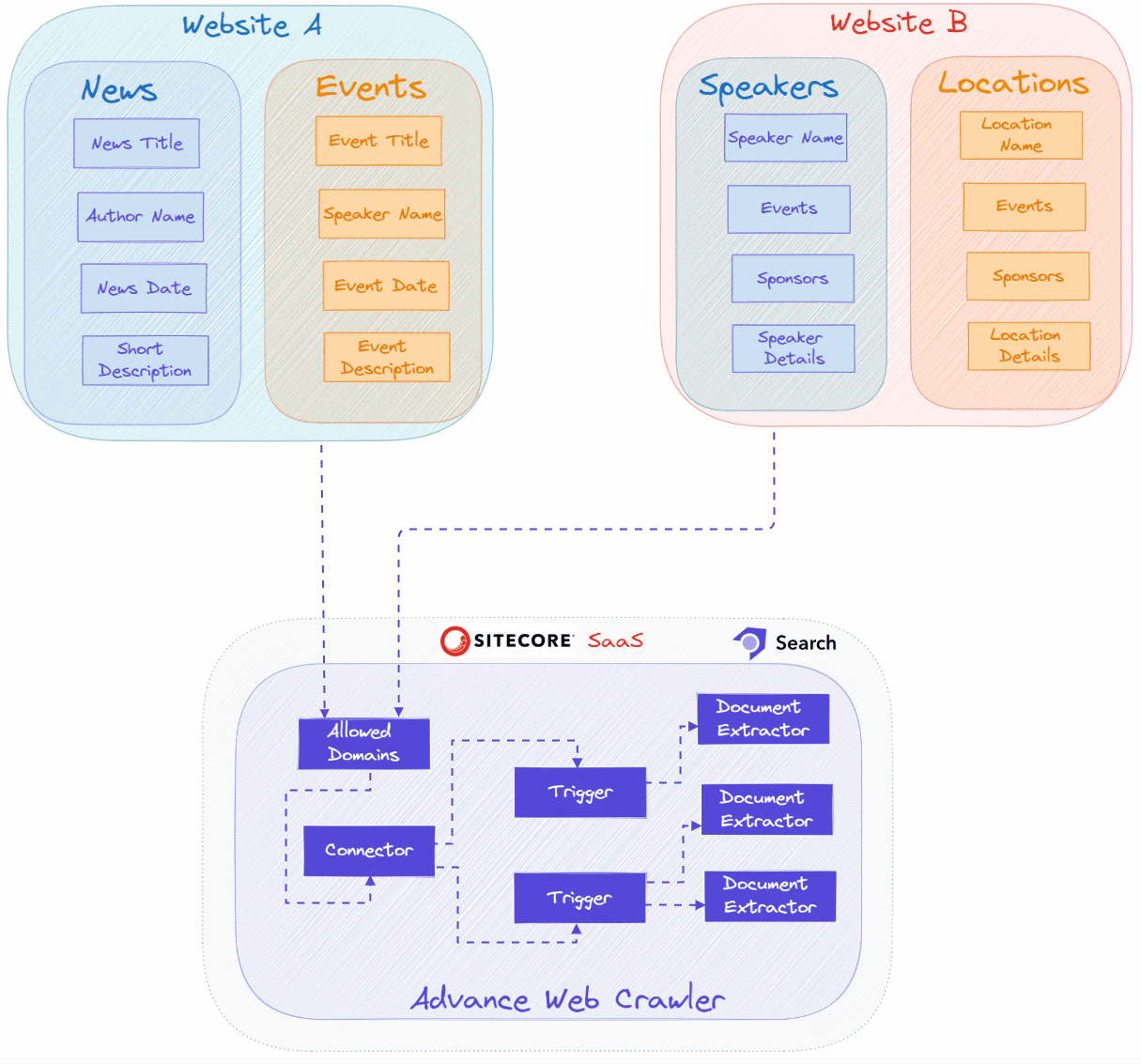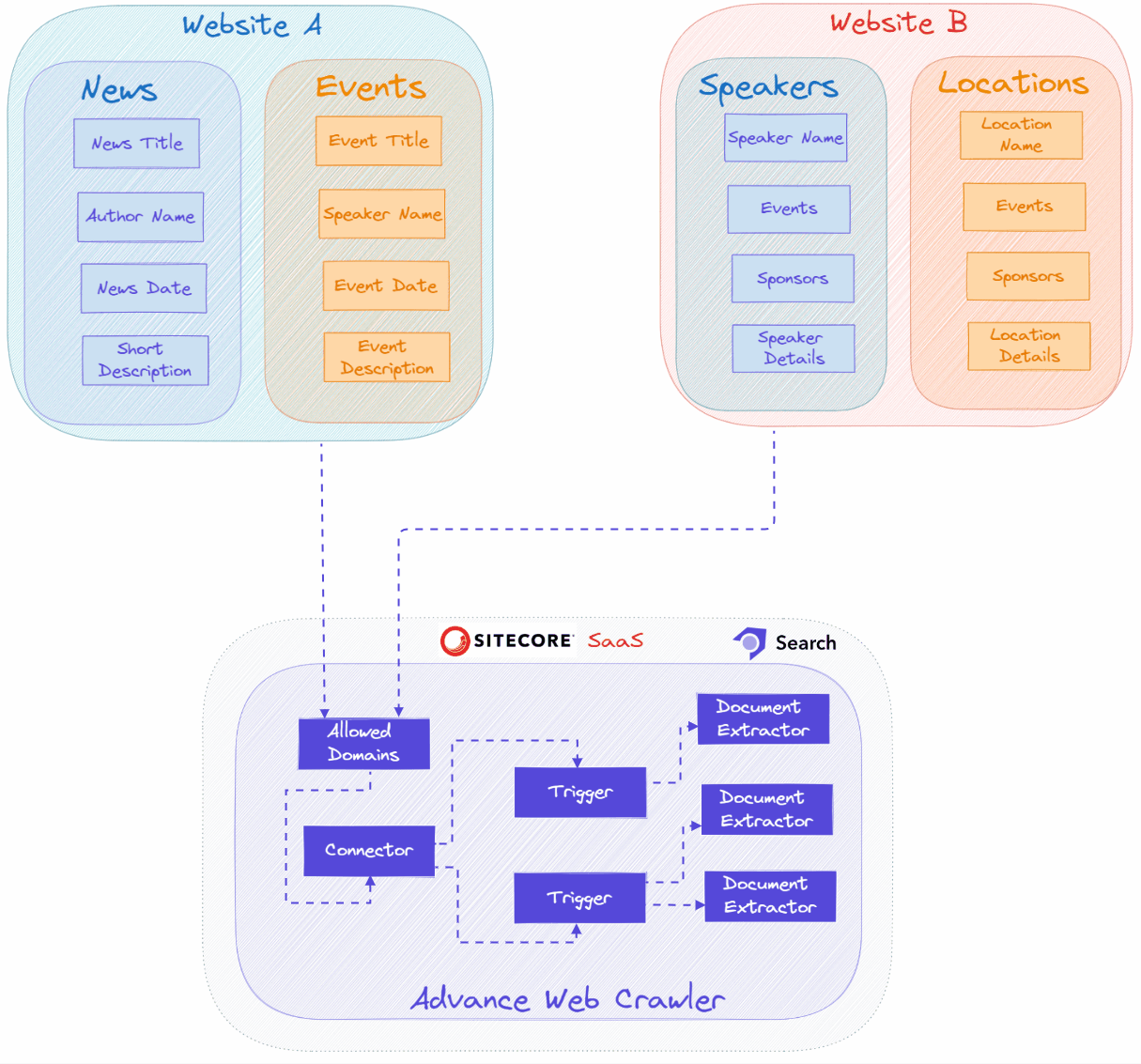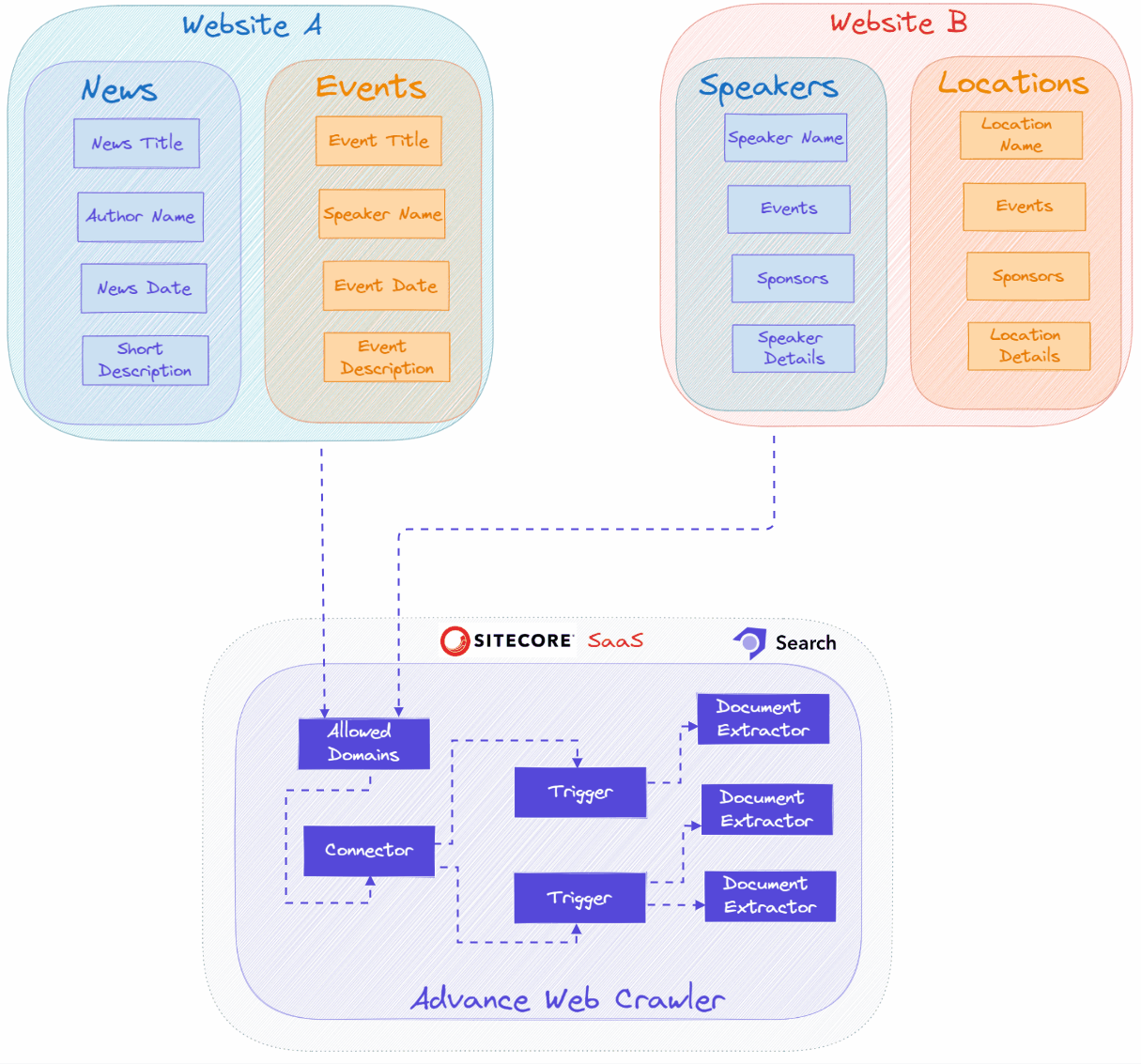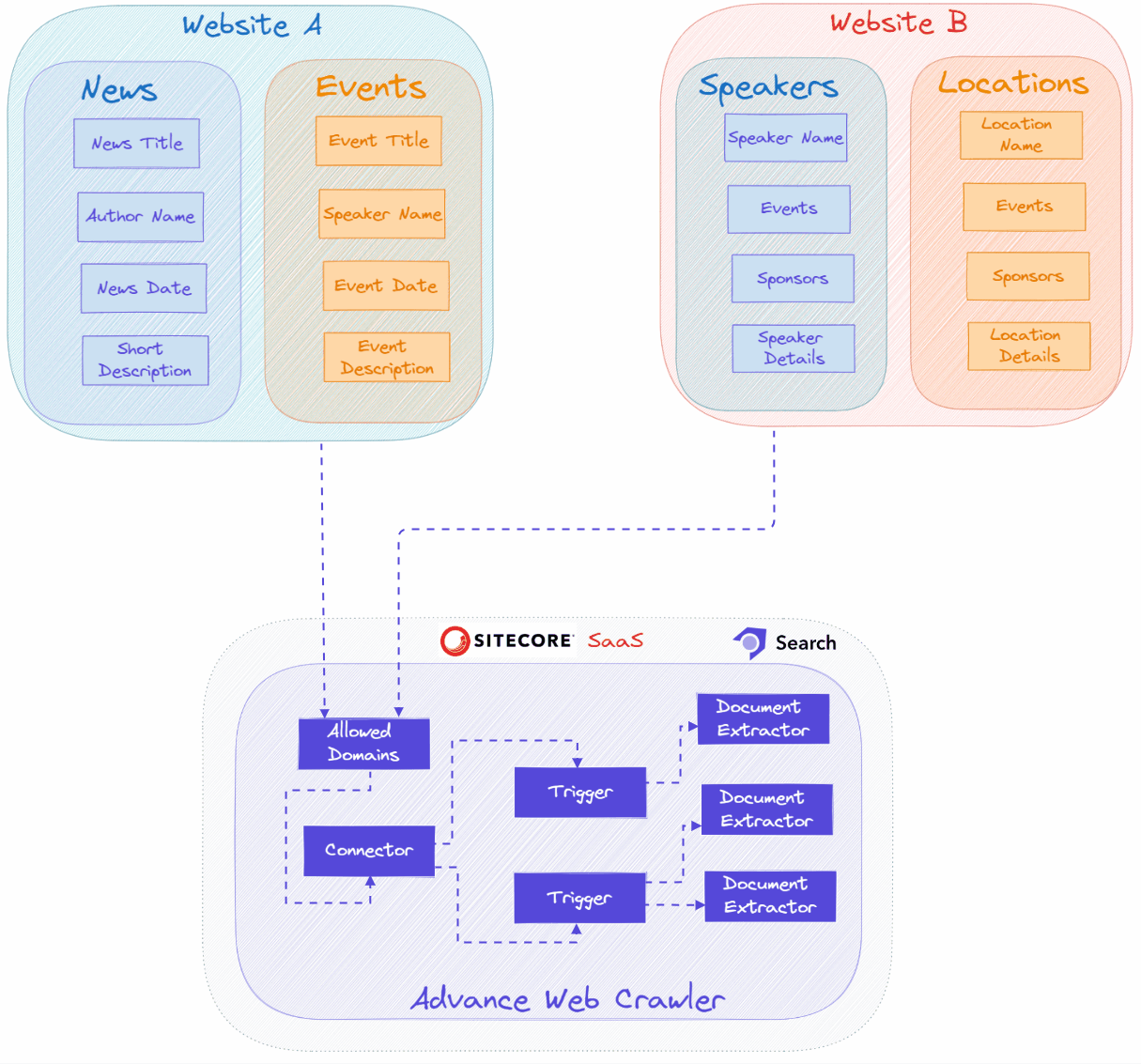
4. Web Crawler Settings
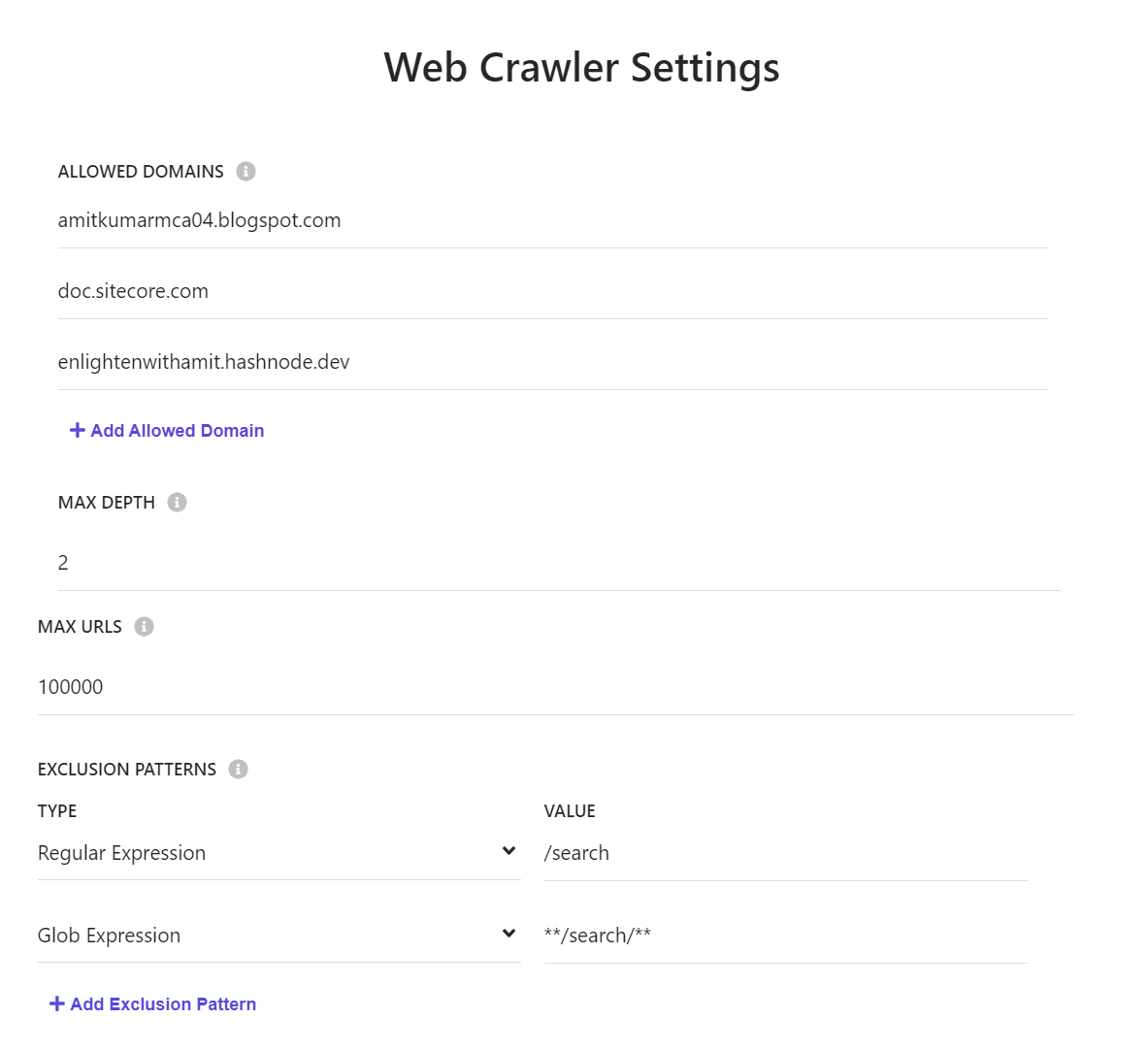
