Music Streaming Platform : System Design
 YASH HINGU
YASH HINGU
We're gearing up to create an article that closely mirrors a real-world scenario. Here's the game plan: first, we'll gather all the business requirements, both functional and non-functional. Then, we'll use our expertise to whip up some rough technical estimates for the system—think "back-of-the-envelope calculations." After that, we'll sketch out the core architecture and API to support those functional requirements. Finally, we'll gradually scale the system to meet all the non-functional requirements, keeping an eye out for potential pitfalls and trade-offs. Let's dive in!
Functional Requirements (FR)
Music streaming services, of course, come with a lot of functionality. We will limit our discussion to core features:
Music streaming
Music management (uploading, storage, removal)
Music search
Non-Functional Requirements (NFR)
These are the requirements for how effectively our service meets its functional requirements.
Here are some external requirements we receive from the business or interviewer:
Scalability. We aim for a globally used system, expecting up to 1 billion active users. By “active users,” we mean daily active users (DAU). This number is even greater than what YouTube typically sees.
Latency. Latency is the time it takes for a user's request to be processed and the response to be returned. It is crucial for users to start listening to audio as soon as possible; hence, we aim to keep latency below 200 ms.
Storage. We plan to store 100 million tracks
Minimum Viable Product (MVP)
Let's outline our design! I like to start with something as simple as possible that covers the functional requirements. From there, we'll gradually improve the design to meet all the requirements.
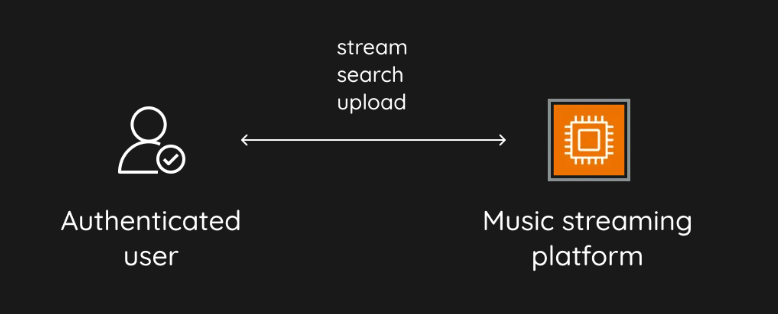
As basic as it may seem, this setup is exactly what the user sees. Essentially, we have a black box hiding all the logic, with the user interacting with it. This approach incorporates all the functional requirements and helps us stay focused. Now, let's peel back the layers.
Data Storage

