TinyML (Part 8): Avoiding Overfitting
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulBecause ML can be power hungry, we want to make sure we're as efficient as possible in classifying. And misclassifications, due to overfitting, might really hurt your app. Imagine if the only shoes you had ever seen in your life were hiking boots.

Now, even though hiking boots come in lots of different shapes, and sizes, and colors, and models, by looking at many of them, you'll soon think that all shoes were hiking boots. And then, you could get very good at identifying them. And as you're using the features that make up a hiking.

And as you're using the features that make up a hiking boot to determine that it's a shoe, things like the size or the location within the image wouldn't faze you. You'd have no trouble with an image like this. And you can see that this image definitely has shoes in it.

But then you see a shoe like this. And you don't recognize it as a shoe. Even though it really is one, you've overfed yourself into thinking that all shoes look like hiking boots.

To explore a technique to avoid overfitting, let's consider how convolutional neural networks work. Recall that the spot features in an image, like the ears of a cat, but if you only train on cat images that are upright, then the computer might only recognize ears that are oriented in that way as ears.
So it may not recognize the image on the right as having the ears of a cat. They are oriented differently. Indeed, if your network for spotting cats was only trained on images like this, it might not think the image on the right is a cat.

But what if we rotate the image a little before training. Now, we'll have a labeled image of a cat with ears that look like the cat on the right. So when we train a network with images like the one on the left, we'll better be able to recognize images like the one on the right.
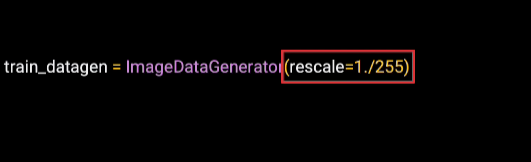
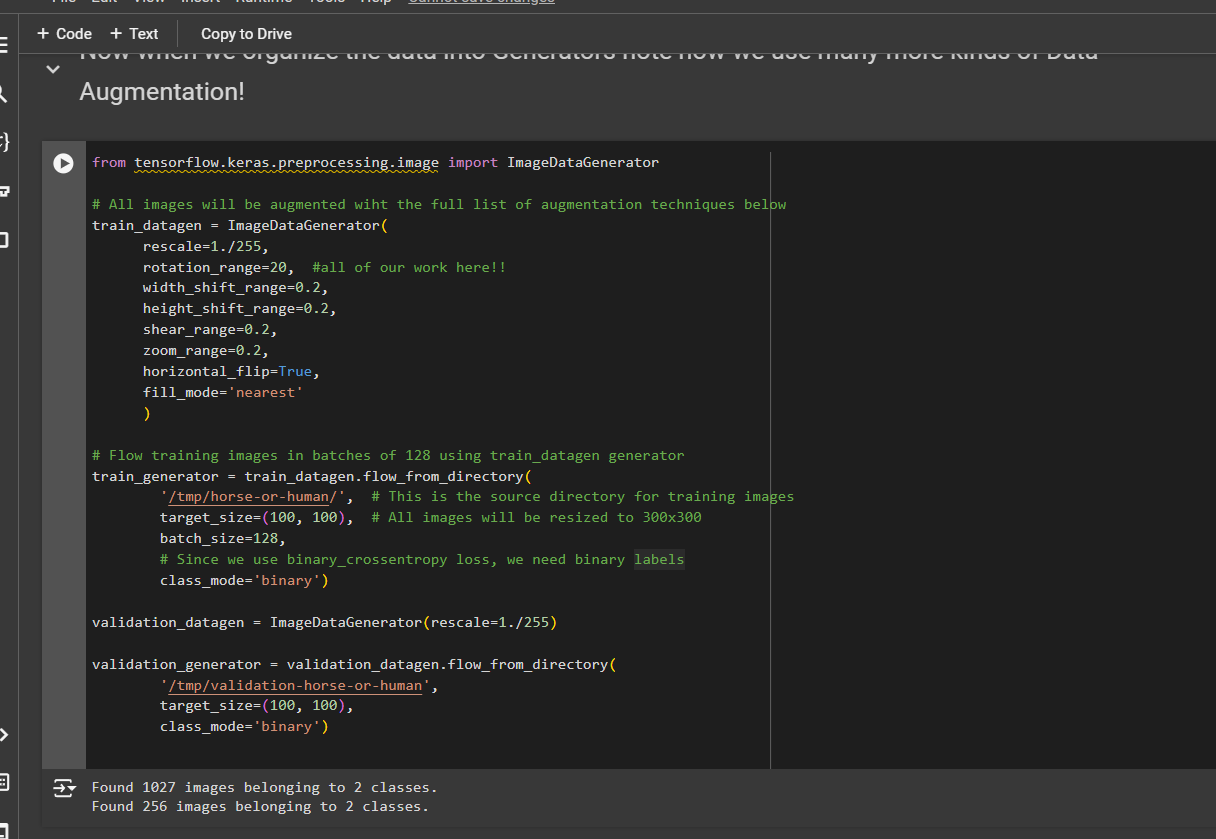
Earlier, we saw the image data generator. And we use it to rescale the image, in order to normalize it. We did this by using a parameter to the image data generator. The good news is there's lots of other parameters we can use.
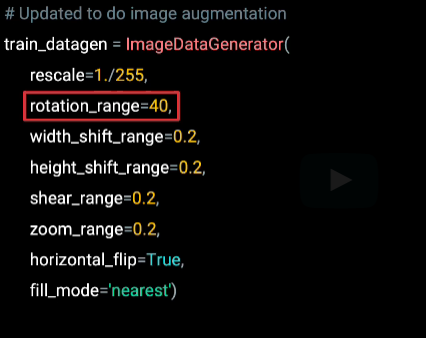
And here's a list of some of them, including rotation range, which will randomly rotate every image up to 40 degrees left or right, as it's read from the file system. By tweaking this parameter, you can impact how much the image is rotated.