Set the maximum depth (number of levels), the maximum number of URLs to crawl, and add specific URL patterns to exclude. 🔝
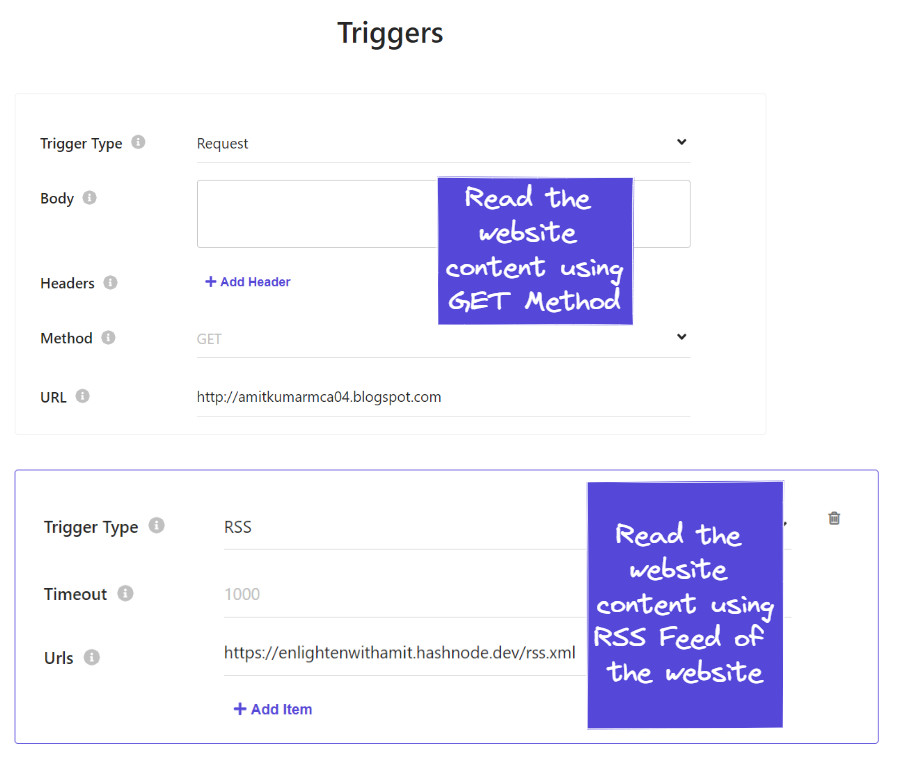
5. Add the Triggers
The Sitecore Search crawler uses the trigger to fetch the data from website (or) source based on the configured trigger type e.g., Request, RSS, etc. The trigger generally provides the inventory of URLs which crawler need to crawl. 🔝
6. Document Extraction with JavaScript
The document extractor will get data (source metadata) from the source and create an index document with the needed attributes as key:value pairs for each index document. 🔝
In a JavaScript document extractor, we can write custom logic to extract the required attributes as per our requirements from the crawled source, and add attributes to the index document, and then Sitecore Search add these index documents to the source's index so that user's can search can get search results.
