Understanding PaliGemma in 50 minutes or less
 Ritwik Raha
Ritwik Raha
PaliGemma is designed as a versatile model for transfer to a wide range of vision-language tasks such as image and short video caption, visual question answering, text reading, object detection, and object segmentation.
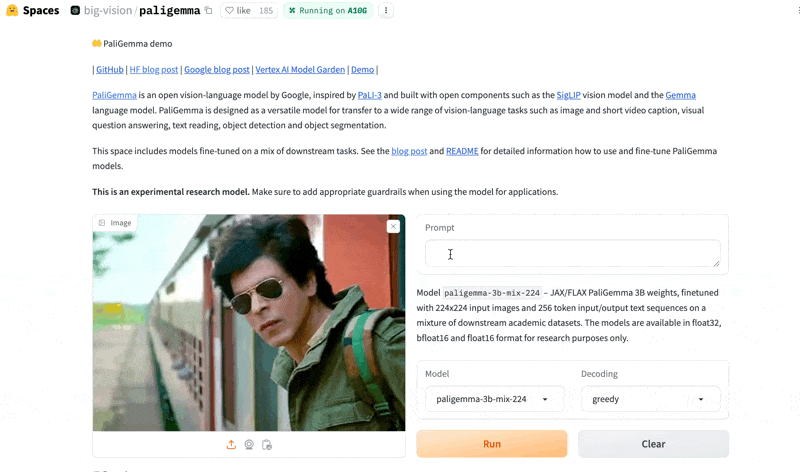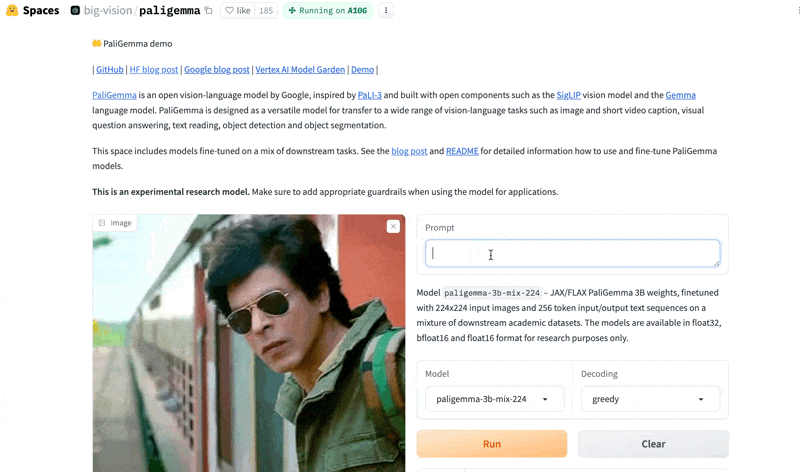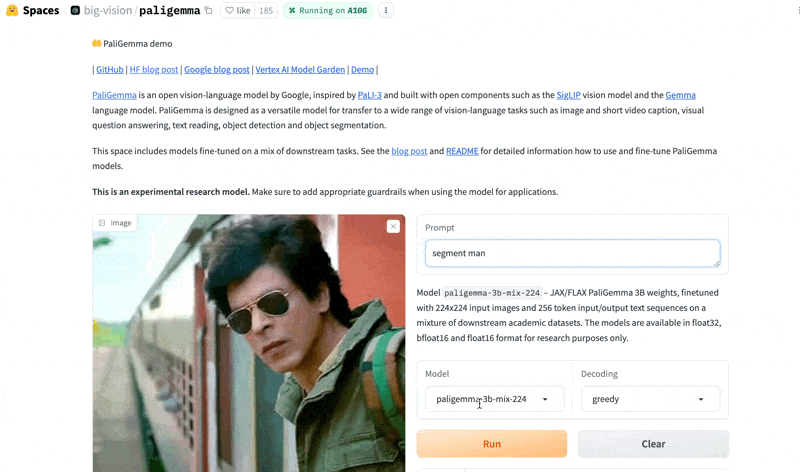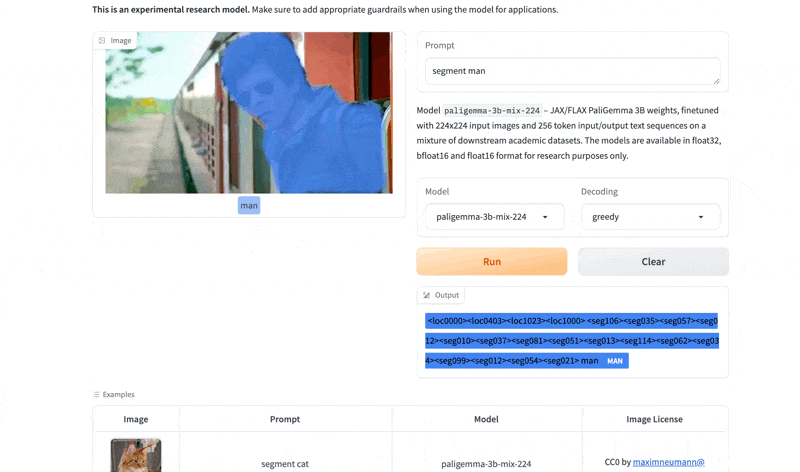
Note of some importance
What is PaliGemma?
PaliGemma is a new family of vision-language models from Google. These models can process both images and text to produce text outputs.
Google has released three types of PaliGemma models:
Pretrained (pt) models: Trained on large datasets without task-specific tuning.
Mix models: A combination of pre-trained and fine-tuned elements.
Fine-tuned (ft) models: Optimized for specific tasks with additional training.
Each type comes in different resolutions and multiple precisions for convenience. All models are available on the Hugging Face Hub with model cards, licenses, and integration with transformers.
"How do I get it running?"
The model comes with simple out-of-the-box usage with Huggingface Transformers. A simple colab notebook is linked here.
from transformers import AutoTokenizer, PaliGemmaForConditionalGeneration, PaliGemmaProcessor
from huggingface_hub import notebook_login
import torch
import numpy as np
from PIL import Image
from matplotlib import pyplot as plt
import requests
input_text = "Who is this person?"