Once a request arrives at our service, it needs to retrieve data. We need to keep this data in some sort of dedicated storage. To be thorough, you might consider explaining why we can't store data inside the service's file system. For instance, because the service needs to be easily redeployable and scalable.
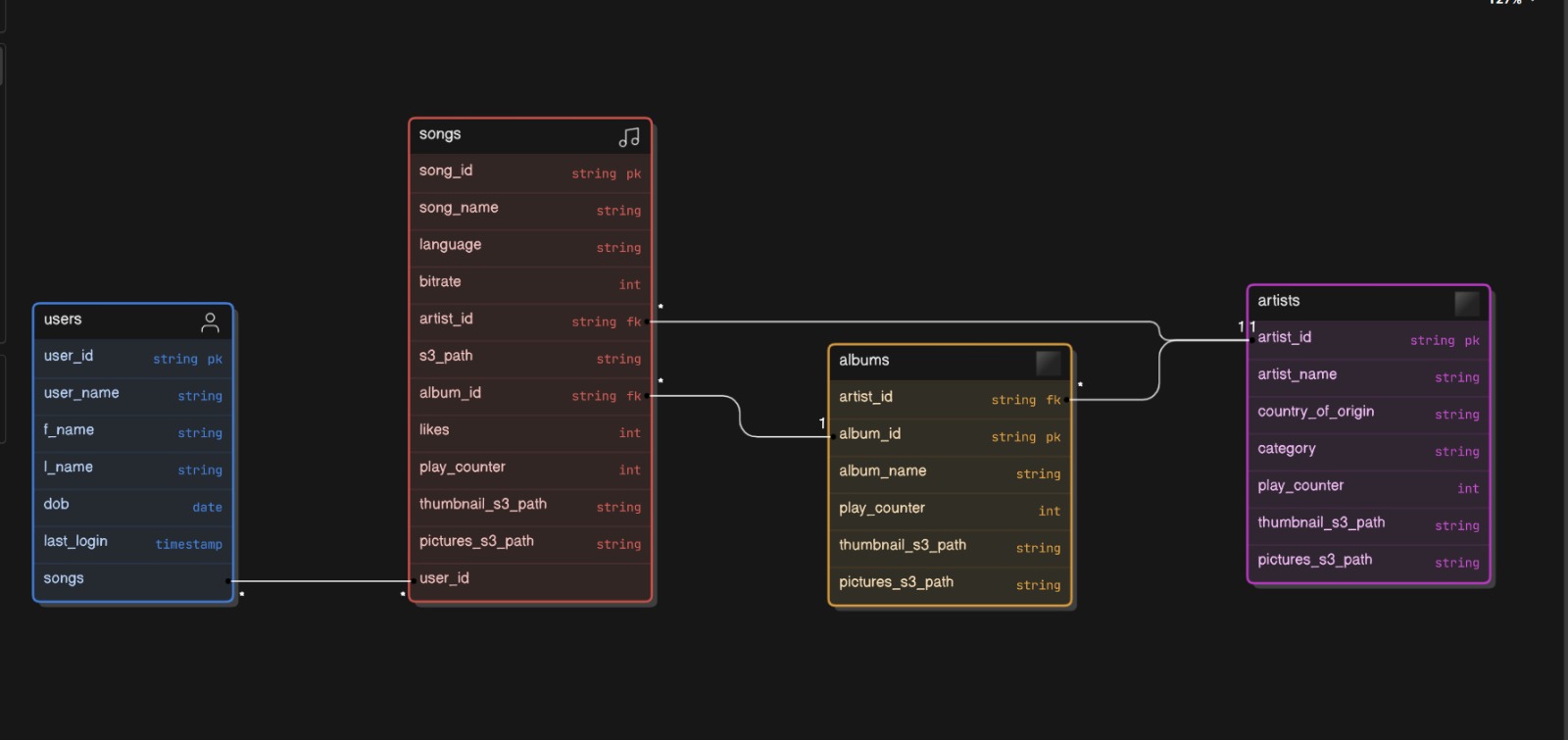
Next, let's decide on the type of storage we need. We need to think about our business domain and the entities we're working with. In this case, we're dealing with music or other audio data, typically stored as blobs in formats like WAV, MP3, and so on. However, this alone isn't sufficient, as our users will also need the track's name, author, description, subtitles, and more. To manage this data efficiently, we'll need to store this information under a unique track ID.

Considering these properties, we see that the audio data itself is quite different from the data describing it, also known as metadata. Storing blobs in a traditional database would significantly decrease performance and increase costs. There's a good article explaining why. So, it would be more efficient to store the blob data in an object storage, which is highly optimized for it, while the more structured and less voluminous metadata and profile data will be stored in a database.
Now let's discuss some of the entities we will focus on:
User: The actual user of the app, most likely having attributes such as name and email. I do not mention fields like subscription type or password hash, as we have intentionally left them out of scope.
Track: Consists of a blob and metadata, as we have discussed. It may include fields such as title, duration, and a link to the actual location of the blob in object storage.
Artist: A band or individual who uploads tracks. May include fields like name, biography, country, etc.
Album: A collection of tracks by an artist, with properties such as title, genre, release date, etc.
Playlist: A compilation of tracks generated by a user, platform administrators, or a suggestions algorithm. May have fields like title, and whether it is public or private, among others.
I omitted supplementary columns like "created_at", "updated_at", and "deleted_at", although they are implied by default for efficient retrieval and indexing.