To learn more about how to index your website content using Sitecore Search, visit my blog.
You can define different type of Sitecore Search's Document Extractors for different URL's based on your requirements: 🔝
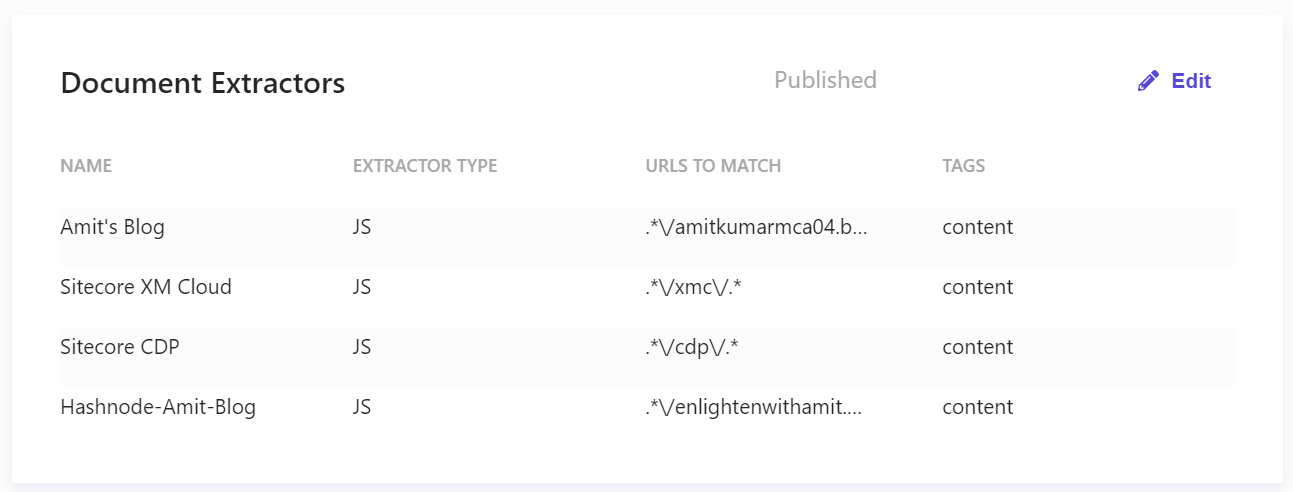
Sitecore Search's JavaScript Document Extractor will read the blog URL from amitkumarmca04.blogspot.com and extract the required page metadata, such as metadata into the array, datetime, etc. 🔝
function extract(request, response) {
$ = response.body;
let j =0;
let pagelastmodified = '';
let displaypagelastmodified = '';
$('time').each((i, elem) => {
j = j + 1;
if(j==2)
{
pagelastmodified = $(elem).attr('datetime');
displaypagelastmodified=$(elem).text().replaceAll("\n","");
}
});
let tagsArr = [];
let tagItem;
$('.post-labels').children('a').each(function(){
tagItem=new Object();
tagItem.name =$(this).text();
tagsArr.push(tagItem);
tagItem=null;
});
return [{
'description': $('meta[name="description"]').attr('content') || $('meta[property="og:description"]').attr('content') || $('p').text(),
'name': $('meta[name="searchtitle"]').attr('content') || $('title').text(),
'type': $('meta[property="og:type"]').attr('content') || 'Amit-Blog',
'url': $('meta[property="og:url"]').attr('content'),
'pagelastmodified': pagelastmodified,
'displaypagelastmodified': displaypagelastmodified,
'pagetags': tagsArr.length >0? JSON.stringify(tagsArr):"",
'product': 'Personal Blog',
}]
}
Sitecore Search's JavaScript Document Extractor will read the Sitecore documentation URL doc.sitecore.com and extract the required page metadata, such as metadata description, name, type, URL, and hardcoded product, which can be used for filtering or faceting, etc. 🔝
// Sample extractor function. Change the function to suit your individual needs
function extract(request, response) {
$ = response.body;
return [{
'description': $('meta[name="description"]').attr('content') || $('meta[property="og:description"]').attr('content') || $('p').text().trim(),
'name': $('meta[name="searchtitle"]').attr('content') || $('title').text().trim(),
'type': $('meta[property="og:type"]').attr('content') || 'Article',
'url': $('meta[property="og:url"]').attr('content') || $('link[rel="canonical"]').attr('href'),
'body': $('body').text(),
'product': 'Sitecore XM Cloud',
}];
}
Stecore Search's JavaScript Document Extractor will read data from the RSS feed at https://enlightenwithamit.hashnode.dev/ and extract the needed page metadata by looping through the RSS feed URLs. This includes type, description, publish date, and more. 🔝