Similarly, what if all of our images have the subject in the center of the image, like the training image on the left? It might not recognize the picture on the right as human in the same way. She's much too far to the left in her frame. Now, we can't rely solely on extracting features. Because if the location of the feature is way off, then it might not work.

So shifting images around within the frames when training can help us to prevent overfitting here too.
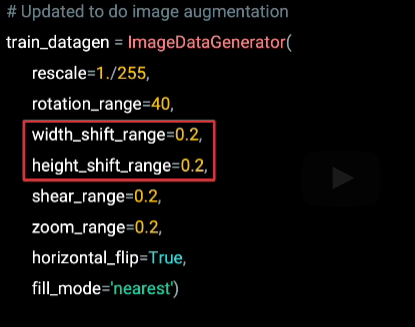
Now, this is achieved using the width shift range and the height shift range parameters. And when set to 0.2 as shown here, the image will be randomly shifted up to 20% on width and height when it is streamed off the desk for training.

Another augmentation that can be done is skewing. This can be useful in a scenario like this one, where the image on the right is clearly a human. But our training data has nothing like it. It does have this image like the one on the left, which is a similar pose. And our human brain recognizes it. But extracted features might miss it.

But if we skew the left image, we now have pixels that look like the right one. And again, we artificially enhance our data set with more scenarios. So hopefully, our neural network will be better at recognizing them.
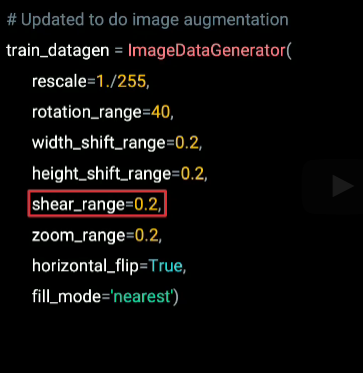
This type of sharing is achieved using the shear range parameter. So we can set it to shear images up to 20% when training by setting it to 0.2

One more scenario was this one. The woman on the right is obviously human. But her legs are not visible in the image. The horses or humans data set has full body poses of each human. And the image on the left looks very like the one on the right. But the classification might fail, because of the missing legs.

But if we zoom in the image on the left, it now looks a lot like the one on the right. So while training, if we had samples that looked like this, the image on the right might classify better in future. Again, we'd avoid overfitting for humans that have legs and avoid mistakenly misclassifying the one without legs as not human.
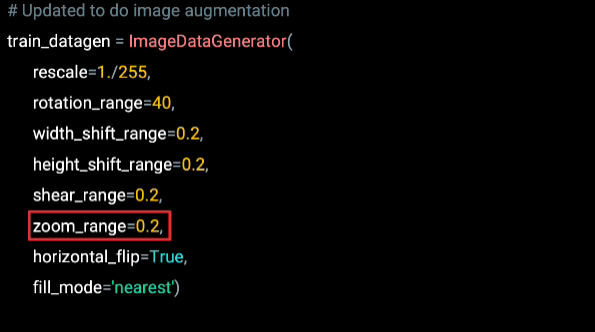
The Zoom range parameter achieves this. By setting it to 0.2, every image will be zoomed up to 20% when training.

And another really obvious one is flipping images. So say our training set only has humans with their right hand raised, like we can see in the image on the left. Then, it might not be able to categorize pictures like the one on the right, where the woman has her left hand raised. Again, we could overfit for right hand raisers mistakenly.

