Fine tune Llama 70B using Unsloth, LoRA & Modal as easy as OpenAI ChatGPT
 Lukas
LukasTable of contents
Intro
I came across Modal last summer when I was on a self-inspired mission to run BLOOM 176B model as an open-source competition to ChatGPT.
The guys at modal were amazing and after several days of tinkering after my work, I got it up using 6 GPUs simultaneously. I am not a big fan of Python but it is essentially the only way for ML computing and the way Modal allows to run the code on the cloud is just lovely.
Fun fact, one of the founders is from Stockholm. There's a very interesting podcast where he shares his journey about how internet was back then in Sweden. I don't have link right now but it's worth a search.
Recently I wanted to fine tune gpt 3.5 but my inputs got flagged. I have a big dataset so instead of going through their free moderation API I felt it was the perfect push to try Unsloth. The guys are absolute geniuses that wrote their own kernels.
By the way, Modal gives everyone free 30usd/mon worth of credits so you get plenty of room for trial & error.
Fine tunning Llama 3 70B
The primary audience for Unsloth are everyone running their trials on Google Collab. That is something that I never got too comfortable with, I like the code on my own laptop in my own git repo.
It was a bit of challenge to figure out the right libraries and the base docker image to setup to run the library. Fortunately it didn't take too long diving in their discord to come across the one, and the rest of the code was born.
It took me 10 minutes to fine tune quantized Llama 3 70b 4bit using Modal's H100. I wonder how long it would take had I access to Unsloth's premium code supporting multiple GPUs. Anyway, super nice piece of code. As a developer, I love to have a little code as possible. You're welcome to use it.
Code
Remember to read the part below too.
from datetime import datetime
import secrets
import os
from modal import App, Secret, Image, Volume, gpu
from pathlib import PurePosixPath
HUGGING_FACE_USERNAME = "name"
app = App("unsloth-experiment")
# Volumes for pre-trained models and training runs.
pretrained_volume = Volume.from_name("unsloth-pretrained-vol", create_if_missing=True)
runs_volume = Volume.from_name("unsloth-runs-vol", create_if_missing=True)
VOLUME_CONFIG: dict[str | PurePosixPath, Volume] = {
"/pretrained": pretrained_volume,
"/runs": runs_volume,
}
image = (
Image.from_registry("pytorch/pytorch:2.2.0-cuda12.1-cudnn8-devel")
.apt_install("git")
.pip_install(
"torch==2.2.1",
)
.run_commands(
'pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"',
)
.run_commands(
"pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes",
)
.pip_install("huggingface_hub", "hf-transfer", "wandb")
.env(
dict(
HUGGINGFACE_HUB_CACHE="/pretrained",
HF_HUB_ENABLE_HF_TRANSFER="1",
)
)
)
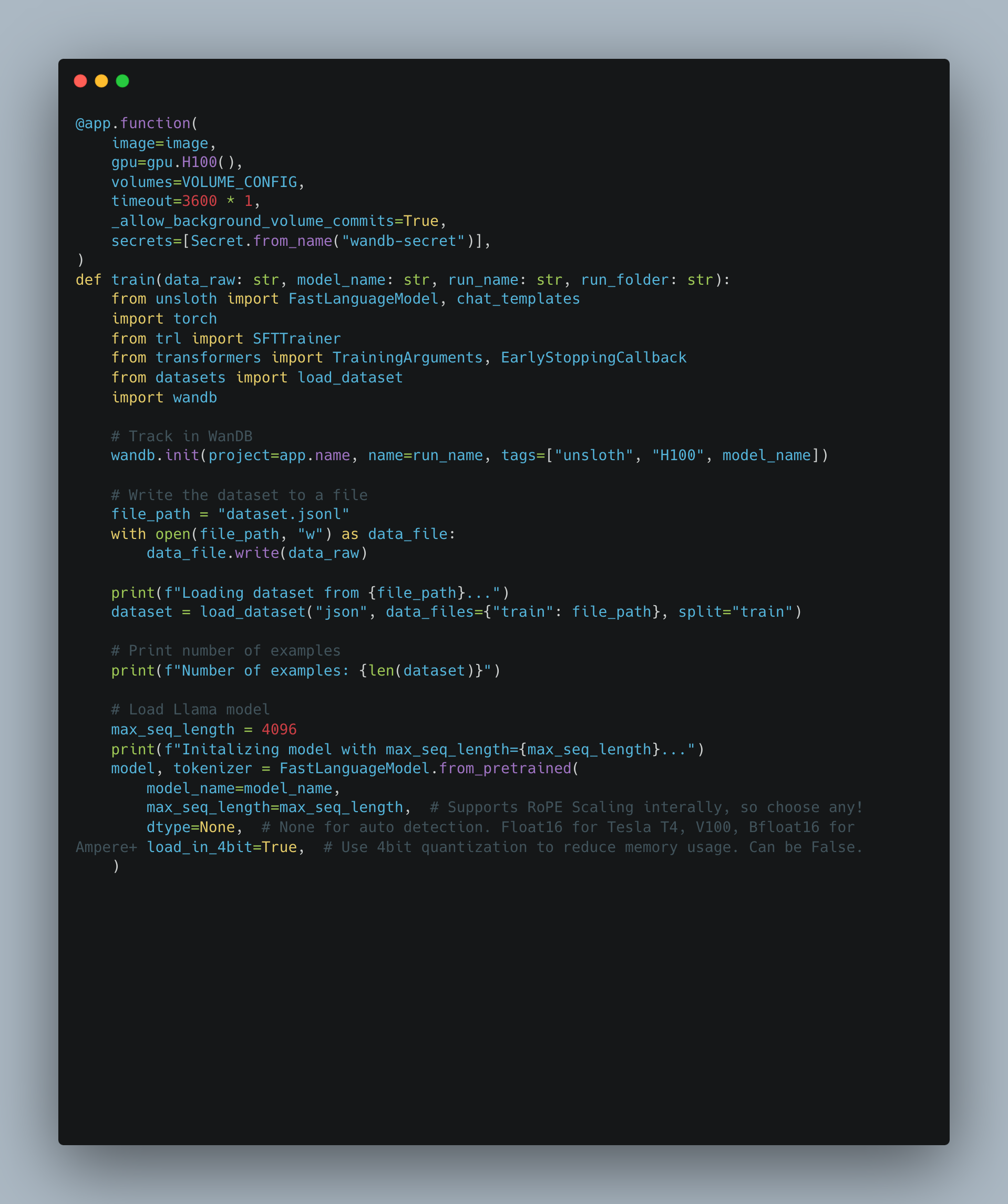
@app.function(
image=image,
gpu=gpu.H100(),
volumes=VOLUME_CONFIG,
timeout=3600 * 1,
_allow_background_volume_commits=True,
secrets=[Secret.from_name("wandb-secret")],
)
def train(data_raw: str, model_name: str, run_name: str, run_folder: str):
from unsloth import FastLanguageModel, chat_templates
import torch
from trl import SFTTrainer
from transformers import TrainingArguments, EarlyStoppingCallback
