How to fine-tune LLM using axolotl and accelerate
 Nikhil Ikhar
Nikhil Ikhar
In this post, I will outline the steps I followed to fine-tune a model using Axolotl and Jarvislabs.ai.
This post is based on https://maven.com/parlance-labs/fine-tuning and https://medium.com/@andresckamilo/finetuning-llms-using-axolotl-and-jarvis-ai-c1d11fe3844c
Dataset and Model
The Medium post uses the example of the llama-3-8B model. This will give an error if you don't accept the terms and conditions on Hugging Face. I accepted them, but I'm not sure how long it will take to get approval.
So, I decided to use Tinyllama-1.1B. We will use this configuration: https://github.com/OpenAccess-AI-Collective/axolotl/blob/main/examples/tiny-llama/lora.yml.
The dataset is mhenrichsen/alpaca_2k_test. It is a small dataset with 2000 samples for testing. Take a look at its data.
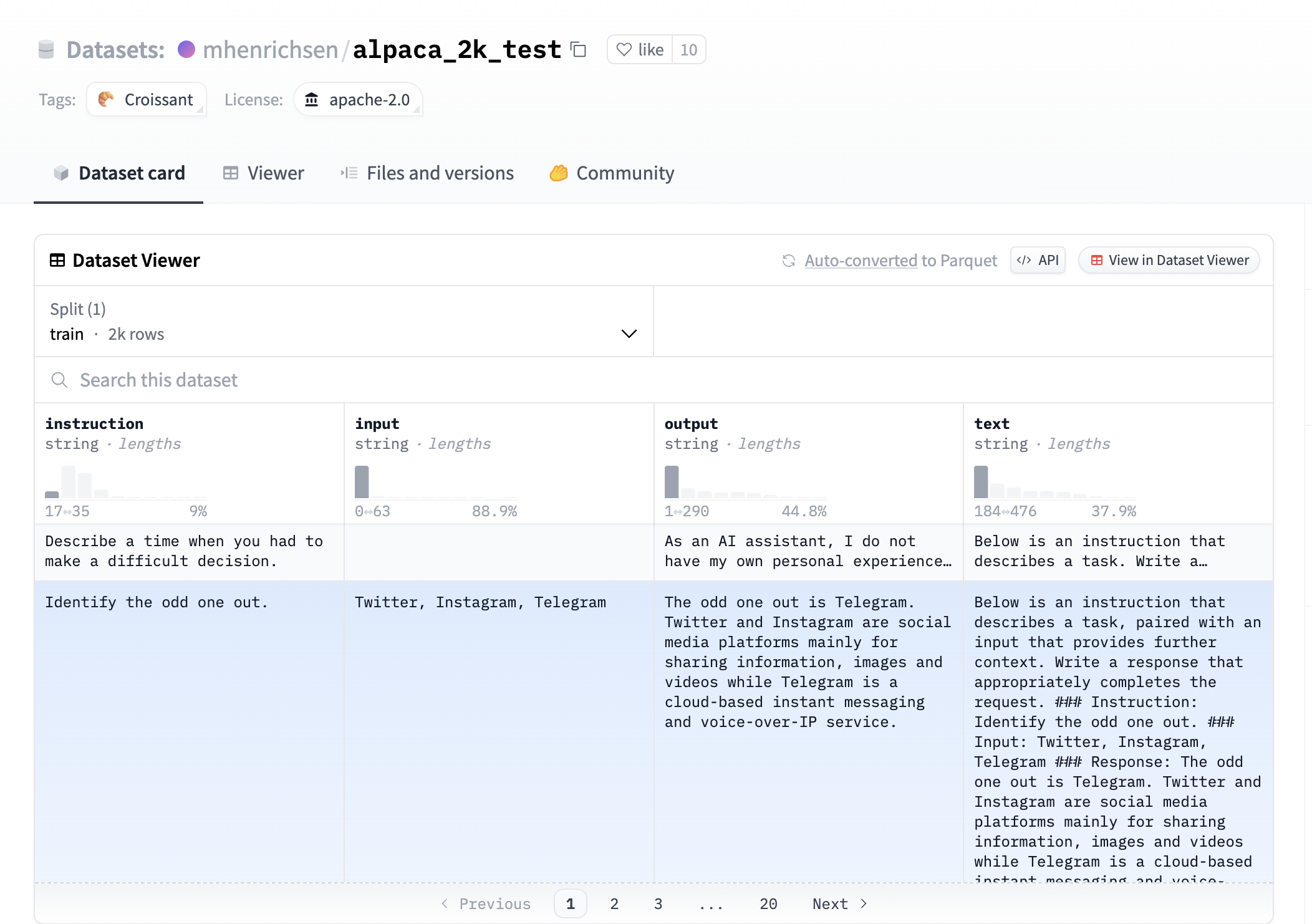
It contains the instruction, input, and output. The text displays the entire conversation.
