Troubleshooting K8's Common Errors
 Ashwin
AshwinImagePullBackoff Scenario
Suppose you have a Kubernetes cluster, and you've deployed a pod using the following YAML configuration:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app-container
image: myregistry/my-app:latest
In this scenario:
The
my-apppod is supposed to run a container namedmy-app-container, and it's attempting to use an image namedmyregistry/my-app:latest.However, when you check the pod's status using
kubectl get pods, you see that the pod is stuck in the "ImagePullBackOff" state, and it's not running as expected.
How to Fix the "ImagePullBackOff" Error:
To resolve the "ImagePullBackOff" error, you need to investigate and address the underlying issues. Here are steps to diagnose and fix the problem:
Check the Image Name:
- Verify that the image name specified in the pod's YAML file is correct. Ensure that there are no typos or syntax errors.
Image Availability:
Ensure that the container image
myregistry/my-app:latestexists and is accessible from your Kubernetes cluster. You can test this by trying to pull the image manually on one of your cluster nodes:docker pull myregistry/my-app:latestIf the image doesn't exist or isn't accessible, you'll need to build and push the image to your container registry or provide the correct image name.
Image Pull Secret:
If your container registry requires authentication, make sure you've created a Kubernetes secret that contains the necessary credentials and mounted it in your pod's configuration.
apiVersion: v1 kind: Secret metadata: name: my-registry-secret type: kubernetes.io/dockerconfigjson data: .dockerconfigjson: <base64-encoded-docker-credentials>Then, reference this secret in your pod's YAML under the
imagePullSecretsfield:spec: imagePullSecrets: - name: my-registry-secret
Network Connectivity:
- Ensure that the nodes in your cluster can reach the container registry over the network. Check for firewall rules, network policies, or other network-related issues that might prevent connectivity.
Registry Authentication:
- If your registry requires authentication, verify that the credentials provided in your secret are correct and up-to-date.
Registry Availability:
- Check if the container registry hosting your image is operational. Sometimes, registry outages or maintenance can cause this error.
Image Pull Policy:
Ensure that the pod's image pull policy is correctly set. The default value is "IfNotPresent," which means the image will be pulled if it's not already present on the node. If you want to force a pull every time, set the image pull policy to "Always."
spec: containers: - name: my-app-container image: myregistry/my-app:latest imagePullPolicy: Always
Permissions and RBAC:
- Verify that the ServiceAccount associated with the pod has the necessary permissions to pull images from the container registry. Incorrect Role-Based Access Control (RBAC) settings can block image pulling.
Logs and Events:
- Use
kubectl describe pod my-appto view detailed information about the pod, including events related to image pulling. Check the events and logs for any specific error messages that can help diagnose the problem.
- Use
Retry and Cleanup:
- In some cases, the "ImagePullBackOff" error may occur temporarily due to network glitches or transient issues. You can try deleting the pod and letting Kubernetes reschedule it. Use
kubectl delete pod my-appand monitor the new pod's status.
- In some cases, the "ImagePullBackOff" error may occur temporarily due to network glitches or transient issues. You can try deleting the pod and letting Kubernetes reschedule it. Use
CrashLoopBackOff Scenario
Suppose you have a Kubernetes cluster, and you've deployed a pod using the following YAML configuration:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app-container
image: myregistry/my-app:latest
In this scenario:
The
my-apppod is supposed to run a container namedmy-app-containerusing the imagemyregistry/my-app:latest.However, when you check the pod's status using
kubectl get pods, you see that the pod is stuck in a "CrashLoopBackOff" state, indicating that it keeps restarting and crashing.
How to Fix the "CrashLoopBackOff" Error:
To resolve the "CrashLoopBackOff" error, you need to diagnose and address the underlying issues that are causing the pod to crash repeatedly. Here are steps to troubleshoot and fix the problem:
View Pod Logs:
Start by inspecting the logs of the crashing container to identify the specific error or issue that's causing it to crash. You can use the following command to view the logs:
kubectl logs my-appExamine the logs for any error messages, exceptions, or stack traces that provide clues about what's going wrong.