This is our architecture so far:
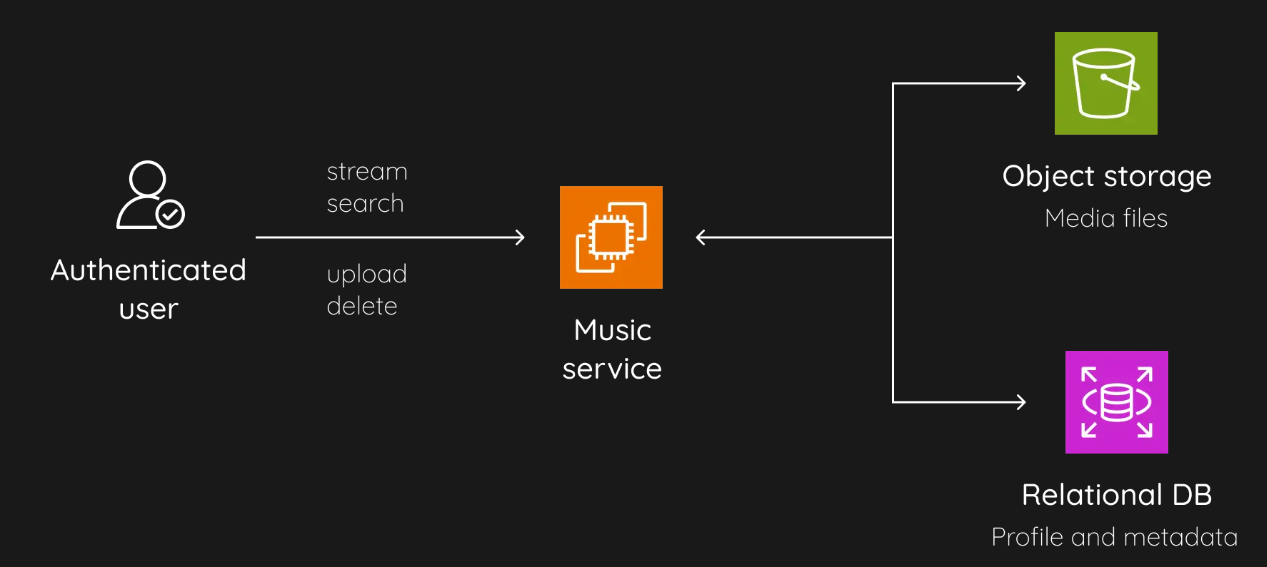
However, every choice comes with its trade-offs. By opting for a relational database, we also inherit all its challenges, such as difficult horizontal scaling and additional overhead for query processing to maintain ACID compliance.
Streaming

Streaming is the heart of our system. Sending the entire file over the network as a response isn't very effective. It might take several seconds for the full file to download before it starts playing, which is way more than the 200ms latency we aim for. So, how do we maintain low latency and ensure smooth audio playback, especially if the user has a low-performance device or poor network connectivity?
Thankfully, modern streaming platforms use high-performance protocols for this. These protocols include Adaptive Bitrate Streaming (ABR), which allows the streaming service to provide a smooth listening experience even with network fluctuations or consistently low bandwidth.
There are two widely adopted protocols: HTTP Live Streaming (HLS) by Apple and the open-source MPEG-DASH (Dynamic Adaptive Streaming over HTTP). However, MPEG-DASH is not supported by Apple devices.
These protocols work by breaking the audio stream into a sequence of small, HTTP-based file downloads, each containing a short segment of the audio stream, usually lasting 2-10 seconds. For instance, MPEG-DASH provides an XML manifest file listing various bitrates that the client can request.
The client's media player reads the manifest file and decides which quality level to download based on the current network conditions, CPU usage, and buffer status. The client fetches the segments sequentially via HTTPS GET requests and plays them back without interruption. If a quality adjustment is needed, it switches to a higher or lower quality stream by selecting segments from the respective stream as indicated in the manifest.
HTTP/2 helps reduce the overhead of new network connections by multiplexing requests and responses over a single long-lived connection.
