Demystifying Axolotl Config Files: A Deep Dive into Fine-Tuning Techniques
 Nikhil Ikhar
Nikhil Ikhar
I wrote a previous post about getting familiar with fine-tuning. I got curious about how this setup could get information about the models and dataset. I checked the GitHub repo and documents so you don't have to. Here is what I learned.
I will explain some of the config parameters in this document.
Filename
The example folder in the axolotl library contains different yml files. The names of these yml files, like lora and qlora, show the technique used for fine-tuning an LLM.
LoRA (Low-Rank Adaptation)
In fine-tuning a model, we train the existing model with our training data. Since LLMs are big and training them takes a long time, LoRA is a technique to reduce the time and GPU resources needed to train the model.
Suppose we have an LLM weight matrix (from a specific layer) represented as W, with dimensions N x M (where N is the number of rows and M is the number of columns). We create two additional matrices:
UA(dimensions N x K)UB(dimensions K x M)
Here, K is a small value.
Instead of directly updating the LLM weights, we update the UA and UB matrices. The new weight matrix (let’s call it W’) is created by combining the original weights with the updates: W’ = W + UA · UB.
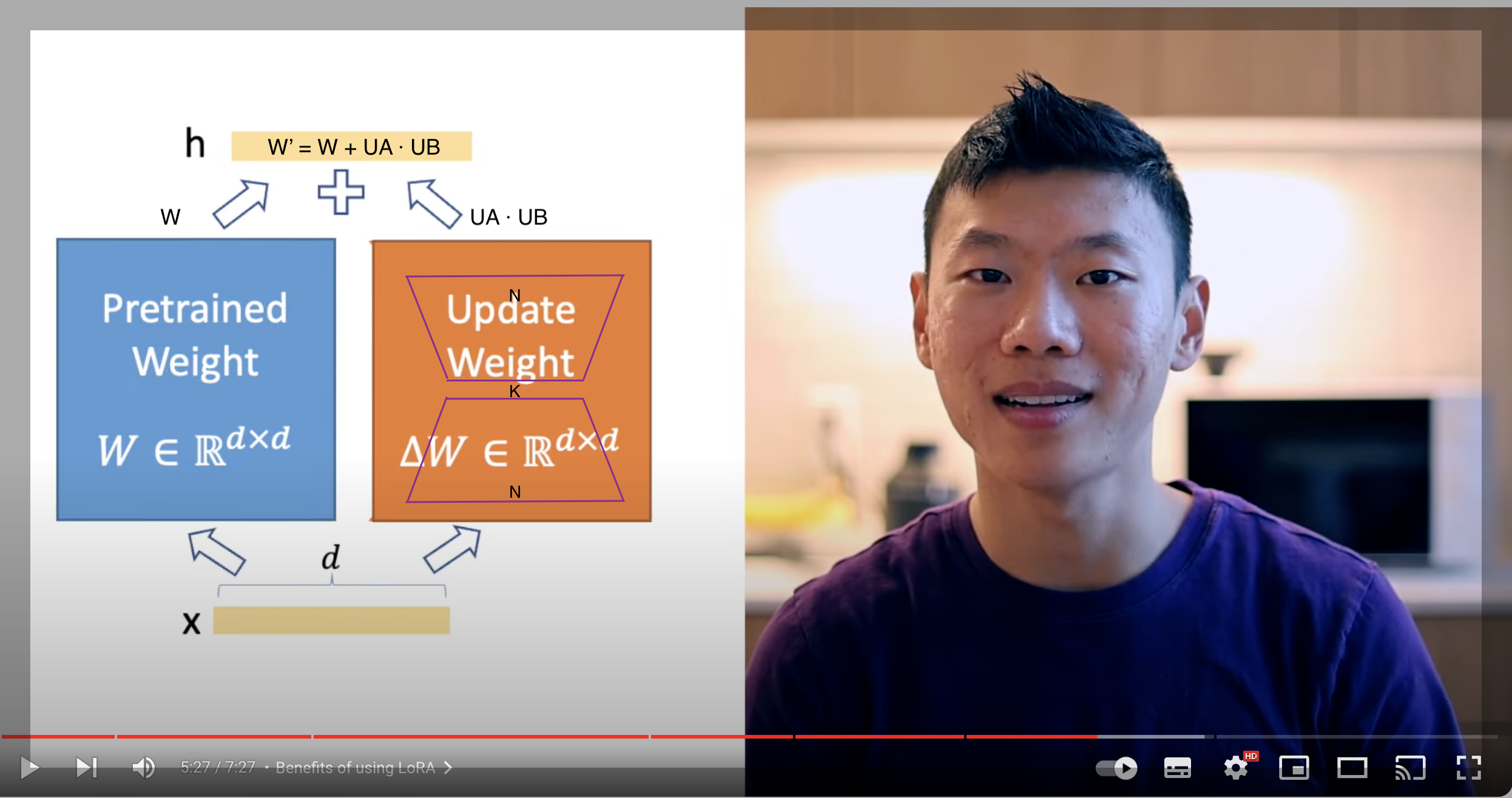
This technique does not increase the inference time. It requires less RAM and VRAM, and it speeds up training. Here is an explanation by the paper author.