Resource Constraints:
Check if the pod is running out of CPU or memory resources, as this can lead to crashes. Review the resource requests and limits specified in the pod's YAML configuration.
If necessary, adjust the resource requests and limits to allocate sufficient resources to the pod.
Example YAML:
resources: requests: memory: "128Mi" cpu: "250m" limits: memory: "256Mi" cpu: "500m"
Liveness and Readiness Probes:
Ensure that you have defined appropriate liveness and readiness probes for the container. These probes help Kubernetes determine whether the container is healthy and ready to receive traffic.
Review the probe configurations and adjust them as needed based on your application's behavior.
Example YAML:
readinessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 5 periodSeconds: 5
Check Application Code and Configuration:
Review your application code and configuration files for errors or misconfigurations that could be causing the crashes. Pay attention to environment variables, configuration files, and dependencies.
If necessary, update and redeploy your application code with fixes.
Image and Dependencies:
Verify that the container image (
myregistry/my-app:latest) is correct and compatible with the environment.Ensure that the container image and its dependencies are up to date. Sometimes, outdated dependencies can lead to crashes.
Container Entry Point:
- Check the entry point and command specified in the container image. Ensure that they are correctly configured to start your application.
Persistent Volume Issues:
- If your application relies on persistent volumes (e.g., for data storage), ensure that the volumes are correctly configured and accessible.
Permissions and Service Accounts:
- Verify that the ServiceAccount associated with the pod has the necessary permissions to access resources and dependencies required by your application.
Environmental Variables:
- Double-check any environmental variables that your application relies on. Ensure they are correctly set and pointing to the expected resources.
Retry and Cleanup:
- If the pod continues to crash, try deleting the pod (
kubectl delete pod my-app) and let Kubernetes recreate it. Sometimes, transient issues can be resolved by restarting the pod.
- If the pod continues to crash, try deleting the pod (
OOM Killed Scenario
Suppose you have a Kubernetes cluster running several pods and containers. You notice that one of your pods frequently goes into b the "OOMKilled" state, indicating that the container has exceeded its allocated memory and was terminated by the kernel.
You have a pod definition like this:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app-container
image: myregistry/my-app:latest
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
In this scenario:
The
my-apppod runs a container namedmy-app-container, using themyregistry/my-app:latestimage.The pod is configured with resource requests and limits for memory, with a request of 256MiB and a limit of 512MiB.
However, despite these resource settings, the pod frequently encounters OOM errors, resulting in container restarts and instability.
How to Fix the OOM Error:
To resolve the OOM error in Kubernetes, you need to take a systematic approach to address memory-related issues in your pod. Here's how to fix it:
Review Memory Usage:
Start by checking the memory usage of the container within the pod. Use
kubectl top podsto get memory usage statistics for your pods.kubectl top pods my-appInspect the container's memory usage and compare it to the specified resource requests and limits in the pod's YAML file. Identify if the container is consistently exceeding its allocated memory.
Adjust Resource Limits:
If the container is frequently exceeding its memory limit, consider increasing the memory limit to a value that meets your application's requirements. Be cautious not to set it too high, as it may impact the node's overall performance.
Example YAML:
resources: requests: memory: "256Mi" limits: memory: "1024Mi" # Increase the memory limit
Optimize Application Code:
Review and optimize your application code to use memory efficiently. Look for memory leaks, inefficient data structures, or unnecessary caching that could lead to excessive memory consumption.
Utilize tools like profiling and memory analysis to identify and resolve memory-related issues in your application code.
Implement Horizontal Pod Autoscaling (HPA):
If your application experiences variable workloads that result in memory spikes, consider implementing HPA to automatically scale the number of replicas based on memory utilization.
Example HPA configuration for memory-based autoscaling:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: my-app-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-app-deployment minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: memory targetAverageUtilization: 80Adjust the
targetAverageUtilizationbased on your desired memory utilization threshold.
Monitor Memory Usage:
Implement monitoring and alerting for memory usage in your Kubernetes cluster. Use tools like Prometheus and Grafana to set up memory-related alerts.
Configure alerts to notify you when memory usage approaches resource limits or becomes consistently high.
