TinyML (Part 1)
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim Mitul
Let's learn it by its application:
You may have said "Hey siri" to your apple devices

Some applications of Tinyml nowadays:

But imagine smart glasses in the future. Imagine a situation where you go out into the mall, or marketplace, or you're at a party. And how many times have you had to say, I'm sorry, could you repeat that again, right?
Imagine if these glasses had contextual hearing. In other words, they're able to see where you're glancing. And then based on that, be able to pick up the voice signals or the sound signals that are coming there and then amplify them so that only the things that are in your context will actually be richer.
That way, you have a better experience, right? Or imagine, for instance, you're in a new country and someone's talking to you in a language that you don't know. And imagine your glasses are able to do real-time machine translation and then be able to feed it into your brain. These are some remarkable applications. Or let's talk about TinyML in the medical area. Here, I'm showing you Micra, which is from Medtronic. It's the world's smallest pacemaker that goes into your heart. It's small, it's non-invasive, and it's completely self-contained. And if this device had machine learning in it, it would be able to, perhaps, proactively tell you how your heart's doing or be able to do things for you so that you have a better, healthy life choice.
Or let's talk about what Elon Musk is doing, where he's implanting chips inside the brain so that they can send signals to understand brain activity. By measuring the electrical signals that are emitted by neurons, we might be able to learn things about our brain. And in doing so, we might be able to cure diseases like treat depression, insomnia, or any other disease.
Some motivation to learn TinyML:

Let's start
Once we use Tinyml in every single small IOT devices, this is what we have to deal with everyday

Let's break a scene:
Once you say Ok , google

- The machine picks your voice at first
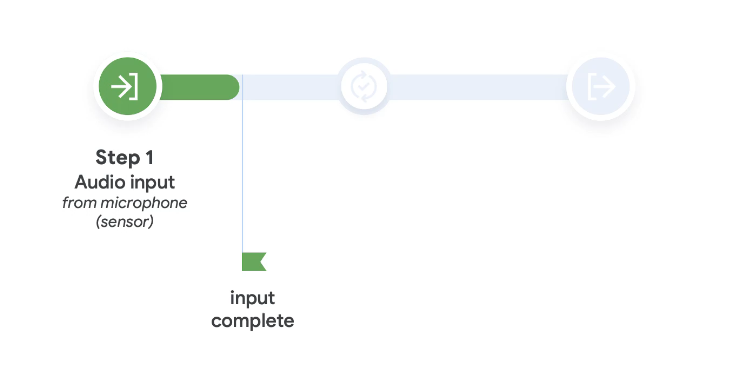
In input, we can have sensors from so many different types

For example, here is a biometric sensor

- Then it processes
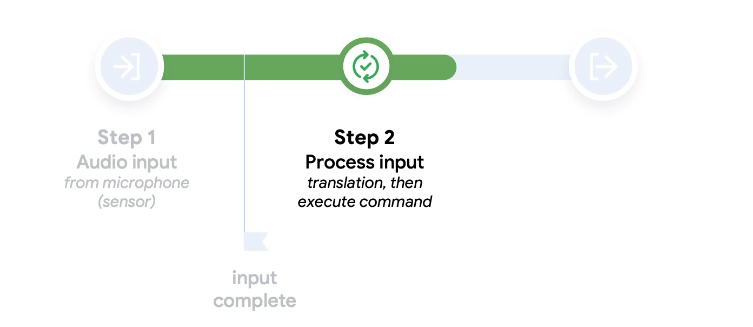
Here let's compare how much bigger cpu we need. This is the normal CPU