from datasets import load_dataset
import wandb
# Track in WanDB
wandb.init(project=app.name, name=run_name, tags=["unsloth", "H100", model_name])
# Write the dataset to a file
file_path = "dataset.jsonl"
with open(file_path, "w") as data_file:
data_file.write(data_raw)
print(f"Loading dataset from {file_path}...")
dataset = load_dataset("json", data_files={"train": file_path}, split="train")
# Print number of examples
print(f"Number of examples: {len(dataset)}")
# Load Llama model
max_seq_length = 4096
print(f"Initalizing model with max_seq_length={max_seq_length}...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_seq_length, # Supports RoPE Scaling interally, so choose any!
dtype=None, # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit=True, # Use 4bit quantization to reduce memory usage. Can be False.
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r=16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0, # Supports any, but = 0 is optimized
bias="none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
max_seq_length=max_seq_length,
use_rslora=False, # We support rank stabilized LoRA
loftq_config=None, # And LoftQ
)
# https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2#scrollTo=LjY75GoYUCB8&line=1&uniqifier=1
# ChatML is the default chat template
tokenizer = chat_templates.get_chat_template(tokenizer)
def formatting_prompts_func(entry):
# Example of the payload
# print(entry["messages"])
convos = entry["messages"]
texts = []
for convo in convos:
text = tokenizer.apply_chat_template(
convo, tokenize=False, add_generation_prompt=False
)
texts.append(text)
return {
"text": texts,
}
print(f"Mapping prompts...")
dataset = dataset.map(formatting_prompts_func, batched=True)
# Print number of examples
print(f"Number of examples: {len(dataset)}")
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
warmup_steps=10,
max_steps=30,
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
logging_steps=1,
output_dir=run_folder,
optim="adamw_8bit",
seed=3407,
run_name=run_name,
report_to="wandb",
# load_best_model_at_end=True, # Load the best model in terms of metric at the end of training
# metric_for_best_model="train_loss", # Specify the metric to use for early stopping
# greater_is_better=False, # Specify if higher values are better for the specified metric
),
# callbacks=[
# # Stop training if eval loss does not improve for 3 checkpoints
# EarlyStoppingCallback(3),
# ],
)
print(
f"Starting training run with {torch.cuda.device_count()} {torch.cuda.get_device_name()}"
)
trainer.train()
model.save_pretrained(f"{run_folder}/lora_model") # Local saving
VOLUME_CONFIG["/runs"].commit()
return run_name
@app.function(
image=image,
volumes=VOLUME_CONFIG,
_allow_background_volume_commits=True,
secrets=[Secret.from_name("my-huggingface-secret")],
)
def online(data_raw: str, model_name: str, train_suffic: str):
from huggingface_hub import snapshot_download
# Ensure the base model is downloaded
try:
snapshot_download(model_name, local_files_only=True)
print(f"Volume contains {model_name}.")
except FileNotFoundError:
print(f"Downloading {model_name} ...")
snapshot_download(
model_name,
token=os.environ["HF_TOKEN"],
)
print("Committing /pretrained directory (no progress bar) ...")