Computing Layer

With these numbers, our current prototype will work just fine. A well-optimized single server instance can handle 100 RPS with ease. However, this server is a single point of failure. We need to keep our system available in case a server breaks for some reason. For that, we will keep two instances of the service on two machines. In case of server fault, we can have an auto-restart mechanism and some monitoring and alerting system integrated so that engineers are notified about the problems.
One thing I intentionally skipped in the MVP section is music preprocessing. As we mentioned in the estimations part, audio files should be compressed to reduce their size for streaming. Different devices may support different audio formats, hence the need to store several lossy compression formats: AAC for iOS devices, MP3 for broad compatibility, OGG for certain browsers. This process is called encoding. On top of that, we need to serve each format in multiple bitrates suitable for HLS or MPEG-DASH. This process is called transcoding.
So, we add two service workers called transcoder and encoder forming a processing pipeline to our design. The encoder service will also post new file metadata and its location in the object storage to the SQL database. With these we address both increase availability and decrease latency.
In theory, we could have a live transcoder setup, but it would significantly increase the latency of our service and require substantial computing resources. Instead, we will opt to pay more for storage and process the music preemptively in the background, benefiting from faster start times for playback and minimized buffering.
Data Layer
We successfully reduced the load on our computing components, but what about storage? Both of our servers will end up constantly connecting to a single database instance. Establishing a new connection for each request is costly, so to reduce latency, a better approach is to use connection pooling.
Since the database and object storage are stateful, keeping a second instance for redundancy at this point seems to be relatively costly. At this scale, it is arguably easier to make backups every couple of hours compared to configuring read replicas, as it comes with new challenges that we will discuss later. The actual backup strategy will depend on the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) that the business can tolerate.
Although 100 connections for streaming with potential bursts may seem high for a single database, they will go to our object storage instead, which is well-optimized for it.
To decrease latency, we should also think about properly indexing our database. Most probably, we will index tracks and albums based on their "name" and "created_at" fields for efficient searching. Other indexes may also be applied based on specific use cases of your app. However, remember that using indexes too much can negatively impact write performance and significantly affect query performance.
Network Layer
To distribute the traffic between two server instances, we need a load balancer. Whenever we introduce a load balancer (LB), it is good practice to discuss the algorithms for distributing traffic and the level at which they operate. By level, we mean the layers in the OSI model. LBs can generally operate at two levels: L4 — network and transport level, routing based on TCP/IP; and L7 — application level, routing based on HTTP. If you are not familiar with LB concepts, you may find this quick intro helpful.
In our case, a simple L4 round-robin LB will suit our needs. Round-robin is simple to work with, and L4 is faster and more appropriate as we don’t have to distribute traffic based on information in the HTTP requests. We don't need sticky sessions either as the streaming will be held by the object storage. The LBs can also be either hardware or software, with hardware-based being more robust and performant but more expensive. In our case, a software LB (like HAProxy) is better, as the load is relatively small and it is more configurable.
We should also outline a network boundary to emphasize the private network, accessible from the outside only through the load balancer or another reverse proxy. Speaking of which, although the client connects to the reverse proxy using HTTPS, it is good practice to enable TLS termination to increase the speed of communication inside the cluster by avoiding encryption-decryption overhead.
Another point to mention is that our transcoder and encoder need to communicate with one another to form a pipeline for audio processing. They perform their jobs at different speeds and need to communicate asynchronously. The best way to achieve this is by using a Message Queue (MQ).
Lastly, for the sake of completeness, I will also add the Domain Name System (DNS), as it is the first component in the user request flow to interact with and essential for converting a domain to an actual IP address of our reverse proxy.
Security
Before we delve further, let's briefly discuss security. Although security is not our primary focus, it is crucial to address it. We have already decided that the authentication and authorization logic will be abstracted as a service. It is good practice to include this in our design. We will represent it as a "black box" in our schema. It could be anything from an enterprise SAML SSO solution to a third-party provider built on OpenID and OAuth 2.0 protocols. Regardless of the actual implementation, we assume that after providing valid credentials, the user receives either a stateless token, like a JSON Web Token (JWT), or a stateful session ID.