It takes around this much space

Whereas an Apple chip is much smaller than that

Like this

Then we have smartwatches which has even smaller cpus

It has very tiny cpu

We have even more small cpus like this

For comparison, this is a chip kept on a golf ball

You can see how smaller they are
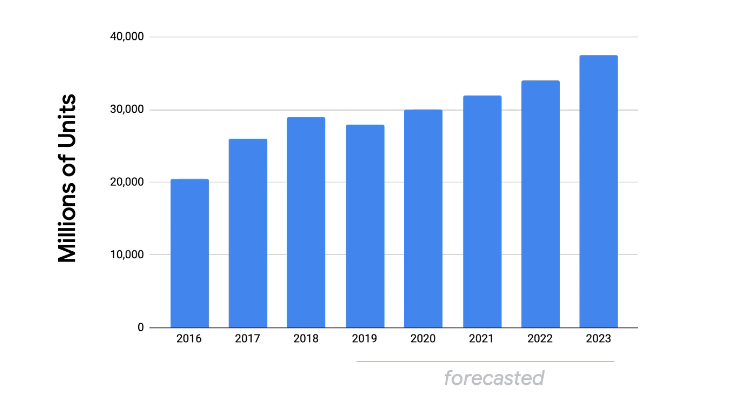
Check the amount of chip vs years
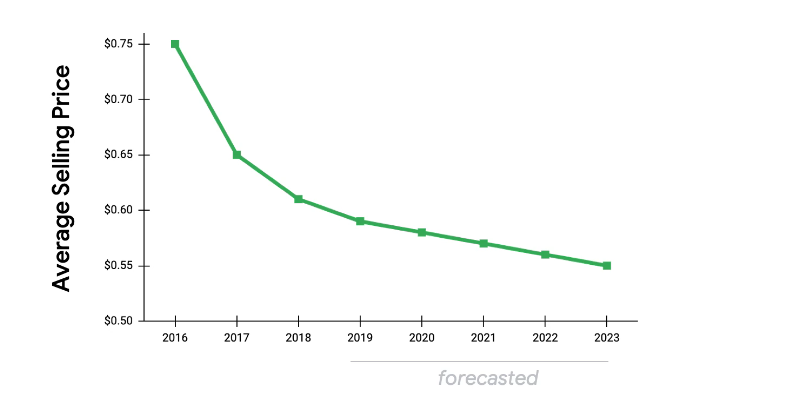
- The price will drop gradually
- then it gives some output
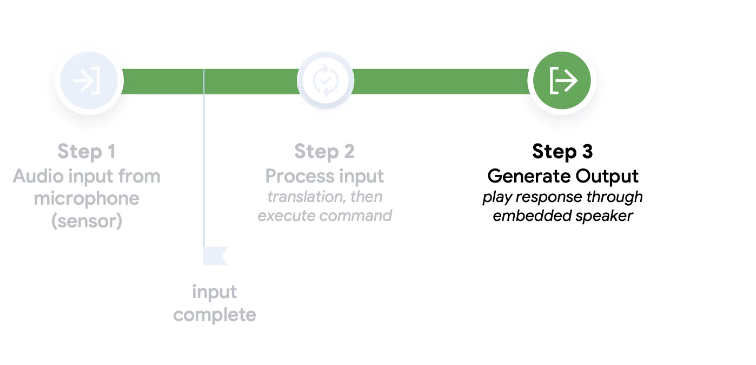
here the outpu can be shown to screen or can be heard.
So, what are the challenges of TinyML?
As we are dealing with Microcontrollers , it's a fixed object and therefore we need to keep in mind the pros of cons of it.

Another issue is protability issue
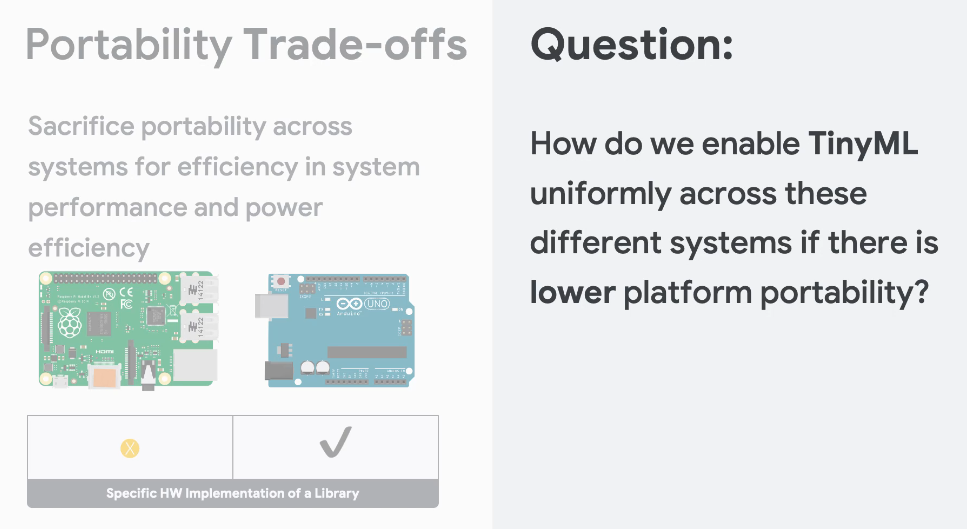
We need to handle how we are going to enable the code in all embedding systems!

