Exploratory Data Analysis-Part 1
 Arnab Bhowmik
Arnab Bhowmik
What is Exploratory Data Analysis?
Exploratory data analysis is one of the basic and essential steps of a data science project. A data scientist involves almost 70% of his work in doing the EDA of the dataset. In this article, we will discuss what is Exploratory Data Analysis (EDA) and the steps to perform EDA.
Exploratory Data Analysis or (EDA) is understanding the data sets by summarizing their main characteristics often plotting them visually. This step is very important especially when we arrive at modeling the data in order to apply Machine learning.
How to perform Exploratory Data Analysis ?
This is one such question that everyone is keen on knowing the answer. Well, the answer is it depends on the data set that you are working.
What data are we exploring today ?
In this article, the data to predict Used car price is being used as an example. In this dataset, we are trying to analyze the used car’s price and how EDA focuses on identifying the factors influencing the car price.
Let’s look at how to perform EDA using python!
Tools for Performing Exploratory Data Analysis
Pandas: Provides extensive functions for data manipulation and analysis, including data structure handling and time series functionality.
Matplotlib: A plotting library for creating static, interactive, and animated visualizations.
Seaborn: Built on top of Matplotlib, it provides a high-level interface for drawing attractive statistical graphics.
Plotly: An interactive graphing library for making interactive plots
Types of Exploratory Data Analysis
EDA, or Exploratory Data Analysis, refers back to the method of analyzing and analyzing information units to uncover styles, pick out relationships, and gain insights.
1. Univariate Analysis
Univariate analysis focuses on a single variable to understand its internal structure. It is primarily concerned with describing the data and finding patterns existing in a single feature. This sort of evaluation makes a speciality of analyzing character variables inside the records set.
2. Bivariate Analysis
Bivariate evaluation involves exploring the connection between variables. It enables find associations, correlations, and dependencies between pairs of variables. Bivariate analysis is a crucial form of exploratory data analysis that examines the relationship between two variables.
3. Multivariate Analysis
Multivariate analysis examines the relationships between two or more variables in the dataset. It aims to understand how variables interact with one another, which is crucial for most statistical modeling techniques.
Specialized EDA Techniques
In addition to univariate and multivariate analysis, there are specialized EDA techniques tailored for specific types of data or analysis needs:
Spatial Analysis: For geographical data, using maps and spatial plotting to understand the geographical distribution of variables.
Text Analysis: Involves techniques like word clouds, frequency distributions, and sentiment analysis to explore text data.
Step-by-Step Exploratory Data Analysis (EDA)
Step 1: Import Python Libraries
Import all libraries which are required for our analysis, such as Data Loading, Statistical analysis, Visualizations, Data Transformations, Merge and Joins, etc.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#to ignore warnings
import warnings warnings.filterwarnings('ignore')
Step 2: Reading Dataset
The Pandas library offers a wide range of possibilities for loading data into the pandas DataFrame from files like JSON, .csv, .xlsx, .sql, .pickle, .html, .txt, images etc. In this post, the data to predict Used car price is being used as an example. In this dataset, we are trying to analyze the used car’s price and how EDA focuses on identifying the factors influencing the car price. We have stored the data in the DataFrame data.
data = pd.read_csv("used_cars.csv")
Analyzing the Data
The main goal of data understanding is to gain general insights about the data, which covers the number of rows and columns, values in the data, datatypes, and Missing values in the dataset.
head() will display the top 5 observations of the dataset
data.head()
tail() will display the last 5 observations of the dataset.
data.tail()
info() helps to understand the data type and information about data, including the number of records in each column, data having null or not null, Data type, the memory usage of the dataset.