This AuthN/AuthZ service will be operational within our cluster. The backend service will contact it for each request (perhaps through middleware) to validate the token and introspect it to obtain the user ID. The token will also enable us to provide Role-Based Access Control (RBAC) for the music, since every authenticated user can stream the music, but only artists can upload and delete tracks.
Security itself is a vast topic, so I leave other intriguing aspects like OWASP Top 10, DoS protection, intrusion detection systems, poisoned pipeline execution, and many more for your own exploration.
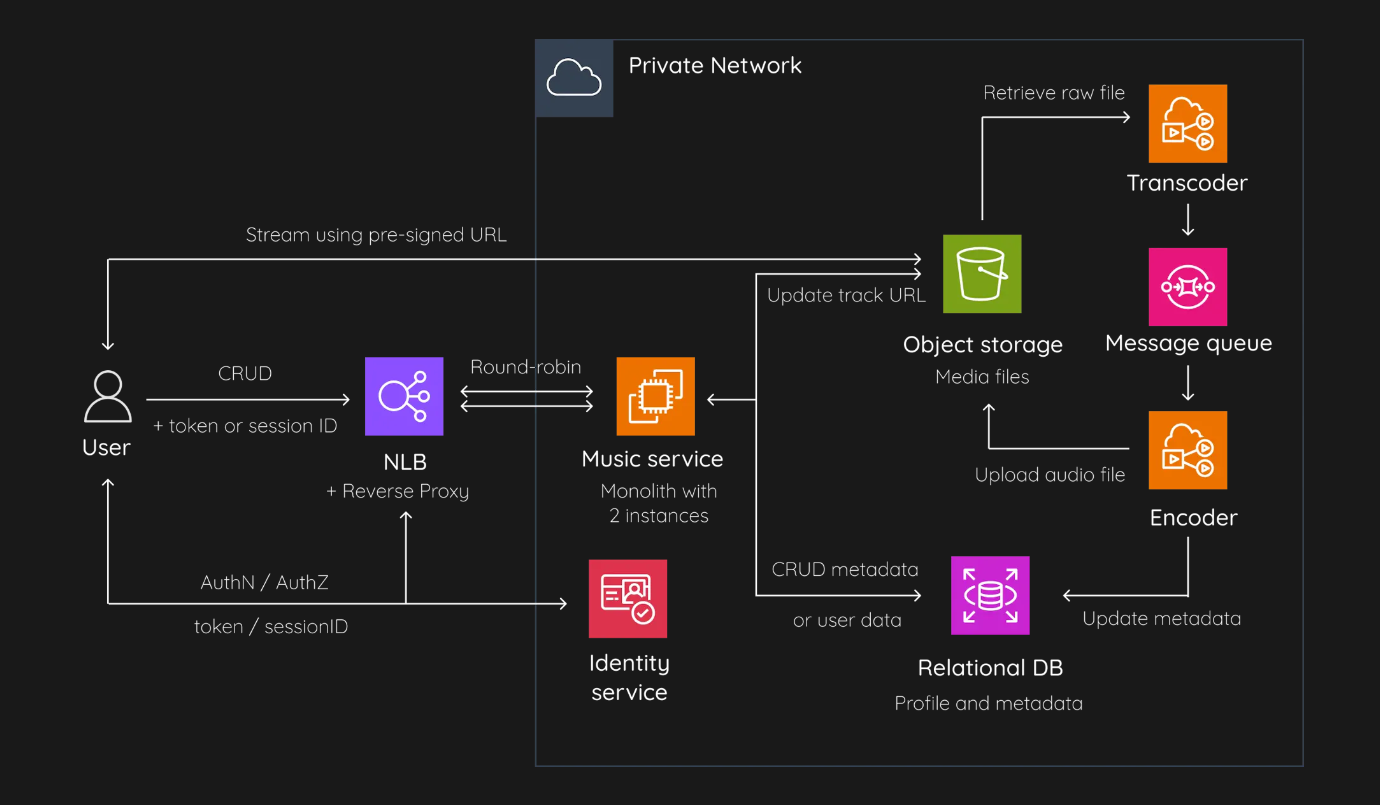
Certainly! The components in the architecture of a private network for music streaming services are designed to work together to provide a secure and efficient music streaming experience. let's understand each component and its purpose:
User:
This is where the interaction with the system begins. The user accesses the music streaming service, typically through an application or website, using authentication credentials.