function extract(request, response) {
const rssFeedResponseData = response.body;
if (rssFeedResponseData && rssFeedResponseData.length) {
let rssInfoArr = [];
let rssItem;
rssFeedResponseData('item').each((e, elem) => {
if( rssFeedResponseData(elem).children('title').text().trim()!==null){
rssItem=new Object();
rssItem.type ="Amit-Hashnode-Blog";
rssItem.name =rssFeedResponseData(elem).children('title').text().trim().replace('<![CDATA[','').replace(']]>','');
rssItem.description =rssFeedResponseData(elem).children('description').text().trim().substring(1, 400) + '...';
rssItem.url =rssFeedResponseData(elem).children('guid').text().trim();
rssItem.product ="Personal Blog";
rssItem.pagelastmodified= rssFeedResponseData(elem).children('pubDate').text().trim();
rssItem.displaypagelastmodified= rssFeedResponseData(elem).children('pubDate').text().trim();
rssInfoArr.push(rssItem);
rssItem=null;
}
});
return rssInfoArr;
} else {
return [];
}
}
7. Set Crawl Frequency
Determine how often the crawler should index your site. Depending on the frequency of content updates, you might want to set a daily or weekly crawl schedule. 🔝
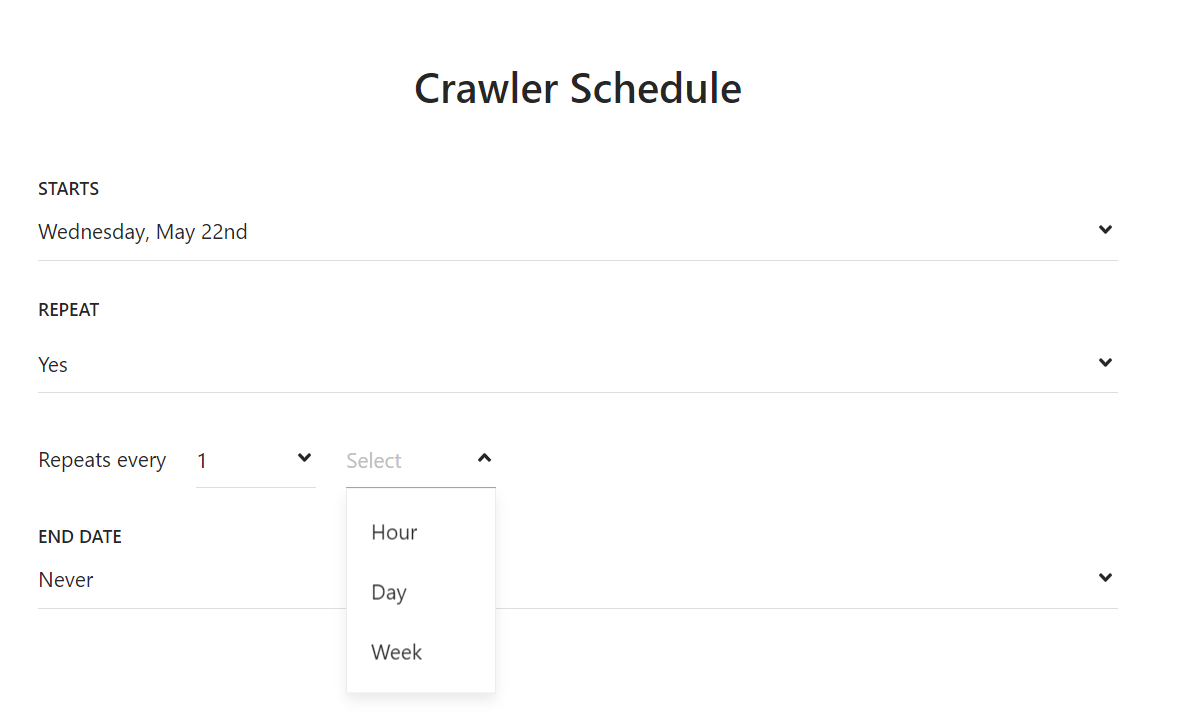
If you have frequent updates to your website or important announcements that need to be published immediately, then you have to write custom logic using Sitecore Search Ingestion API to push immediate changes.
8. Test the Configuration
Before going live, run a few test crawls to ensure that the configuration is working as expected. Check the indexed content to verify that all JavaScript-rendered elements are included. 🔝
🏃Optimizing Search Results
Use Metadata
Ensure that your web pages are well-structured with appropriate metadata. This helps the crawler understand the context and relevance of the content. 🔝
Implement Faceted Search
Faceted search allows users to filter results based on categories, tags, or other attributes. Configure faceted search in Sitecore to enhance the user experience.
Monitor and Adjust
Regularly monitor the performance of your search functionality. Use analytics to understand user behavior and adjust the crawler settings as needed to improve search accuracy.
💡Conclusion
By configuring Sitecore Search with an advanced web crawler and JavaScript document extractor, you can significantly enhance the search experience on your website. This setup ensures that all content, including dynamically generated elements, is indexed and searchable, providing users with accurate and comprehensive search results. Follow the steps outlined in this guide to optimize your Sitecore Search and deliver a superior user experience. 🔝