data.info()
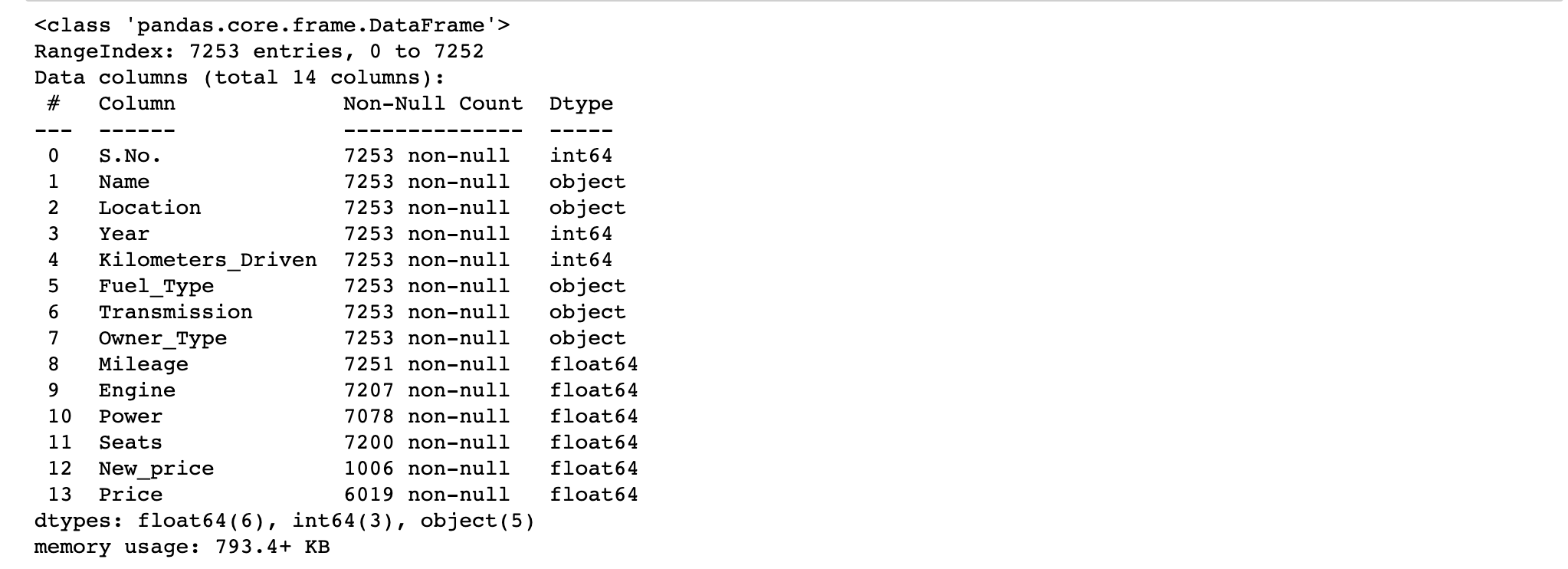
data.info() shows the variables Mileage, Engine, Power, Seats, New_Price, and Price have missing values. Numeric variables like Mileage, Power are of datatype as float64 and int64.
Categorical variables like Location, Fuel_Type, Transmission, and Owner Type are of object data type.
Missing Values Calculation
isnull() is widely been in all pre-processing steps to identify null values in the data.
data.isnull().sum()
Step 3: Data Reduction
Some columns or variables can be dropped if they do not add value to our analysis. In our dataset, the column S.No have only ID values, assuming they don’t have any predictive power to predict the dependent variable.
# Remove S.No. column from data
data = data.drop(['S.No.'], axis = 1)
data.info()
Step 4: Feature Engineering
Feature engineering refers to the process of using domain knowledge to select and transform the most relevant variables from raw data when creating a predictive model using machine learning or statistical modeling. The main goal of Feature engineering is to create meaningful data from raw data.
Step 5: Creating Features
We will play around with the variables Year and Name in our dataset. If we see the sample data, the column “Year” shows the manufacturing year of the car. It would be difficult to find the car’s age if it is in year format as the Age of the car is a contributing factor to Car Price.
Step 6: Data Cleaning/Wrangling

data["Brand"].replace({"ISUZU": "Isuzu", "Mini": "Mini Cooper","Land":"Land Rover"},inplace=True)
We have done the fundamental data analysis, Featuring, and data clean-up. Let’s move to the EDA process.
Voila!! Our Data is ready to perform EDA.
Stay Tuned for Part 2.
Subscribe to my newsletter
Read articles from Arnab Bhowmik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arnab Bhowmik
Arnab Bhowmik
Noob programmer & problem solver.