img_url = "https://huggingface.co/datasets/ritwikraha/random-storage/resolve/main/cohen.jpeg"
input_image = Image.open(requests.get(img_url, stream=True).raw)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16)
processor = PaliGemmaProcessor.from_pretrained(model_id)
inputs = processor(text=input_text, images=input_image,
padding="longest", do_convert_rgb=True, return_tensors="pt").to("cuda")
model.to(device)
inputs = inputs.to(dtype=model.dtype)
with torch.no_grad():
output = model.generate(**inputs, max_length=496)
print(processor.decode(output[0], skip_special_tokens=True)
)
"What is the architecture like?"
PaliGemma (GitHub) is a family of vision-language models with an architecture featuring SigLIP-So400m as the image encoder and Gemma-2B as the text decoder.
SigLIP is a state-of-the-art model capable of understanding both images and text. Similar to CLIP, it includes an image and text encoder trained together.
Gemma is a decoder-only model designed for text generation.
But what is SigLIP?
SigLIP introduces a straightforward modification to the widely-used CLIP architecture, as detailed in the paper https://arxiv.org/abs/2303.15343. CLIP's architecture includes an image encoder and a text encoder, both utilizing Transformer-based models.
The pre-training of CLIP employs a contrastive approach to ensure that embeddings of corresponding images and texts are close in the embedding space, while non-matching pairs are positioned far apart. Traditionally, CLIP is trained with a softmax loss function, which necessitates a global view of all pairwise similarities for probability normalization.