QLoRA (Quantized Low-Rank Adaptation)
QLoRA is an improved version of LoRA. Instead of using 8-bit precision for training, it uses 4-bit precision. This makes training more memory efficient. QLoRA manages memory better and can be used when we have less memory.
base_model
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
This shows the name of the base model we want to train. A base model is read using the Transformers (Hugging Face) library. This library provides all the code needed to download the model.
data_set
datasets:
- path: mhenrichsen/alpaca_2k_test
type: alpaca
The Transformers library is used for models and tokenizers, while the datasets library is used for datasets. You can download any available dataset from Hugging Face using this library.
path shows the location inside Hugging Face. type shows the type of prompt used for training..
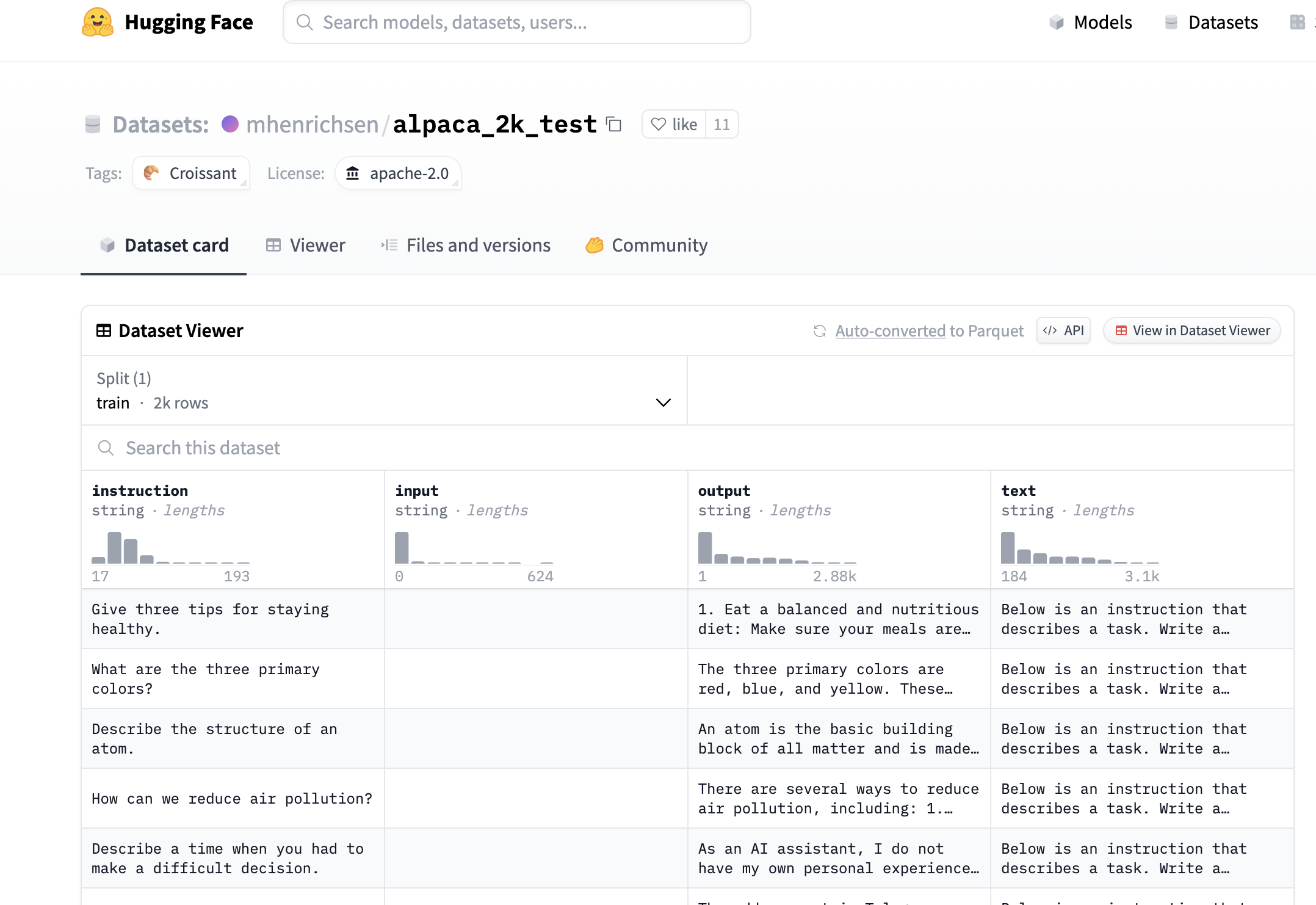
How does the axolotl library know which column to choose? The column names are fixed for each type of prompt. Each dataset object has the column info. We can get this info by,
from datasets import load_dataset
dataset = load_dataset("rotten_tomatoes")
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 8530
