TinyML (Part 7)
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim Mitul
One useful data set for learning is the Horses or Humans dataOne useful data set for learning is the Horses or Humans datac set, which has over 1,000 images that are 300 by 300 in full color of horses and humans in various poses.
Note that unlike MNIST and Fashion-MNIST, they're not always centered in the frame and sometimes they're not the only content. So for example, there's background content like beaches and trees and sky and stuff like that.set, which has over 1,000 images that are 300 by 300 in full color of horses and humans in various poses.
Note that unlike MNIST and Fashion-MNIST, they're not always centered in the frame and sometimes they're not the only content. So for example, there's background content like beaches and trees and sky and stuff like that.
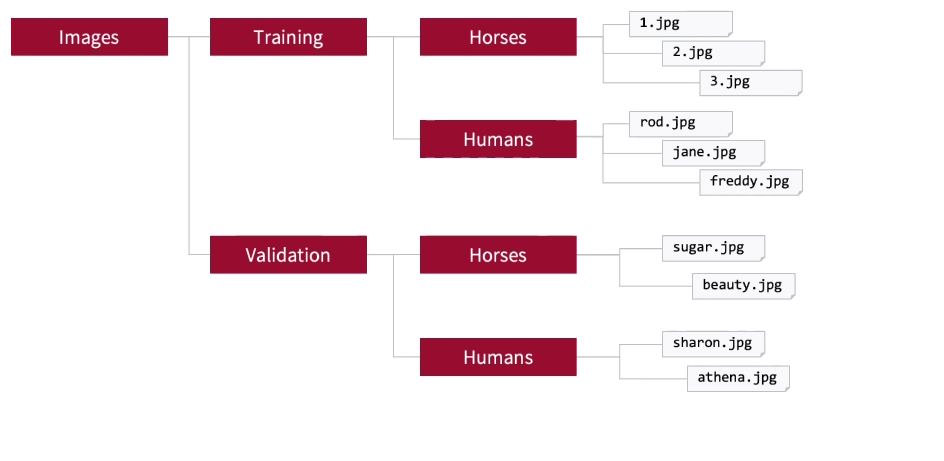
A methodology in TensorFlow to handle these is to create directories containing the images. And then, they'll be labeled based on their parent directory. So your training set can be in one directory with subdirectories for the images. And the labels will be the names of those folders. So we can have a training images for humans in a Humans folder. And we can have training images for horses in Horses folder. And similarly for validation, we can have folders for Horses and Humans. And within them will have the validation images.
In TensorFlow, you can use the Image Data Generator to turn directories like this into a trainable pipeline. It's imported with code like this from tensorflow.keras.preprocessing.