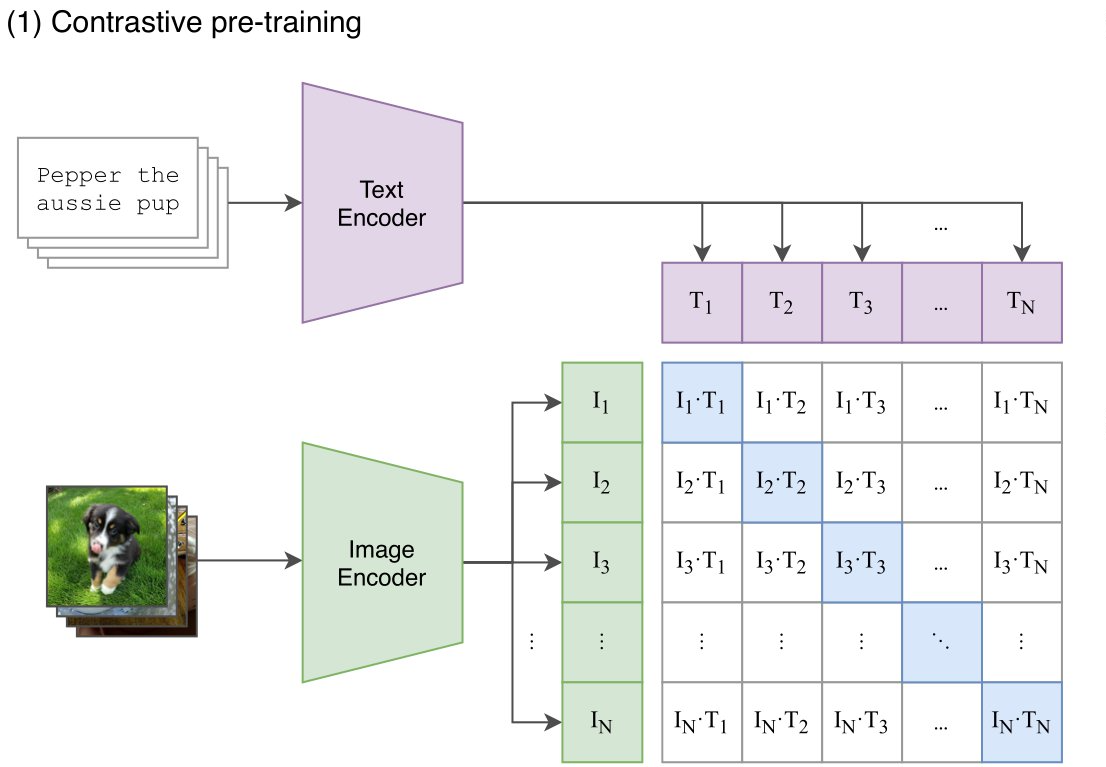
SigLIP simplifies this process by substituting the softmax loss with a sigmoid loss. Unlike softmax, the sigmoid loss does not require a global perspective on pairwise similarities. This modification converts the task into a binary classification problem: determining whether a given image and text pair belong together, with a straightforward yes or no.
But what is Gemma?
Gemma is a family of lightweight, state-of-the-art open models derived from the research and technology that underpinned the creation of Gemini models. These models exhibit robust performance across various academic benchmarks, particularly in language understanding, reasoning, and safety. The Gemma models are available in two sizes, featuring 2 billion and 7 billion parameters, with both pretrained and fine-tuned checkpoints provided.

PaliGemma combines these two components: the image encoder from SigLIP and the text decoder from Gemma, connected through a linear adapter. This combination creates a powerful vision-language model that can be pre-trained on image-text data and fine-tuned for tasks like captioning and referring segmentation.
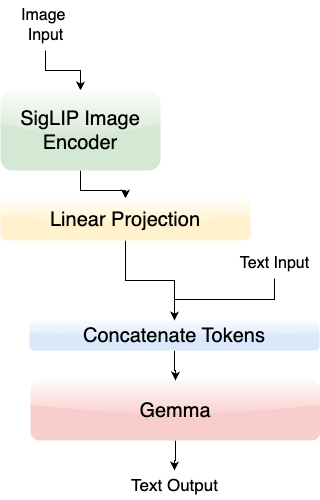
Let us look at the boilerplate code of what this might look like. The actual code is present in the bigvision repository and this is simply a reduced version of that code.