VOLUME_CONFIG["/pretrained"].commit()
# Write config and data into a training subfolder.
time_string = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
run_name = f"unsloth-{time_string}"
# if train_suffic is not empty, append it to the run_name
if train_suffic := train_suffic.strip():
run_name += f"-{train_suffic}"
run_folder = f"/runs/{run_name}"
os.makedirs(run_folder)
print(f"Preparing training run in {run_folder}.")
# Start training run.
print("Spawning container for training.")
train_handle = train.spawn(data_raw, model_name, run_name, run_folder)
with open(f"{run_folder}/logs.txt", "w") as f:
msg = f"train: https://modal.com/logs/call/{train_handle.object_id}"
f.write(msg)
print(msg)
VOLUME_CONFIG["/runs"].commit()
return run_name, train_handle
def run_cmd(cmd: str, run_folder: str):
import subprocess
# Ensure volumes contain latest files.
VOLUME_CONFIG["/pretrained"].reload()
VOLUME_CONFIG["/runs"].reload()
# Propagate errors from subprocess.
if exit_code := subprocess.call(cmd.split(), cwd=run_folder):
exit(exit_code)
# Commit writes to volume.
VOLUME_CONFIG["/runs"].commit()
@app.function(
image=image,
volumes=VOLUME_CONFIG,
secrets=[Secret.from_name("huggingface-secret-write")],
)
def upload_to_hf(run_folder: str, name: str):
hf_token = os.environ["HF_TOKEN"]
CMD = f"huggingface-cli upload --token {hf_token} --private {HUGGING_FACE_USERNAME}/{name} lora_model"
# To Hugging Face Hub
run_cmd(CMD, run_folder)
# ToDo: upload to S3 for Predibase
# ChatML dataset
@app.local_entrypoint()
def main(
data: str,
train_suffic: str,
model_name: str = "unsloth/llama-3-70b-bnb-4bit",
):
# Read data file and pass contents to the remote function.
with open(data, "r") as dat:
run_name, train_handle = online.remote(dat.read(), model_name, train_suffic)
# # Write a local reference to the location on the remote volume with the run
with open(".last_run_name", "w") as f:
f.write(run_name)
# Wait for the training run to finish.
train_handle.get()
print(f"Training complete. Run tag: {run_name}")
print(
f"To inspect weights, run `modal volume ls unsloth-runs-vol {run_name}/lora_model`"
)
print(f"Uploading to Hugging Face Hub...")
run_folder = f"/runs/{run_name}"
upload_to_hf.remote(run_folder, run_name)
To use, you will need to set:
huggingface-secret-writeto upload the adapter to Hugging Face, or delete that part of the code.wandb-secretto track the fine tunning progress in WanDB, or delete the code, which I would highly advise against because you really do want to know how it's doing.
Finally prepare OpenAI type of dataset and launch training using the following command: modal run --detach learn.py --data dataset.jsonl --train-suffic cph
Observe the training eval/loss, over fitting and over training yields no value and I haven't had a chance to implement the EarlyStopping yet.
Bonus Tips
For a good fine tunning:
make sure to isolate to a single problem solving, no "do it all" type of stuff;
start with smallest model and then go up;
Mistral 7B and Llama 8B are some of the state-of-art choices available for free;
if you need chat, stick to ChatML template - it will save you a lot of trouble down the road;
prefer base model (not instruct) to have a fresh starting point as possible, or if picking a community tuned model such as Eric Hartford's - make sure you don't mix chat templates (given you train a chat model);
quality of dataset is everything, few shitty examples would ruin as powerful model as GPT 4 and only high quality examples would make small models outperform GPT 4 (search for Predibase adapters case study on this);
Enjoy!
If you end up training something fun, let me know!
Subscribe to my newsletter
Read articles from Lukas directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lukas
Lukas
I've discovered coding back in 2013 and three years later I spent all my summer building my first Laravel app which is still in production by the non-profit I've built for. Now I'm struggling to find the balance between enjoying the power of "I can build this myself" and not chocking myself to death trying to build everything myself. As it is common for developers to be less articulate, I decided to leverage writing about my endeavours, to keep me up.