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
})
We choose the alpaca prompt, and axolotl will use the instruction, input, and output columns for training. It will ignore the text column. In this config, we don't specify which columns to use.
How do I know this? I searched the code inside and here I found that columns names are hardcoded.
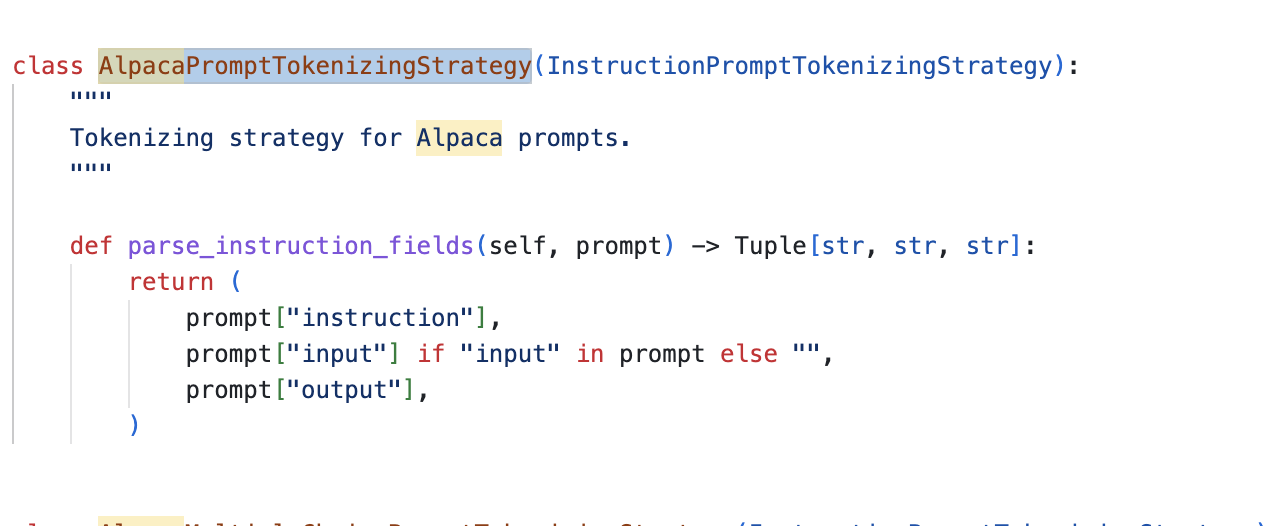
How do I know the type in the dataset? We can tell from the name of the dataset, for example, alpaca is in mhenrichsen/alpaca_2k_test, and sharegpt is in philschmid/guanaco-sharegpt-style.
You can see different types of supported prompts at https://openaccess-ai-collective.github.io/axolotl/docs/dataset-formats/index.html
There are three types of prompts supported by axolotl:
Instruction Tuning: Formats for supervised fine-tuning, such as
alpacaandjeopardy.Conversation: Formats for supervised fine-tuning, such as
sharegpt, where conversations are betweenhumanandgpt.Template-Free
Others
You can see the full list of configurations and their meanings at https://openaccess-ai-collective.github.io/axolotl/docs/config.html
Subscribe to my newsletter
Read articles from Nikhil Ikhar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by