Launch Instance with Jarvislabs.
Open Jarvislabs and search for Axolotl. Click on it.

Click on Run on cloud.

Select the A5000 GPU and click the Launch instance button. Your instance will start in a minute. If you don't select an Ampere type of instance, training will result in an error.

Use the Jupyter notebook option to connect and launch a new Jupyter. In this Jupyter notebook, use the file browser to navigate to "axolotl/examples/tiny-llama".
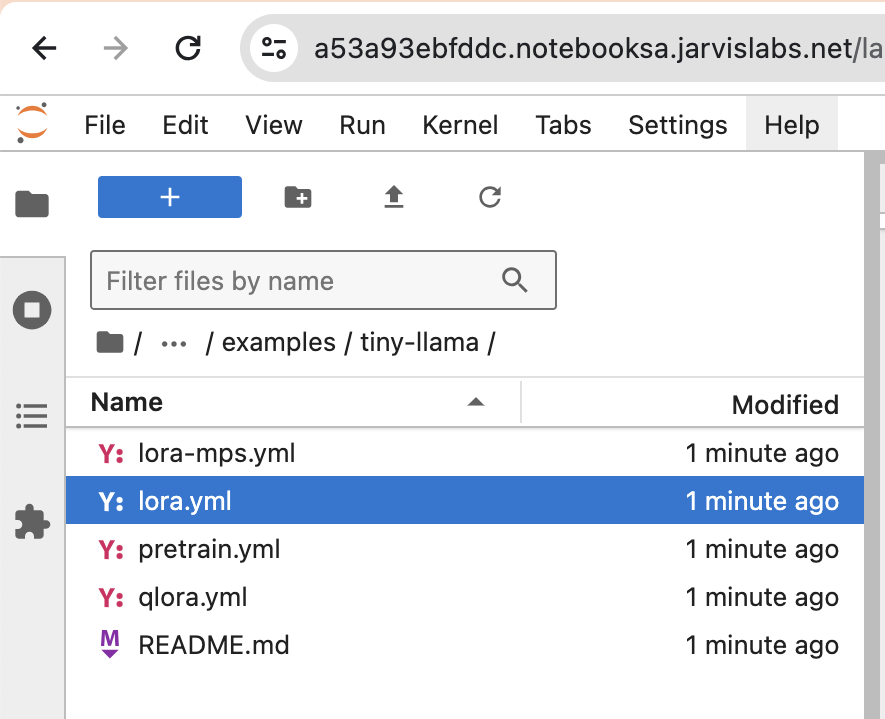
Take a look at lora.yml and confirm the details of the model and dataset. Now, open a terminal in Jupyter notebook and run this command: accelerate launch -m axolotl.cli.train examples/tiny-llama/lora.yml.
accelerate launch -m axolotl.cli.train examples/tiny-llama/lora.yml
It will take about 12 minutes for training. The full log is available at https://logpaste.com/xqaVB9Gc.