Vertical Pod Autoscaling (VPA):
Consider using Vertical Pod Autoscaling (VPA) to dynamically adjust resource requests and limits based on observed memory usage patterns. VPA can help optimize resource allocation.
Deploy VPA in your cluster and configure it to manage resource allocations for your pods.
Review Other Containerized Components:
- If your application relies on external components like databases, caches, or messaging systems, ensure that these components are also optimized for memory usage.
Heap Size and JVM Applications:
If your application is written in Java and runs in a JVM, configure the JVM heap size to stay within the allocated memory limits. Avoid setting the heap size to values that can exceed the container's memory limit.
Adjust the JVM heap size parameters in your application's startup script or Dockerfile.
Consider Cluster Scaling:
- If your cluster's nodes consistently run out of memory due to high resource demands, consider scaling your cluster by adding more nodes or using larger node types.
Troubleshooting and Debugging:
- If the issue persists, use debugging techniques like analyzing container logs, checking for memory leaks, and using Kubernetes debugging tools to get more insights into memory-related problems.
Kubernetes Admission Controllers
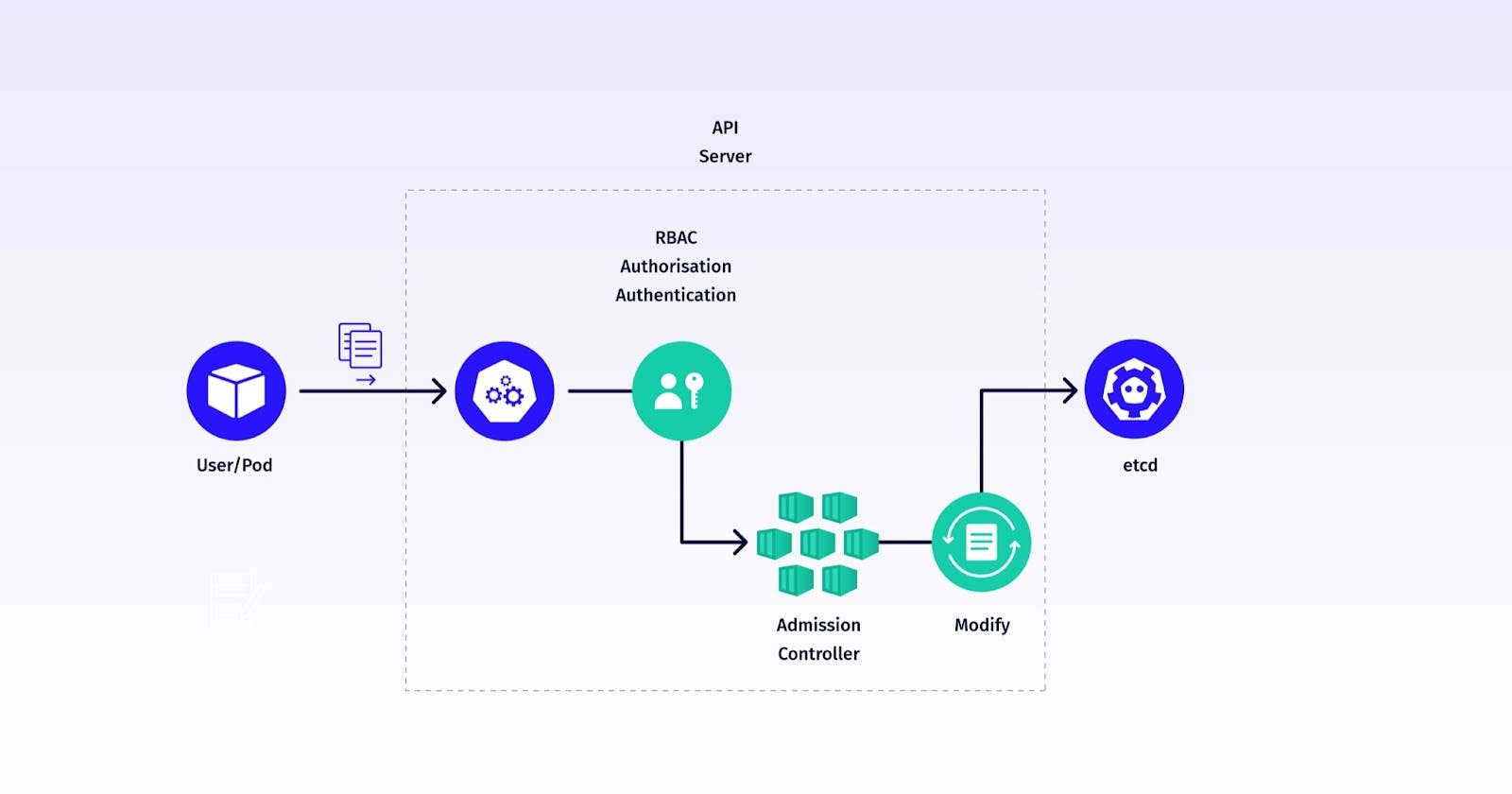
Mutating Admission Controllers
Purpose:
Mutating Admission Controllers intercept incoming requests to the Kubernetes API server and can modify the objects being submitted. Their primary purpose is to make automatic changes or additions to resources before they are persisted in the cluster.