But if we flip the image in our training data, we now have a left hand raiser too. So we can avoid overfitting for this circumstance.
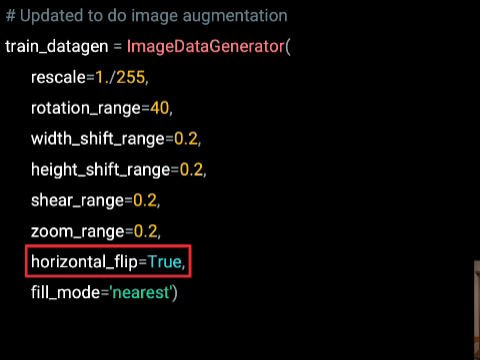
And as before, it's a parameter to the generator. By setting it's true, images will be randomly flipped while training.There's many more parameters to explore. And hopefully this whet your appetite for what's possible
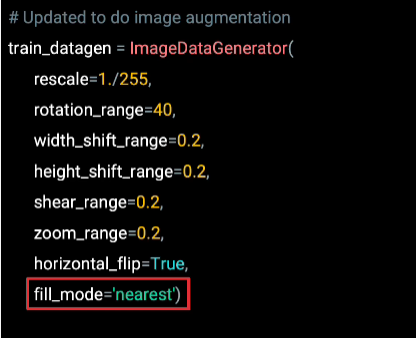
Now, one last thing to consider as the fill mode. This is useful for when the augmentation removes pixels. For example, in the shearing that we saw earlier. And you want to fill those pixels back in. You pick a fill mode for this. And there's a number of different options. I usually use nearest, which picks neighbor pixels and fills the gaps in using them.
Check out the code
Dropout Regularization
You’ve been exploring overfitting, where a network may become too specialized in a particular type of input data and fare poorly on others. One technique to help overcome this is use of dropout regularization
When a neural network is being trained, each individual neuron will have an effect on neurons in subsequent layers. Over time, particularly in larger networks, some neurons can become overspecialized—and that feeds downstream, potentially causing the network as a whole to become overspecialized and leading to overfitting. Additionally, neighboring neurons can end up with similar weights and biases, and if not monitored this can lead the overall model to become overspecialized to the features activated by those neurons.
For example, consider this neural network, where there are layers of 2, 5, 5, and 2 neurons. The neurons in the middle layers might end up with very similar weights and biases.

While training, if you remove a random number of neurons and connections, and ignore them, their contribution to the neurons in the next layer are temporarily blocked

This reduces the chances of the neurons becoming overspecialized. The network will still learn the same number of parameters, but it should be better at generalization—that is, it should be more resilient to different inputs.
The concept of dropouts was proposed by Nitish Srivastava et al. in their 2014 paper “Dropout: A Simple Way to Prevent Neural Networks from Overfitting”.
To implement dropouts in TensorFlow, you can just use a simple Keras layer like this:
tf.keras.layers.Dropout(0.2)
This will drop out at random the specified percentage of neurons (here, 20%) in the specified layer. Note that it may take some experimentation to find the correct percentage for your network.
For a simple example that demonstrates this, consider the Fashion MNIST classifier you explored earlier.
If you change the network definition to have a lot more layers, like this:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
Training this for 20 epochs gave around 94% accuracy on the training set, and about 88.5% on the validation set. This is a sign of potential overfitting.
Introducing dropouts after each dense layer looks like this:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
When this network was trained for the same period on the same data, the accuracy on the training set dropped to about 89.5%. The accuracy on the validation set stayed about the same, at 88.3%. These values are much closer to each other; the introduction of dropouts thus not only demonstrated that overfitting was occurring, but also that adding them can help remove it by ensuring that the network isn’t overspecializing to the training data.
Keep in mind as you design your neural networks that great results on your training set are not always a good thing. This could be a sign of overfitting. Introducing dropouts can help you remove that problem, so that you can optimize your network in other areas without that false sense of security!
Exploring Loss Functions and Optimizers
To this point, you’ve been largely guided through different loss functions and optimizers that you can use when training a network.
It’s good to explore them for yourself, as well as understanding how to declare them in TensorFlow, particularly those that can accept parameters!
Note that there are generally 2 ways that you can declare these functions -- by name, in a string literal, or by object, by defining the class name of the function you want to use.
Here’s an example of doing it by name:
optimizer = 'adam'
And one of doing it using the functional syntax
from tensorflow.keras.optimizers import Adam
opt = Adam(learning_rate=0.001)
optimizer = opt
Using the former method is obviously quicker and easier, and you don’t need any imports, which can be easy to forget, in particular if you’re copying and pasting code from elsewhere! Using the latter has the distinct advantage of letting you set internal hyperparameters, such as the learning rate, giving you more fine-grained control over how your network learns.
You can learn more about the suite of optimizers in TensorFlow at https://www.tensorflow.org/api_docs/python/tf/keras/optimizers -- to this point you’ve seen SGD, RMSProp and Adam, and I’d recommend you read up on what they do. After that, consider reading into some of the others, in particular the enhancements to the Adam algorithm that are available.
Similarly you can learn about the loss functions in TensorFlow at https://www.tensorflow.org/api_docs/python/tf/keras/losses , and to this point you’ve seen Mean Squared Error, Binary CrossEntropy and Categorical CrossEntropy. Read into them to see how they work, and also look into some of the others that are enhancements to these.
Done!
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by