The flow begins when a user initiates a request to stream music. This request is sent from the user’s device to the Nginx server.
Reverse Proxy:
directing client requests to the appropriate music service backend. It helps in load balancing, provides SSL termination, and enhances security by protecting internal network structures.
It determines the best music service instance to handle the request based on load balancing algorithms and forwards the request accordingly.
Music Services:
These are scalable backend services that handle all music-related functionalities, such as streaming, playlists, and user preferences.
The selected music service instance processes the request. If it involves streaming a track, the service checks if the user is authorized by communicating with the Identity Service.
Identity Service:
This service manages user identities, authentication, and authorization. It ensures that only authenticated users can access the service and that they have the correct permissions.
The Identity Service validates the user’s credentials and permissions. If the user is authenticated and authorized, it sends a confirmation back to the Music Service.
Update Track URL:
- This process updates the URLs for tracks to ensure that users have access to the latest and most accurate links for streaming or downloading music.
Retrieve Raw File:
This component is responsible for obtaining the raw audio files from the storage before they are processed for streaming.
Once the user is authorized, the Music Service requests the track from the Object Storage. If the track needs to be transcoded or encoded for the user’s device, it sends the raw file to the Transcoder.
Transcoder:
The transcoder converts raw audio files into different formats suitable for streaming across various devices and network conditions.
The Transcoder receives the raw file and converts it into the appropriate format. The transcoded file is then placed in the Message Queue for delivery.
Message Queue:
It organizes tasks and processes them in a sequential manner. This helps in managing the load and ensuring smooth operation of the transcoding process.
The Message Queue manages the delivery of the transcoded file to the user. It ensures that the files are sent in the correct order and handles any necessary retries.
Object Storage:
- This is where the media files are securely stored. It allows for the scalable and reliable storage of large amounts of data.
Encoder:
- The encoder processes the audio data to ensure consistency and compatibility across different playback devices.
Relational and Metadata Database (MDB):
- This database stores structured data related to users, tracks, and other metadata. It supports complex queries and transactions necessary for the music service.
The final transcoded and encoded music track is sent back through the Nginx server to the user’s device.
Handling Growth: Scaling Strategies for 10K-100K Users and 1M Tracks
Alright, let's dive into how our system will handle growth with such a significant user base and a whopping 1 million tracks!
Data Layer
Starting with our data layer, 2 GB of data isn't too much for a database to handle, but handling 1K read RPS is quite a task for a single database, especially during peak hours.
To tackle this, let's split up our profile and metadata into two databases since they're accessed differently. Music info gets hit way more than user data, and reads happen a lot more often than writes. So, we can optimize the workload by introducing read replicas for metadata.
But what about keeping everything consistent? According to the CAP theorem, we have to make a choice between consistency or availability. In the context of our music app, it's reasonable to go with eventual consistency for read replicas. This means updates might take a little time to show up everywhere. For fault tolerance, we can also add a standby replica that gets data in sync with the primary one.
Computing Layer
Now, onto the computing side. With such a load, if one server goes down, the other might get overwhelmed, especially during busy times. Solution? Add more servers! But managing lots of servers manually is a pain. That's where microservices come in. Splitting our monolithic service into smaller bits lets us scale better and work more efficiently.
Think of it like this: one service handles music search, another does streaming, another deals with uploads, and so on. It's like having specialized teams for different tasks.
Network Layer
Now, for smooth traffic handling between our microservices, we need an API Gateway. It's like the gatekeeper to our system, sorting out who gets what. Plus, we need to make sure a disaster in one zone won't bring everything crashing down. So, let's set up another data center far away and use a Network Load Balancer to spread the load.
And let's not forget security! We need a reverse proxy to keep things safe, doing stuff like controlling how fast requests come in and out and keeping an eye out for anything fishy.