Remember to adjust these steps according to your specific use case. Happy crawling! 🚀
🙏Credit/References
🏓Pingback
| From Content to Commerce - Sitecore | Create a JavaScript document extractor with GLOB URL | Sitecore Search series |
| Getting to know Sitecore Search | Create an XPath document extractor for an advanced web crawler | Setting up Source in Sitecore Search |
| How To Setup A Sitecore Search Source | Configuring locale extractors | Coveo for Sitecore - Boost Sitecore Conversions |
| Sitecore search advanced web crawler with js extractor example | sitecore search api crawler | A Day with Sitecore Search |
| Mastering Website Content Indexing with Sitecore Search | What is Sitecore Search? : A Definitive Introduction | sitecore search advance web crawler |
| sitecore search engine | sitecore search index | sitecore search api |
| sitecore search facets | google site crawler test | index sitecore_master_index was not found |
| sitecore-jss | monster crawler search engine | online site crawler |
| sitecore searchstax | sitecore vulnerabilities | sitecore xconnect search indexer |
| Sitecore javascript services | Sitecore javascript rendering | sitecore search facets |
| sitecore jss github | sitecore xpath query | sitecore query examples |
| Sitecore graphql queries | sitecore elastic search | find sitecore version |
| how does sitecore search work | what is indexing in Sitecore Search? | Sitecore Search API |
| Sitecore Search API Crawler | Improve Sitecore Search |
Subscribe to my newsletter
Read articles from Amit Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Amit Kumar
Amit Kumar
My name is Amit Kumar. I work as a hands-on Solution Architect. My experience allows me to provide valuable insights and guidance to organizations looking to leverage cutting edge technologies for their digital solutions.As a Solution Architect, I have extensive experience in designing and implementing robust and scalable solutions using server-side and client-side technologies. My expertise lies in architecting complex systems, integrating various modules, and optimizing performance to deliver exceptional user experiences. Additionally, I stay up-to-date with the latest industry trends and best practices to ensure that my solutions are always cutting-edge and aligned with business objectives.