So, there are 2 issues we need to work on!
What are the challenges for TinyML?
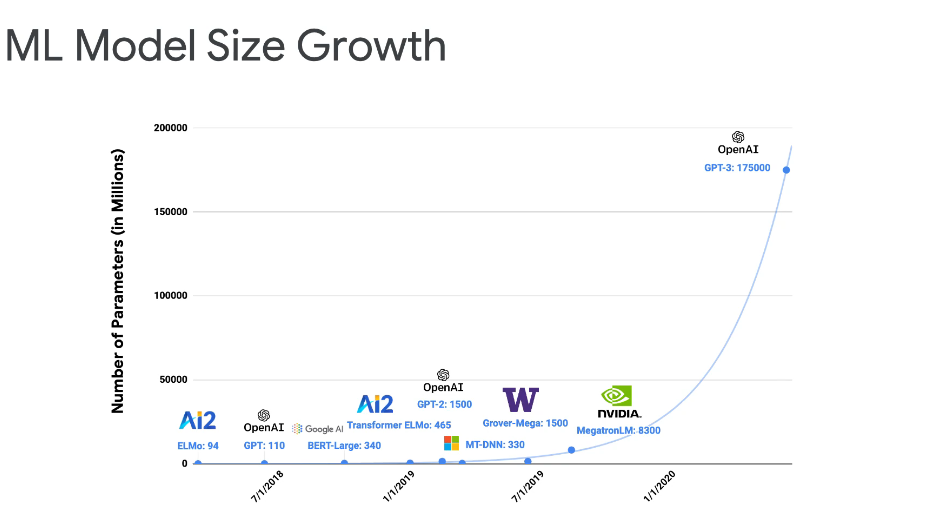
Over the years, the ML models are having much more parameters and need much more power and support for that.
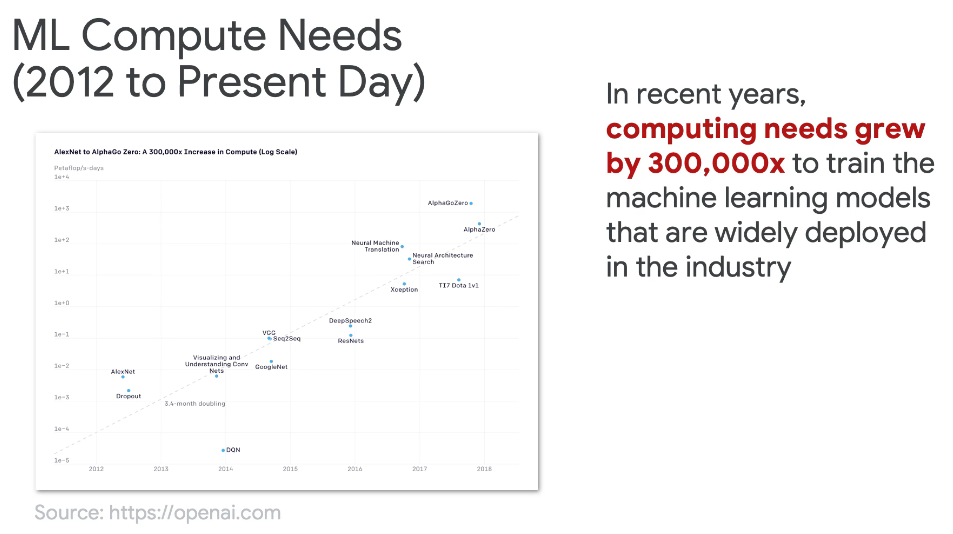
Here if we check this model, which requires 16.9 MB size whereas an embedding system in general is much smaller (256 KB of ram)