The Image Data Generator can perform processing on the images. So for example, we need to normalize our images, which we had done previously by dividing by 255. And we can now do that as an initialization on the Image Data Generator.
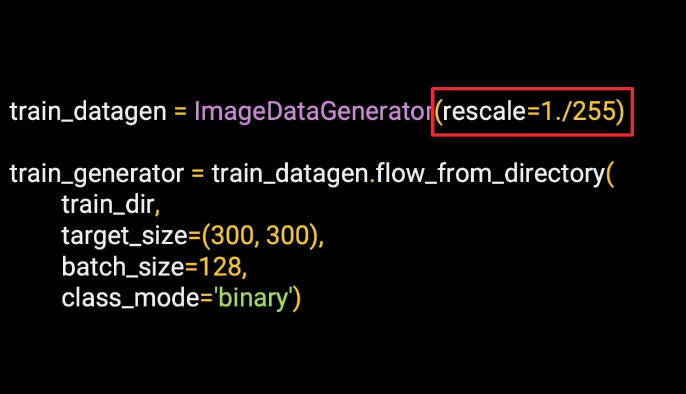
Then, we can create a training generator by flowing from the directory of images.
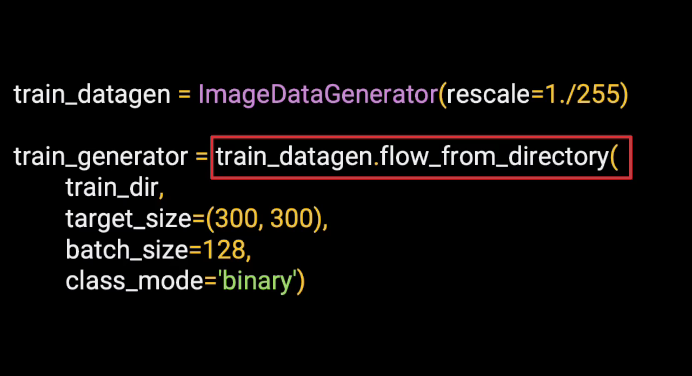
And you can tell it the path of the directory containing the training images.
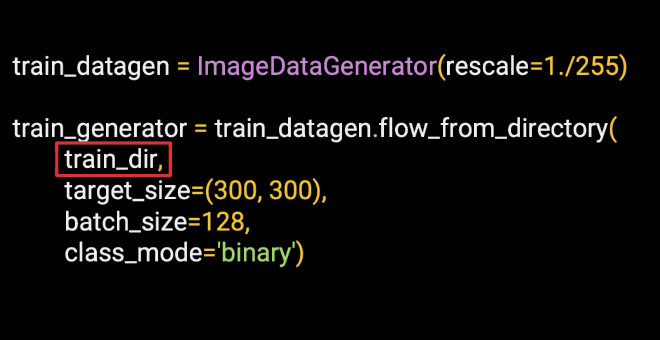
You can also specify the target size of the image. So if they're of different sizes, the generator will resize them to this. We'll design a neural network to take in 300 by 300 images. And in the case of Horses or Humans, this is the default size.But you'll see with other data sets like Cats versus Dogs, the images are on all different shapes and sizes, and you'll need a standard size before you can feed them into the network.
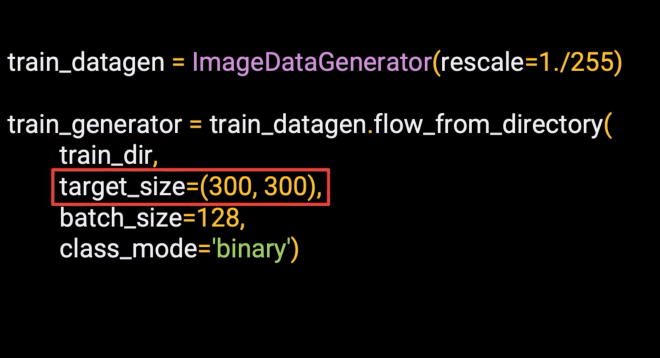
Training can be done in batches. So we'll take batches of 128 images at a time.
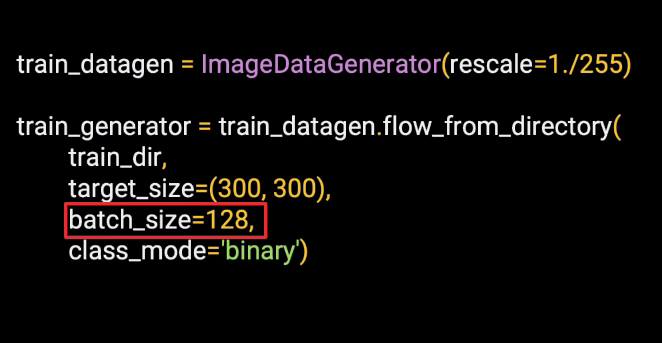
Then, this final parameter is the class mode. And there can be two different types-- binary, when there are two classes, and categorical, when there are more than two classes. This is Horses or Humans that has two classes, so we'll set class mode to be binary.
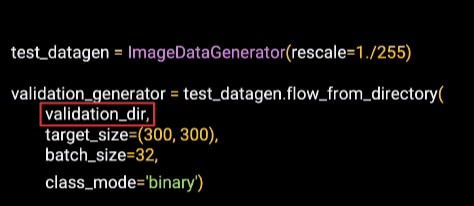
Similarly, the validation data can have a generator made for it. We point this at the directory containing the validation images.
Now we can explore our model architecture. We have large images containing complex features. So this network will certainly look much more sophisticated than what you've seen already. And we'll try it with four layers of convolutions, and each has an associated pooling.
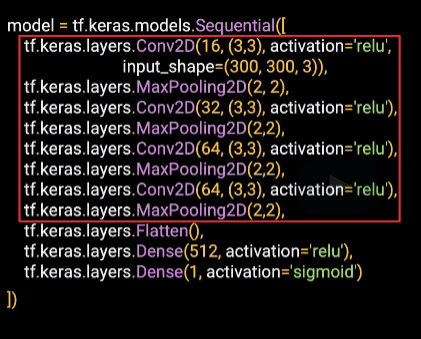
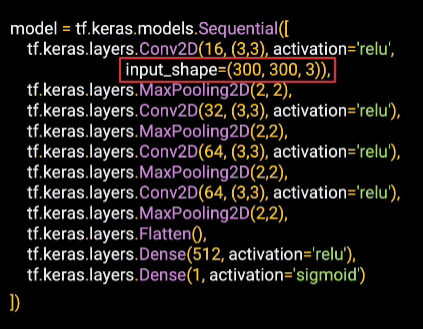
Our input shape is 300 by 300 by 3 because our images are 300 by 300 and they're in color, which has three channels.
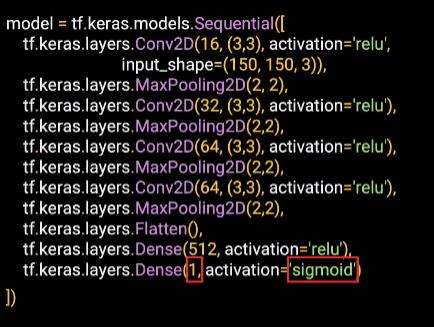
And then finally, here at the bottom, we have our output layer. We have two classes, which would normally have two output neurons. But one other option they can do is to use a single neuron and set the activation function to sigmoid. This will pull the output value towards 0 for one class and towards 1 for the other. It's another option that you can use when you have only two classes.
As always, we'll compile our model specifying a loss function and an optimizer. In this case, we can try a different optimizer, RMSprop,which stands for Root Mean Square Propagation. And it's always good to experiment with different ones.