Examples of Use Cases:
Default Values: You can use a mutating admission controller to automatically set default values for fields in resource configurations. For instance, you might want to set a default container image, environment variable, or labels for Pods if they are not explicitly defined by users.
Injection of Sidecar Containers: Mutating controllers are often used to inject sidecar containers into Pods. For example, an Istio sidecar for service mesh functionality can be automatically injected into Pods without requiring the user to specify it explicitly.
Automated Certificates: In a security context, a mutating controller can automatically generate and inject TLS certificates into pods for secure communication.
Validating Admission Controllers
Purpose:
Validating Admission Controllers intercept incoming requests and validate them against predefined policies or rules. They can either approve or deny a request based on whether it conforms to the established criteria.
Examples of Use Cases:
Resource Quotas: Validating controllers can enforce resource quotas, ensuring that users or namespaces do not exceed allocated CPU, memory, or other resource limits.
Pod Security Policies: You can use validating controllers to enforce security policies on Pods. For example, a policy might require that Pods run with non-root user privileges or disallow the use of host networking.
Network Policies: Network policies can be enforced using validating controllers to ensure that network communication between Pods adheres to specified rules, such as allowing or denying traffic based on labels and namespaces.
Key Differences
Mutation vs. Validation:
- Mutating controllers modify or mutate the object being submitted while validating controllers only validate and either approve or deny the request without making changes.
Order of Execution:
- Mutating controllers run before validating controllers in the admission control chain. This means they can modify objects before validation occurs.
Effect on Requests:
Mutating controllers can transform requests into a different state by adding or changing values, making them compliant with certain policies.
Validating controllers primarily enforce policies and constraints, rejecting requests that do not meet criteria.
Examples:
Mutating Controller Example: Let's say you have a mutating controller that automatically adds an annotation to every Pod resource to track the creator. When a user creates a Pod, this controller intercepts the request and adds an annotation like "created-by: <username>" to the Pod specification before it's persisted in the cluster.
Validating Controller Example: Consider a validating controller that enforces a policy requiring all Pods to have a label specifying their environment (e.g., "dev," "staging," or "prod"). If a user tries to create a Pod without this label, the controller will deny the request, ensuring that all Pods adhere to the labeling policy.
In summary, Mutating Admission Controllers modify objects before they are stored in the cluster, often for automation and policy enforcement purposes. Validating Admission Controllers, on the other hand, validate requests against policies and enforce constraints without changing the objects. Together, these controllers allow you to implement a wide range of custom policies and automation in your Kubernetes cluster to ensure it runs securely and efficiently.
Subscribe to my newsletter
Read articles from Ashwin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ashwin
Ashwin
I'm a DevOps magician, conjuring automation spells and banishing manual headaches. With Jenkins, Docker, and Kubernetes in my toolkit, I turn deployment chaos into a comedy show. Let's sprinkle some DevOps magic and watch the sparks fly!