So, it's very tough for us to find new ML models which can fit our embedding systems.
So, to solve these issues, we will compress our ML Algorithms

Pruning
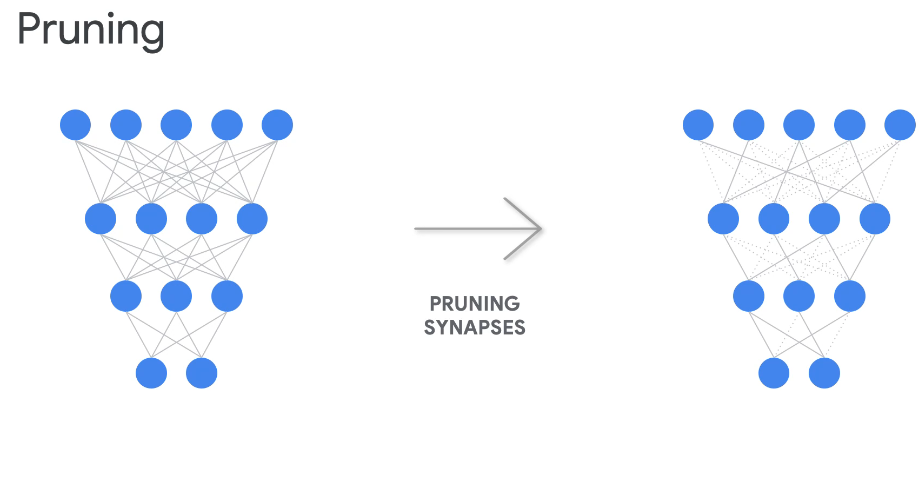
With pruning, we are removing some connections.
We can also remove some neurons

Quantization
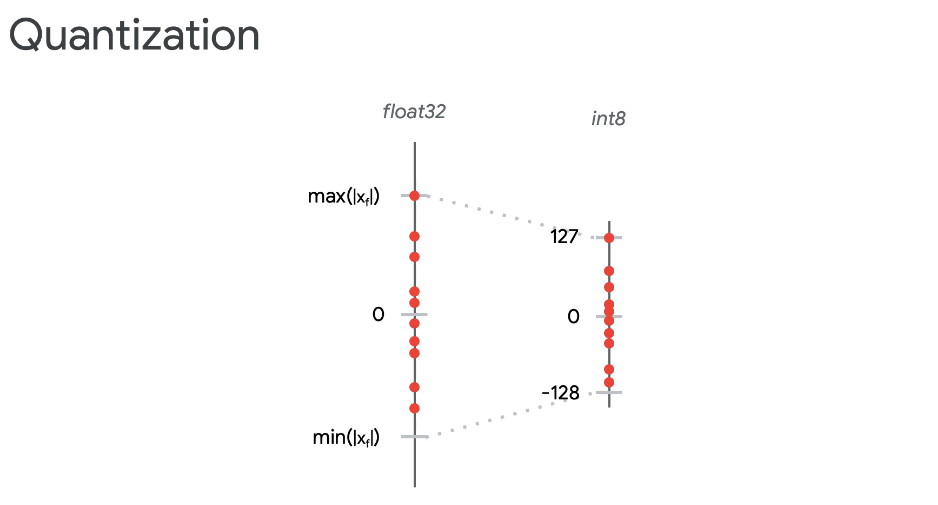
You take that floating point value, which is a long number of digital decimal places in place. And you quantize it down. Quantization means discretizing the values down to a small subset of values. So here, the end eight is basically going from negative 128 to 127, which allows you to represent 256 values.
Now because you are now only having 256 values, you have to shrink that whole range down, which means you might lose some sort of values that would otherwise be represented in a floating point value.
Why in the world would I ever want to do that?
Well, a floating 0.32 bit value takes a whole four bytes to represent-- four bytes. Versus an end eight value is simply one byte, which means I get a 4x reductions by simply doing the quantization which is a huge boom or boost in the model size.
Knowledge distillation
Knowledge distillation is a really nice fancy buzzword for explaining how a teacher, who knows a lot from years of wisdom and has a lot of information, is able to distill down the critical information for the student without losing the nugget given a particular task.
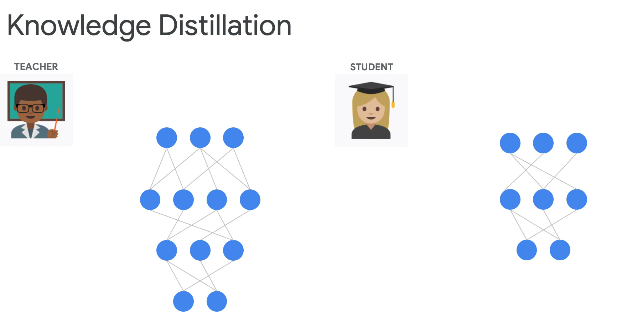
So the benefit of this, ultimately, is that a teacher network might be big. A student network might be small.
When you have this big cloud TPU in its Google building, where they want to be able to run many different kinds of machine learning tasks, for instance, you need a framework, a software framework. And so, typically, people deal with TensorFlow.