class Model(nn.Module):
"""Two towers transformer for image and text."""
img_model: str = "vit"
img: Optional[ConfigDict] = None
llm_model: str = "proj.paligemma.gemma_bv"
llm: Optional[ConfigDict] = None
def setup(self):
# Initialize LLM and image models
self._llm = importlib.import_module(f"big_vision.models.{self.llm_model}").Model(**(self.llm or {}), name="llm")
img_config = {"num_classes": self._llm.embdim, **(self.img or {})}
self._img_model = importlib.import_module(f"big_vision.models.{self.img_model}").Model(**img_config, name="img")
def embed_image(self, image, train=False):
"""Embeds the input image."""
# Preprocess image and call image model
# Return image embeddings and any auxiliary outputs
pass
def embed_text(self, tokens, train=False):
"""Embeds the input text tokens."""
# Call LLM to embed text tokens
# Return text embeddings and any auxiliary outputs
pass
def embed_image_and_text(self, image, text, input_mask=None, mask_ar=None, train=False):
"""Concatenates image and text embeddings."""
# Embed image and text separately
# Combine embeddings into a single sequence
pass
def __call__(self, image, text, mask_ar, train=False):
"""Processes input image and text and returns logits."""
# Embed image and text
# Create attention mask and call transformer
# Extract and return logits
pass
def prefill_cache(self, x, input_mask, mask_ar, cache_size):
"""Initializes decoding cache with prompt."""
# Initialize cache for decoding
pass
def extend_cache(self, x):
"""Advances decoding cache with new input."""
# Extend cache for decoding
pass
def _fallback_prefill_cache(self, x, input_mask, mask_ar, cache_size):
# Fallback method for initializing cache
pass
def _fallback_extend_cache(self, x):
# Fallback method for extending cache
pass
The above boilerplate code defines a Model class in a PyTorch-like framework, designed to implement a two-tower transformer architecture for vision-language models (VLMs). The model consists of two primary components: an image model (using ViT) and a language model (using a variant of the Gemma model).
The Model class includes methods for embedding images and text, concatenating these embeddings, and processing them together to generate output logits.
Two-Tower Transformer Architecture for VLMs
The two-tower transformer architecture in vision-language models (VLMs) involves separate towers (or networks) for processing images and text, which are later combined for joint tasks. Here's how it works:
Image Embedding Tower:
The image model, specified by
img_model(e.g., ViT), processes input images.The model is initialized with parameters specified in the
imgconfiguration.The
embed_imagemethod preprocesses the image and generates embeddings using the image model.
Text Embedding Tower:
The language model, specified by
llm_model(e.g., Gemma variant), processes input text tokens.The model is initialized with parameters specified in the
llmconfiguration.The
embed_textmethod generates embeddings for text tokens using the language model.
Combining Embeddings:
The
embed_image_and_textmethod separately embeds images and text, then concatenates these embeddings into a single sequence.This combined sequence is used for tasks that require joint image-text understanding.
Processing Inputs:
- The
__call__method processes input images and text, creates an attention mask, and passes the combined embeddings through a transformer to generate output logits.
- The
By leveraging this two-tower approach, the PaliGemma model can effectively learn and utilize the relationships between visual and textual information, which is not wholly indifferent from how a Vision language Model is pre-trained.
As mentioned before the PaliGemma release includes three types of models:
PT checkpoints are pre-trained models that can be further fine-tuned for specific downstream tasks.
Mix checkpoints: These models are pre-trained and then fine-tuned on a mixture of tasks. They are suitable for general-purpose inference with free-text prompts and are intended for research purposes only.
FT checkpoints: These are specialized fine-tuned models, each optimized for a different academic benchmark. They come in various resolutions and are also intended for research purposes only.
PaliGemma Model Sizes
224x224, 448x448, and 896x896. They are also available in three different precisions: bfloat16, float16, and float32. Each model repository contains checkpoints for a specific resolution and task, with three revisions corresponding to the available precisions. The main branch of each repository contains float32 checkpoints, while the bfloat16 and float16 revisions contain the respective precision models.There are separate repositories for models compatible with HuggingFace Transformers and those using the original JAX implementation.