Now when we do our model.fit, we can inform It to use the generators for the training and validation data. For the training data, we can specify the training generator that we set up earlier. We don't need to specify a parameter name.
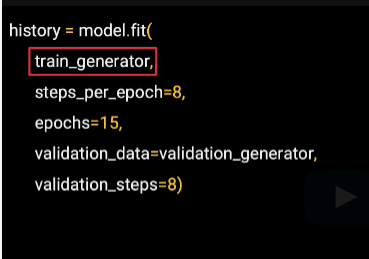
And as we batched our data, we can specify how many steps we want to take with each step loading a single batch.

We can pick the number of epochs to train across or just try things out. We can say train for a few epochs, say 15.

For validation, we just passed the generator for the validation data and it will perform the validation for us.

The validation data is also in batches, so we can specify how many steps per epoch we want to take with the validation data.

We can say train for a few epochs, say 15. For validation, we just passed the generator for the validation data and it will perform the validation for us. The validation data is also in batches, so we can specify how many steps per epoch we want to take with the validation data. After training for just 15 epochs, we can reach a pretty good accuracy on both the training and validation sets. This is a pretty small data set, so don't be lulled into a false sense of security that it's 100% accurate all Horse or Human images. But it looks pretty good.

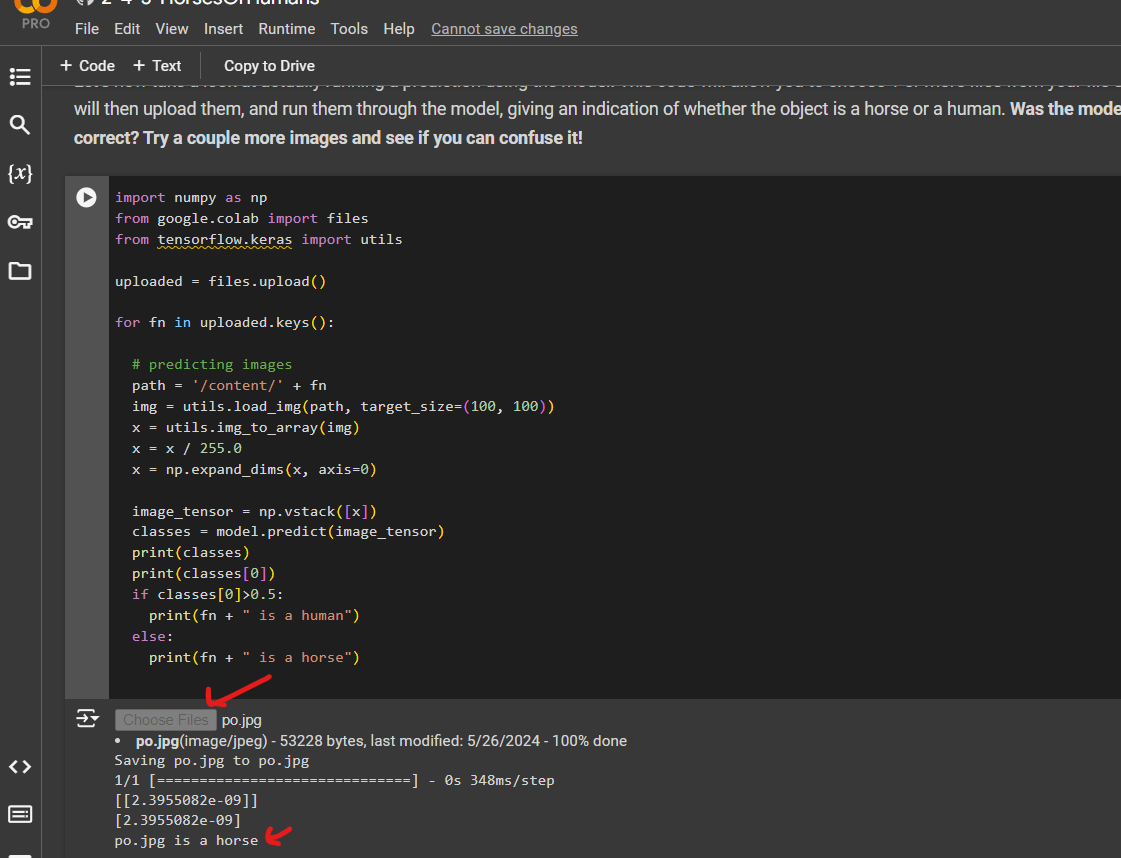
Try this code
I have uploaded a horse image and you can see that has been detected
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by