Now if I want to do machine learning on a smaller device, like a smartphone, which has got a much smaller computing capability, if you
Your smartphone is only looking for interesting patterns, for instance. So if that's the case, then you don't want to necessarily use TensorFlow because it's a rather big framework.
What you'd rather have is a smaller, leaner and meaner software framework that is dedicated to just meeting the specific requirements that are needed on a smartphone. For instance, something that takes less memory. Something that has less computational power requirements. Something that only focuses on looking for patterns of data, quote, unquote, "inference." So if I were to put these two systems next to one another head to head, I'm going to start at the ultimate bottom line and work my way upwards since this is the most important point here.

Here we use TensorFlow Lite for that.

So, you can see TensorFlow is basically used for research purpose and innovation whereas TensorFlow Lite has limited capabilities and set for devices which has ram and other constrains.
Responsible AI
With new AI models, we are inviting new threats if we don't design them properly. People may use it for their own use and benefits.

Benefits of TinyML

Issues

Ever wondered how much devastating it will be if tinyml is exposed to your unwanted data?

So, we will do these to solve issues:

Traditional vs Machine Learning
Traditional programming is where you explicitly figure out the rules that act on some data to give an answer like this:

Machine Learning changes this, for scenarios where you may not be able to figure out the rules feasibly, and instead have a computer figure out what they are. That made the diagram look like this:

So for example, you can have the values for x and y that you can see here.
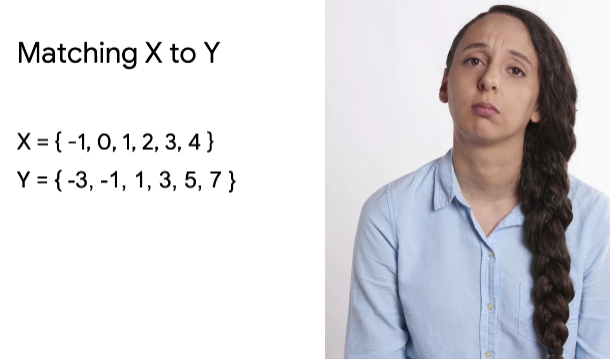
And you want to figure out a way to match x to y. You know that y is a function of x. You just don't know what that function is. So you make a guess.

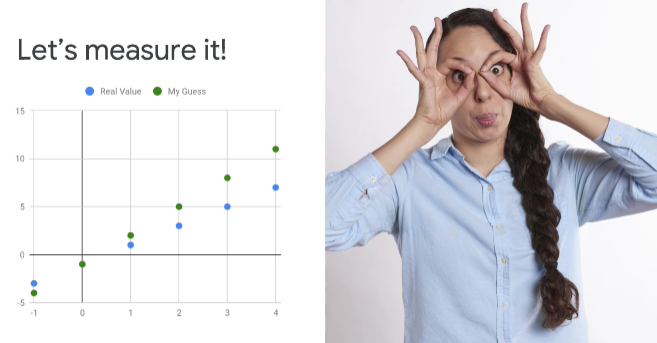
Say you think it's y equals 3x minus 1. It's as good a guess as any. But how do you measure how good or how bad it is? Well, first, we can calculate what y would look like. And you can see that here. Now that we know what y is supposed to look like, I can see my y. And I can see the real y.
They're not the same. In some cases, they're pretty good. The second entry, for example, looks OK to me. And in some cases, they're really bad. And the last entry, where I guessed it would end up 11. But the real value is 7.