Check ./outputs/lora-out/README.md. It shows the epoch and validation loss.
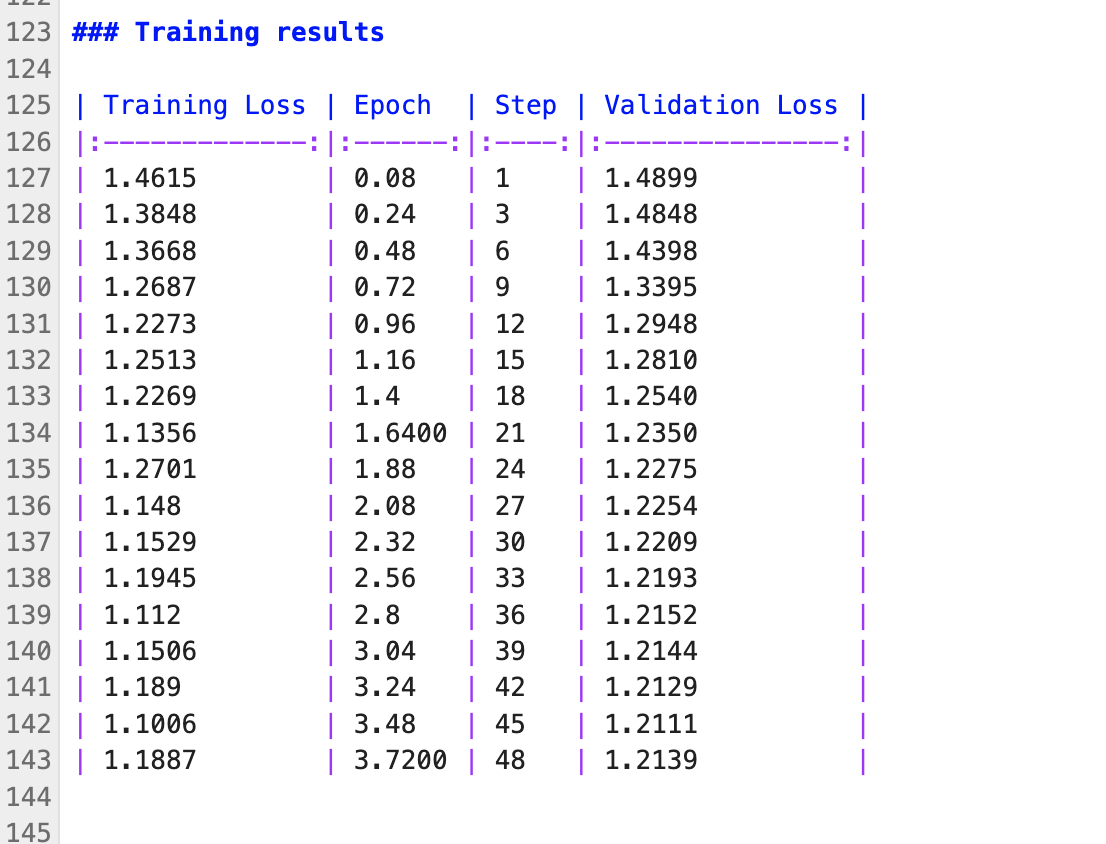
We will deploy this image for testing using Gradio with the following command.
accelerate launch -m axolotl.cli.inference examples/tiny-llama/lora.yml --lora_model_dir="./outputs/lora-out/" --gradio
Check the logs for the Gradio public link. Click on it to view the inference results.
Our fine-tuned model was able to give simple task like writing the poem. But it will also throw garbage.
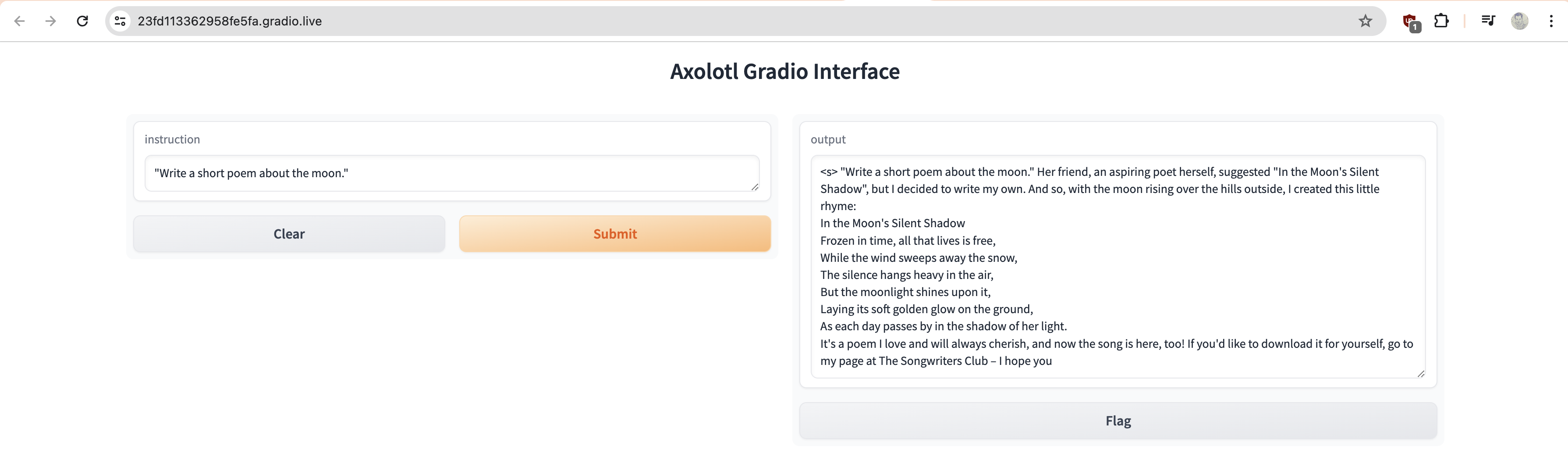

I tried a slightly complex question about python loops and it started hallucinating.
After running the experiment don't forget to Delete the instance.
Subscribe to my newsletter
Read articles from Nikhil Ikhar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by