Caching
Lastly, to keep things zippy, we'll use caching at different layers. We'll cache stuff like user data right on their devices, use CDNs to stash audio files close to users, and keep frequently used data in memory caches.
With these strategies, our system is primed to handle up to 100,000 users and keep those 1 million tracks streaming smoothly!
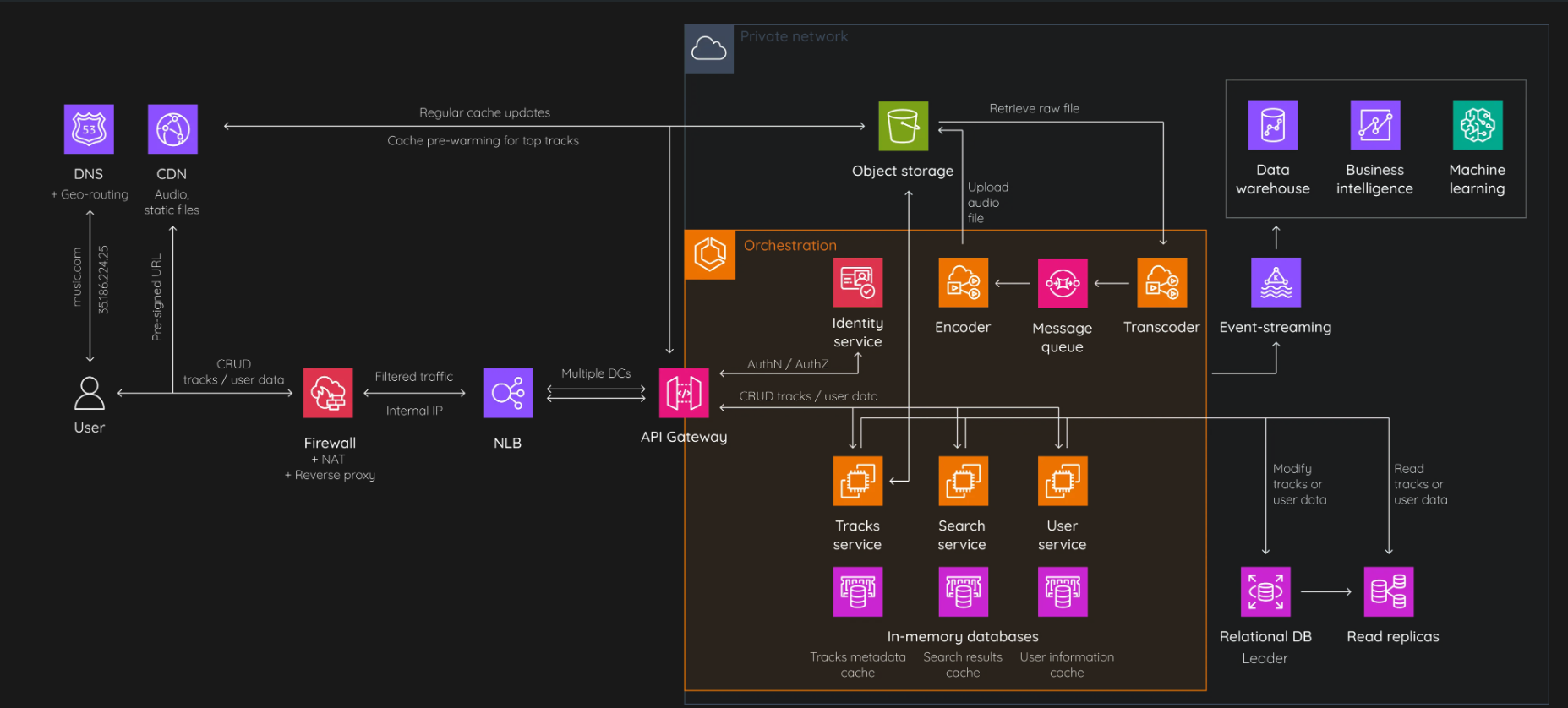
This is Our System Design of Music Streaming App.
Subscribe to my newsletter
Read articles from YASH HINGU directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by