Building a poor man's data lake for Shopify data
 Manuel Schmidbauer
Manuel Schmidbauer
Inspired by a recent blog post, I decided to experiment with various technologies and build a small data lake for Shopify data. In this project, the following technologies are used:
Data Ingestion:dlthub
I use the dlt connector to push data from the Shopify API to a Google Cloud Storage Bucket. Although I will write my own implementation of the Shopify Source, it should work with the verified connector as well.
Data Modelling:dbt
Like many modern data stacks, I use dbt to model the data from the raw layer to the data marts.
Data Orchestration:Prefect
I use Prefect as the data orchestration layer. Both data ingestion and modeling are orchestrated by Prefect deployments.
Data Storage: Google Cloud Storage Bucket
The data is stored as Parquet files in a Google Cloud Storage Bucket.
Data Calculation:DuckDB
I use DuckDB in the dbt project to calculate the different data models. The results of the models are materialized as Parquet files in the Storage Bucket.
SQL IDE:Motherduck
I use Motherduck to query the different Parquet files inside the Google Cloud Storage Bucket.
Architecture:
The graphic below shows the high-level structure of the project. As stated before, the project runs in Google Cloud, with Prefect serving as the orchestration engine.
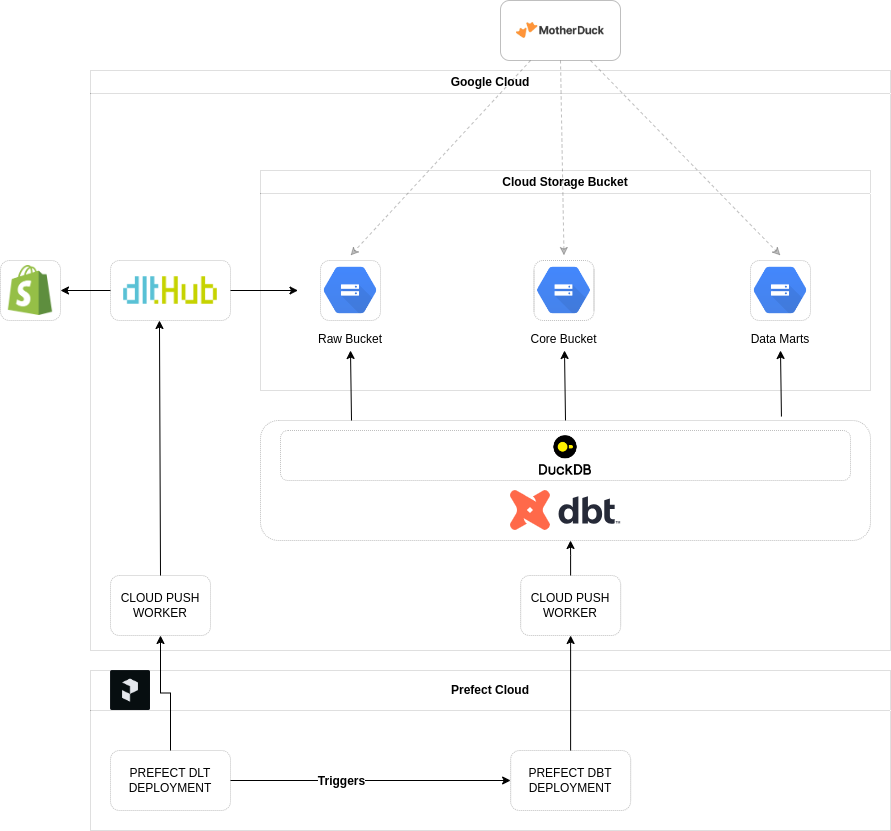
The next articles will provide a deeper dive into the individual components of the project.
Subscribe to my newsletter
Read articles from Manuel Schmidbauer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by