What was the Pretraining like?
PaliGemma is pre-trained on the following mixture of datasets:
Datasets
WebLI (Web Language Image):

A web-scale multilingual image-text dataset sourced from the public web. Various splits of WebLI are used to develop versatile model capabilities such as visual semantic understanding, object localization, visually situated text understanding, and multilingual proficiency.
CC3M-35L:

Curated English image-alt_text pairs from webpages (Sharma et al., 2018). Translated into 34 additional languages using the Google Cloud Translation API.
VQ²A-CC3M-35L/VQG-CC3M-35L:
A subset of VQ2A-CC3M (Changpinyo et al., 2022a), translated into the same 34 languages as CC3M-35L, using the Google Cloud Translation API.OpenImages:

Detection and object-aware questions and answers (Piergiovanni et al. 2022) generated by handcrafted rules on the OpenImages dataset.
WIT:
Images and texts collected from Wikipedia (Srinivasan et al., 2021).
"Wait can I finetune it?"
Fine-Tuning Methods
1. JAX Fine-Tuning Script:
PaliGemma was trained in the
big_visioncodebase, which has also been used for models like BiT, ViT, LiT, CapPa, and SigLIP.The project configuration folder
configs/proj/paligemma/contains aREADME.md.Pretrained models can be transferred using configuration files in the
transfers/subfolder.To transfer your own model, fork
transfers/forkme.pyand follow the instructions in the comments to adapt it to your use case.A Colab notebook,
finetune_paligemma.ipynb, provides a simplified fine-tuning process on a free T4 GPU runtime, updating only the weights in the attention layers (170M parameters) and using SGD instead of Adam.
2. Fine-Tuning with Hugging Face Transformers:
Fine-tuning PaliGemma is straightforward using the
transformerslibrary.Methods such as QLoRA or LoRA fine-tuning can be employed.
An example process involves briefly fine-tuning the decoder, followed by switching to QLoRA fine-tuning.
Ensure to install the latest version of the
transformerslibrary.
3. Fine-Tuning with Vanilla Pytorch script
A small and lean PyTorch script to fine-tune the PaliGemma model
Developed by Aritra Roy Gosthipaty in this repository.
Fine-tune on any dataset containing images and caption pairs.
Training and Model Information
PaliGemma models have been released in various fine-tuned versions by Google.
These models were trained using the
big_visioncodebase, with a history of developing models like BiT, ViT, LiT, CapPa, SigLIP, and more.
Model Performance Table on Fine-tuned Checkpoints
| Model Name | Dataset/Task | Score in Transferred Task |
| paligemma-3b-ft-vqav2-448 | Diagram Understanding | 85.64 Accuracy on VQAV2 |
| paligemma-3b-ft-cococap-448 | COCO Captions | 144.6 CIDEr |
| paligemma-3b-ft-science-qa-448 | Science Question Answering | 95.93 Accuracy on ScienceQA Img subset with no CoT |
| paligemma-3b-ft-refcoco-seg-896 | Understanding References to Specific Objects in Images | 76.94 Mean IoU on refcoco |
| paligemma-3b-ft-rsvqa-hr-224 | Remote Sensing Visual Question Answering | 92.61 Accuracy on test |
Why PaliGemma?
Changing the pretraining strategy and utilizing larger datasets like LAION can significantly enhance PaliGemma's capabilities as a multimodal model for various tasks. Pretraining on vast and diverse datasets improves the model's understanding and generation of nuanced and contextually rich outputs. By scaling the architecture, such as replacing the autoregressive decoder with a more advanced model like Gemini, and training the SigLIP processor on higher-quality, finer-grained images, PaliGemma can achieve superior performance in tasks requiring detailed visual-semantic understanding, precise object localization, and robust multilingual text generation. This will eventually lead to the model becoming more versatile and powerful for a wide range of multimodal applications.
Subscribe to my newsletter
Read articles from Ritwik Raha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by