Now, is there a way for me to formulize a calculating how goo or how bad these are? Well, maybe I could look for it by plotting them. And here, you can see the real values of y. And you can see my guesses. And by drawing a line between them, I can, by the length of that line, figure out which ones are good and which ones are not so good.
I can measure the length of these lines. So it's minus 1, 0, 1, 2, 3 and 4 for my six points. So if I now remove the chart, I can see these clearly. So maybe, I could add them up to get the overall loss from my guess. But that seems wrong.
Because even though both of these are wrong, they would actually cancel out. And it would look like I actually have three of my six correct,when in fact, I only have one.
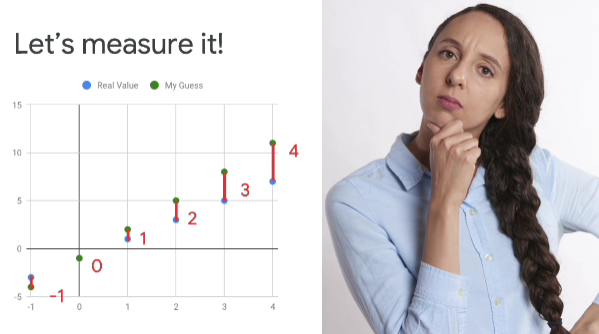


So what if I square them to remove any negatives?

And now, with my losses squared, it looks like this. They're all positive. So I won't have any canceling each other out. And my correct one is still 0. So now, if I total up all of these, I'll get 31. Because I squared them, I can take the square root to get a fair measurement of my error. And as you can see, it's 5.57.

So now, let me repeat that with another guess. What if I guessed that y equals 2x minus 2? Now that I can see that my y is still off the real y, but when I measure the difference and I square that, I get five ones.

If I add them up, I'll get 5. And the square root of that as 2.23.

So my loss is now smaller than it was. And I know I'm heading in the right direction. And if I now guess y equals 2x minus 1, I can calculate my loss as 0. And now, I know I have the right formula to get the right answer. This video just explained loss and how to measure it. Now, of course, the next step should be, how can you use that information to generate the next guess, knowing that the next guess should actually be a better one than the current one? That process, called optimization, will be covered a little later. But first, let's take a look at some code that uses this process.

Here is the code snippet
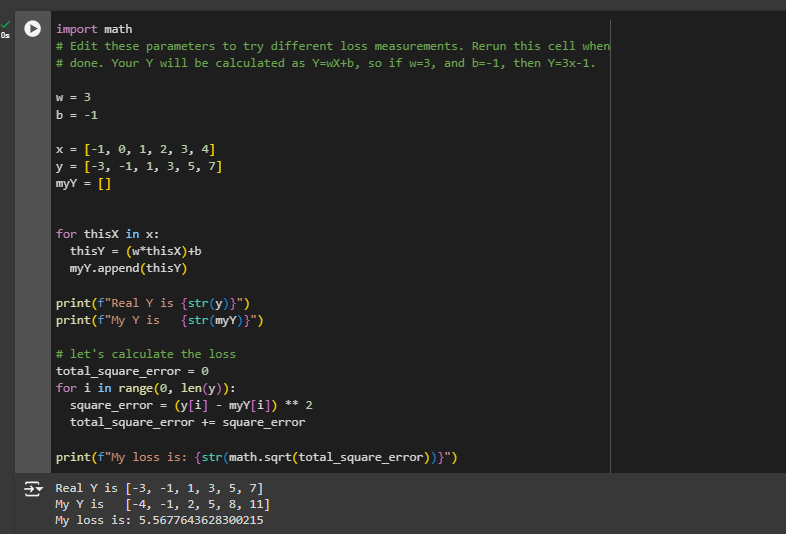
Here is the code
Done!!!
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by